

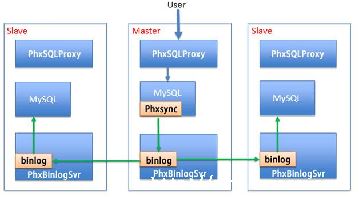
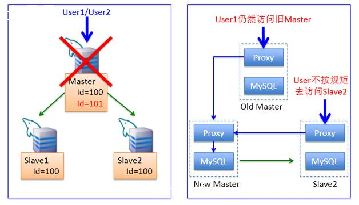
所谓的Dual Master,实际上就是两台MySQL服务器互相将对方作为自己的 Master,自己作为对方的Slave,这样任何一台服务器上的数据变更,都会通过MySQL 的复制机制同步到另一台服务器.当然,有的读者可能会担心,这样不会导致两台互为Master 的 MySQL之间循环复制吗?当然不会,这是由于MySQL在记录Binary log日志时,记录了当前的server-id, server-id在我们配置MySQL复制时就已经设置好了.一旦有了server-id,MySQL就很容易判断最初的写入是在哪台服务器上发生的,MySQL不会将复制所产生的变更记录到Binary log,这样就避免了服务器间数据的循环复制.当然,我们搭建Dual-Master 架构,并不是为了让两个 Master 能够同时提供写入服务,这样会导致很多问题.举例来说,假如Master A 与Master B几乎同时对一条数据进行了更新,对Master A的更新比对Master B的更新早,当对Master A的更新最终被同步到Master B时,老版本的数据将会把版本更新的数据覆盖,并且不会抛出任何异常,从而导致数据不一致的现象发生.在通常情况下,我们仅开启一台Master的写入,另一台Master仅仅 stand by或者作为读库开放,这样可以避免数据写入的冲突,防止数据不一致的情况发生.在正常情况下,如需进行停机维护,可按如下步骤执行Master的切换操作:
①.)停止当前Master 的所有写入操作.
可以参考"订阅服务器和分发" 使数据库表同步.
就是从本地数据库表更新到远程数据库表是同步进行的
*创建完成了发布在开始订阅远程的数据库
发布的表→强制新订阅→下一步→选择远程服务器(如果没有就先到企业管理器上连接)→*编要订阅的数据库名(这里是很多新手会搞错的地方:是需订阅的远程数据库名)→是,初始化(这项是没做过复制的数据库可选,如果以前做过的选择此项就会导至以前订阅的数据丢失.*做过复制的数据库可选"否")→完成
远程也同上.
可以找两台PC试一下.
以前参加过一个库存系统,由于其业务复杂性,搞了很多个应用来支撑.这样的话一份库存数据就有可能同时有多个应用来修改库存数据.
比如说,有定时任务域xx.cron,和SystemA域和SystemB域这几个JAVA应用,可能同时修改同一份库存数据.如果不做协调的话,就会有脏数据出现.
对于跨JAVA进程的线程协调,可以借助外部环境,例如DB或者Redis.下文介绍一下如何使用DB来实现分布式锁.
本文设计的分布式锁的交互方式如下:
在使用synchronized关键字的时候,必须指定一个锁对象.
进程内的线程可以基于obj来实现同步.obj今天这一节可以理解为一个锁对象.如果线程要进入synchronized代码块里,必须先持有obj对象上的锁.这种锁是JAVA里面的内置锁,创建的过程是线程安全的.那么借助DB,如何保证创建锁的过程是线程安全的呢?
可以利用DB中的UNIQUE KEY特性,一旦出现了重复的key,由于UNIQUE KEY的唯一性,会抛出异常的.在JAVA里面,是 SQLIntegrityConstraintViolationException 异常.
transaction_id是事务Id,比如说,可以用
来组装一个transaction_id,表示某仓库某销售模式下的某个条码资源.不同条码,当然就有不同的transaction_id.如果有两个应用,拿着相同的transaction_id来创建锁资源的时候,只能有一个应用创建成功.
在写操作频繁的业务系统中,通常会进行分库,以降低单数据库写入的压力,并提高写操作的吞吐量.如果使用了分库,那么业务数据自然也都分配到各个数据库上了.
在这种水平切分的多数据库上使用DB分布式锁,可以自定义一个DataSouce列表.并暴露一个 getConnection(String transactionId) 方法,按照transactionId找到对应的Connection.
实现代码如下:
首先编写一个initDataSourceList方法,并利用Spring的PostConstruct注解初始化一个DataSource 列表.相关的DB配置从db.properties读取.
DataSource使用阿里的DruidDataSource.
接着最重要的一个实现getConnection(String transactionId)方法.实现原理很简单,获取transactionId的hashcode,并对DataSource的长度取模即可.
连接池列表设计好后,就可以实现往distributed_lock表插入数据了.
此时此刻呢利用DB的 select for update 特性来锁住线程.当多个线程根据相同的transactionId并发同时操作 select for update 的时候,只有一个线程能成功,其他线程都block住,直到 select for update 成功的线程使用commit操作后,block住的所有线程的其中一个线程才能开始干活.
我们在上面的DistributedLock类中创建一个lock方法.
当线程执行完任务后,必须手动的执行解锁操作,之前被锁住的线程才能继续干活.在我们上面的实现中,其实就是获取到当时 select for update 成功的线程对应的Connection,并实行commit操作即可.
那么如何获取到呢?我们可以利用ThreadLocal.首先在DistributedLock类中定义
每次调用lock方法的时候,把Connection放置到ThreadLocal里面.我们修改lock方法.
这样子,当获取到Connection后,将其设置到ThreadLocal中,如果lock方法出现异常,则将其从ThreadLocal中移除掉.
有了这几步后,我们可以来实现解锁操作了.我们在DistributedLock添加一个unlock方法.
毕竟是利用DB来实现分布式锁,对DB还是造成一定的压力.当时考虑使用DB做分布式的一个重要原因是,我们的应用是后端应用,平时流量不大的,反而关键的是要保证库存数据的正确性.对于像前端库存系统,比如添加购物车占用库存等操作,最好别使用DB来实现分布式锁了.
如果想锁住多份数据该怎么实现?比如说,某个库存操作,既要修改物理库存,又要修改虚拟库存,想锁住物理库存的同时,又锁住虚拟库存.其实也不是很难,参考lock方法,写一个multiLock方法,提供多个transactionId的入参,for循环处理就可以了.这个后续有时间再补上.
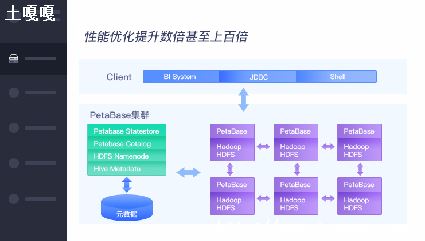
①.、主要解决针对大型网站架构中持久化部分中,大量数据存储以及高并发访问所带来是数据读写问题.分布式是将一个业务拆分为多个子业务,部署在不同的服务器上.集群是同一个业务,部署在多个服务器上.
通过分布式+集群的方式来提高io的吞吐量,以及数据库的主从复制,主主复制,负载均衡,高可用,分库分表以及数据库中间件的使用.
以上就是土嘎嘎小编为大家整理的分布式mysql怎么用相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!