

ʵ�����Ҽ�������Ŀ�Ʋ����Ĵ��С��������,ǰһ��ʱ�俴����ȷ�������PPT������ˮӡ��ô�ǻ������ι��,���ô����˽�Щ���ٴ�����ع淶����ʵ�������������Ҫ��,������û��...��.
˵ʵ��,֮ǰ���ϼ��������������ؿ��з���ʱ��,�Բ�����鶨�IJ����ر���,��ʱ�����̶̹������ﲻ����ͬҪ���IJ�����,������ĸ�overlap,�ĸ�������.����Ҳ����Ϊ���ֱȽϵͶ�,pipeline����,ÿ����ˮ��ʽ���ܽ�100����,�������������ͷ�������˼.
��¼�����м������ʵļ���
ע�������佻����Ⱦ�ĸ��ʽ��
���ȼ���ÿ�μ������,�����Ի������Զ��Ƕ������¼�,��ô
��n������,����ȡ����r��,���ڵ������ n-r+1 ��
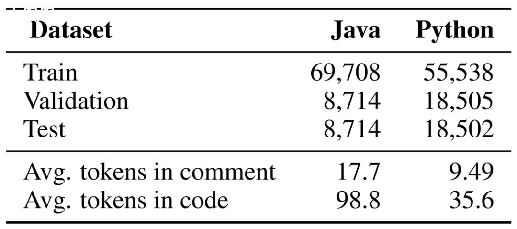
��n������,����ȡ����r��,��������� ��
P=
�ٶ���������Ľ�����Ƕ�����,��ô��r�������������ָ��ʴ���P,��˵��r�����������Խ�����������,��������������Ⱦ��С�����¼���С��ģ�������з�����
��ô,������������ʱ��,�����r�������������ָ���С��P,��ôҲ��˵��r�����������Խ�����ڸ����,��������������������С�����¼��ڴ��ģ���������Բ�������
��������ٴ������������������֤��PPTȫ�ģ�
random.seed()�������ó�ʼֵ,����random.seed(0)�Ǵ�0��ʼ.
random.random() ����������ɴ�0��1�ĸ�����,��0=n=1.0.
"_" ��ռλ��,��ʾ�����������ֵ,����ѭ��n��.
�ڶ��Σ���װpython�Ŀ�ѧ�����scipy
��python�Ŀ�ѧ�����scipy��statsģ�������������ʷֲ��ĸ���ֵ,����matplotlib�����л�ͼ.
��notebook�����°�װ��ѧ�����scipy.����Ѱ�װ�������氲װ����.
��װ���裺
��.)���ն�Anaconda Prompt
�����û�а�װnumpy����matplotlib��,Ҳ���������װ��Щ��
����������X������ȡֵ����������оٳ���,���XΪ��ɢ���������.��Ӧ�ĸ��ʷֲ��ж���ֲ�,���ɷֲ�.
����������X������ȡֵ������оٳ���,����ȡ������ijһ�����ڵ���һ��,���XΪ�������������.��Ӧ�ĸ��ʷֲ�����̬�ֲ�,���ȷֲ�,ָ���ֲ�,٤���ֲ�,ƫ̬�ֲ�,�����ֲ�,beta�ֲ���.(���ֲ�,�ÿֲ�~~)
����ֵҲ���Ǹ������������ľ�ֵ. �Ƶ��������£�
0-1�ֲ�������ֲ���,�������������ȡֵΪ1��0.����ɢ���������X�ĸ��ʷֲ�Ϊ��P{X=0} = 1-p, P{X=1} = p,����
����������X���Ӳ���Ϊp��0-1�ֲ�,����X~B��1,p).
���������кܶ����ӷ�������ֲ�,����Ͷ���Ƿ��б�,����Ӥ�����к�����Ů��,����Ʒ�Ƿ�ϸ�ȵ�.
��ҷdz���Ϥ����Ӳ�������Ӧ�ķֲ����Ƕ���ֲ�.��Ӳ������Ҫô��������,Ҫô���Ƿ���,ֻ�������������.��������Ĵ�����һ���������,����������������ӵĸ��ʷֲ�ͨ����Ϊ ����ֲ� .
����Ӳ���������������еĹ�ͬ�����ܽ����£�������Ӳ��Ϊ����
ͨ���ƾ�������������n���ظ���������Ϊn�ز�Ŭ������.��Ʋ�Ŭ�������Ŭ���������.�ر��,���������Ϊ1ʱ,����ֲ�����0-1�ֲ�(����ֲ�).
����ֲ�������ֵ�ͷ��� �ֱ�Ϊ��
���ɷֲ�������������һ ָ��ʱ�䷶Χ�ڻ���ָ������������֮��ijһ�¼����ֵĴ����ķֲ� .�����з��Ӳ��ɷֲ������ӱ�����ÿ�췿���н�Ӵ��Ŀͻ���,ij��ÿ�³��ַ�����̱���Ĵ����ȵ�. ���ɷֲ��Ĺ�ʽΪ ��
���ɷֲ�������ֵ�ͷ��� �ֱ�Ϊ��
ʹ��Python���Ʋ��ɷֲ��ĸ��ʷֲ�ͼ��
��Ϊ�����������������ȡijһ���������ʵ�����ϵ�����һ��ֵ,����ͨ����һ������f(x)����ʾ�������������,��f(x)�ͳ�Ϊ �����ܶȺ��� .
�����ܶȺ���f(x)������������ ��
��Ҫע�����,f(x)����һ������,��f(x) �� P(X = x) .�������ֲ��������,�������X��a��b֮��ĸ��ʿ���д�ɣ�
��̬�ֲ��Ķ��� ��
����������X�ĸ����ܶ�Ϊ( -+x++)��
��̬�ֲ���ͼ���ص� ��
ʹ��Python������̬�ֲ��ĸ��ʷֲ�ͼ��
��u=0,q=1ʱ,��
��ʱ����̬�ֲ�N(0,1) ��Ϊ����̬�ֲ�.��Ϊu,q����ȷ����ȡֵ,�������Ӧ�ĸ����ܶ�������һ�� ��̬�̶� ������.
�Ա���̬�ֲ�,ͨ����+(x)��ʾ�����ܶȺ���,��+(x)��ʾ�ֲ�������
�� ���������X�ȼ�ȥ����������ֵ,�ٳ���������������͵õ���������.���X����ƽ��ֵ,��ZΪ����,��֮Ϊ���� .ͨ�����������,���Խ��κ�һ��һ�����̬�ֲ�ת��Ϊ����̬�ֲ�.
�Ӽ���������,˵����ο���С���������ɼ���ȫ��ͬѧ�����ǿ��úܲ�����,�����Ŀ��úܲ�.
ָ���ֲ���������ǰ��IJ��ɷֲ�����,���ɷֲ�ǿ������ij��ʱ��������¼������Ĵ����ĸ��ʷֲ�,��ָ���ֲ�˵���� ����¼�������ʱ���� �ĸ��ʷֲ�.����һ�������վ�ļ��ʱ��.����������X�ĸ����ܶ�Ϊ��
���X����ָ���ֲ�,���еIJ���+0. ��Ӧ�ķֲ����� Ϊ��
���ȷֲ�������ֵ�ͷ��� �ֱ�Ϊ��
ʹ��Python����ָ���ֲ��ĸ��ʷֲ�ͼ��
���������������X���и����ܶȺ�����
���X��������(a,b)�ϵľ��ȷֲ�.X�ڵȳ��ȵ���������ȡֵ�ĸ�����ͬ.��Ӧ�ķֲ�����Ϊ��
f(x)��F(x)��ͼ�ηֱ�����ͼ��ʾ��
Python �C ��������
��ҳ�������¹۵��붯̬����֪ʶϵ�н̳�ʵ����Ŀ�������ܹ�����ԴPythonС�鲮������ Python - �������� �������� ʵ����Ŀ �����Python��ʵ��������ǿ��ĸ��ʷֲ������Python��ʵ��������ǿ��ĸ��ʷֲ�
Ӣ�ij�����.��ӭ���뷭����.
R��������Ѿ���Ϊͳ�Ʒ����е���ʵ��.������ƪ������,�ҽ���������Python��ʵ��ͳ��ѧ��������������.��Ҫʹ��Pythonʵ��һЩ��ɢ�������ĸ��ʷֲ�.��Ȼ�Ҳ���������Щ�ֲ�����ѧϸ��,���һ������ӵķ�ʽ����һЩѧϰ��Щͳ��ѧ����ĺ�����.��������Щ���ʷֲ�֮ǰ,�����˵˵ʲô�����������random variable��.��������Ƕ�һ��������������.
�ٸ�����,һ����ʾ��Ӳ�ҽ��������������Ա�ʾ��Python
X = {1 ������泯��,
���������һ������,��ȡֵ��һ����ܵ�ֵ����ɢ�������ģ�,������ij�������.���������ÿ������ȡֵ�Ķ���һ�����������.������������п���ȡֵ����֮������ĸ��ʾͱ���Ϊ���ʷֲ���probability distributrion��.
�ҹ��������ϸ�о�һ��scipy.statsģ��.
���ʷֲ����������ͣ���ɢ��discrete�����ʷֲ���������continuous�����ʷֲ�.
��ɢ���ʷֲ�Ҳ��Ϊ��������������probability mass function��.��ɢ���ʷֲ��������в�Ŭ���ֲ���Bernoulli distribution��������ֲ���binomial distribution�������ɷֲ���Poisson distribution���ͼ��ηֲ���geometric distribution����.
�������ʷֲ�Ҳ��Ϊ�����ܶȺ�����probability density function��,�����Ǿ�������ȡֵ������һ��ʵ���ϵ�ֵ���ĺ���.��̬�ֲ���normal distribution����ָ���ֲ���exponential distribution����b�ֲ���beta distribution���ȶ������������ʷֲ�.
�����˽���������ɢ���������������֪ʶ,����Թۿ��ɺ�ѧԺ���ڸ��ʷֲ�����Ƶ.
����ֲ���Binomial Distribution��
���Ӷ���ֲ����������X��ʾ��n����������/�������гɹ��Ĵ���,����ÿ������ijɹ�����Ϊp.
E(X) = np, Var(X) = np(1?p)
�������֪��ÿ��������ԭ��,�������IPython�ʼDZ���ʹ��help file����. E(X)��ʾ�ֲ���������ƽ��ֵ.
����stats.binom?�˽����ֲ�����binom�ĸ�����Ϣ.
����ֲ������ӣ�����10��Ӳ��,ǡ���������泯�ϵĸ����Ƕ���?
������ʹ��.rvs����ģ��һ�������������,���в���sizeָ����Ҫ����ģ��Ĵ���.����Python����10000������Ϊn��p�Ķ���ʽ�������.�ҽ������Щ���������ƽ��ֵ�ͱ���,Ȼ�����е����������ֱ��ͼ.
���ɷֲ���Poisson Distribution��
һ�����Ӳ��ɷֲ����������X,��ʾ�ھ��б��ʲ�����rate parameter��+��һ�ι̶�ʱ������,�¼������Ĵ���.����+��������¼������ı���.�������X��ƽ��ֵ�ͷ����+.
E(X) = +, Var(X) = +
����Կ���,�¹ʴ����ķ�ֵ�ھ�ֵ����.ƽ����˵,�����Ԥ���¼������Ĵ���Ϊ+.���Բ�ͬ��+��n��ֵ,Ȼ���ֲ�����״����ô�仯��.
��������ģ��1000�����Ӳ��ɷֲ����������.
��̬�ֲ���Normal Distribution��
��̬�ֲ���ȡֵ���ԴӸ����������.�����ע�,����stats.norm.pdf�õ���̬�ֲ��ĸ����ܶȺ���.
b�ֲ���Beta Distribution��
b�ֲ���һ��ȡֵ�� [0, 1] ֮��������ֲ�,����������̬����a��b��ȡֵ���̻�.
b�ֲ�����״ȡ����a��b��ֵ.��Ҷ˹�����д���ʹ����b�ֲ�.
���㽫����a��b������Ϊ1ʱ,�÷ֲ��ֱ���Ϊ���ȷֲ���uniform distribution��.���Բ�ͬ��a��bȡֵ,�����ֲ�����״����α仯��.
ָ���ֲ���Exponential Distribution��
ָ���ֲ���һ���������ʷֲ�,���ڱ�ʾ��������¼�������ʱ����.�����ÿͽ��������ʱ����������ͷ����ĵ绰��ʱ����������ά���ٿ�����Ŀ���ֵ�ʱ�����ȵ�.
����,����ָ���ֲ���ģ��1000���������.scale������ʾ+�ĵ���.����np.std��,����ddof���ڱ�ƫ����� $n-1$ ��ֵ.
���Conclusion��
���ʷֲ�����Ƿ��ӵ���ͼ,����������Ƕ������¼����ܽ�.�ҽ�����ȥ���������ѧ���ݿ�ѧ�γ̵Ľ���,Joe Blitzstein���ڸ���һ��ժҪ,������������Ҫ�˽�Ĺ���ͳ��ģ�ͺͷֲ���ȫ��.
���Ͼ������¸�С��Ϊ���������python�к�����������������,���������С����µ�����ֻҪ�ܶԷ�˿������,�����������Ĺ����Ͷ���,��Ҫ���ǽ���վ�����������ߵ�����Ŷ����