

对比于其他语言的程序,Go语言的跨平台能力是真的强,拿.Net和JAVA来说吧,.Net在.Net core出现之前是不能跨平台的,只能在windows上编译运行,即使是.net core出现以后,跨平台的程序也是相当的麻烦.而java虽然一直都可以跨平台,但是运行JAVA程序的机器上也必须要有JAVA程序运行环境JRE.而相对于Go程序,跨平台就简单的多了,只需要在编译指定目标程序运行的架构和环境即可编译出指定操作系统和架构的程序.
好了,全部的指定了go的环境变量后执行的go build命令进行目标程序的构建,这种方式会一直生效的,如果不让他一直生效,可以在构建的时候临时指定环境变量,下面以window的环境为例,来介绍临时指定环境变量的方式构建可以在Linux环境下运行的可执行程序:
可以根据不同的架构和操作系统将其编写为不同的.bat的可执行文件放置在程序的根目录,Linux的和MAC的也一样编写成脚本文件放置在程序的根目录,这样在构建的时候就不用再敲命令了,直接运行脚本就可以了.
Java程序编译打包后为war包或者是java包,必须执行java -jar 命令或者将其放置到tomcat的指定目录下,运行tomcat程序.而Go语言编写的程序最终为可执行的文件(window下编译出的是.exe的可执行文件),只需要将其赋予可执行的权限就可以直接运行了.
构建JAVA程序的镜像需要指定java的基础镜像,否则就需要在镜像中安装java的运行环境了,下面展示的是构建的一个JAVA程序的镜像,构建出来镜像的体积相对比较大
而Go程序制作出的镜像就不需要安装任何的依赖环境,因为他在打包的时候就已经将依赖的包一块打包到一起了
拿着这个镜像就可以到处运行了.
通过对比我们可以发现,如果没有之前的技术和业务的积累,重新开发一个新的项目,使用go去开发无疑是最容易上手的,所以现在很多公司都使用go进行开发,也逐渐将其他语言的项目逐步的用go语言进行改造.其实用什么语言不重要,合适的才重要,开发项目在选择语言的时候也会综合多方面来考虑选择合适的语言和架构,毕竟很多公司都不是搞研究的,都需要项目来赚钱,所以开发的速度、客户的满意度、项目交付的时间才是驱动公司技术的主要因素.
我们个人也应该不断完善自己的技术栈,不应该太依靠某种语言,最重要的还是自己的架构思想和底层架构知识,只有掌握了这些才能够不被 社会 和公司"优化".
Go 语言较之 C 语言一个很大的优势就是自带 GC 功能,可 GC 并不是没有代价的.写 C 语言的时候,在一个函数内声明的变量,在函数退出后会自动释放掉,因为这些变量分配在栈上.如果你期望变量的数据可以在函数退出后仍然能被访问,就需要调用 malloc 方法在堆上申请内存,如果程序不再需要这块内存了,再调用 free 方法释放掉.Go 语言不需要你主动调用 malloc 来分配堆空间,编译器会自动分析,找出需要 malloc 的变量,使用堆内存.编译器的这个分析过程就叫做逃逸分析.
所以你在一个函数中通过 dict := make(map[string]int) 创建一个 map 变量,其背后的数据是放在栈空间上还是堆空间上,是不一定的.这要看编译器分析的结果.
可逃逸分析并不是百分百准确的,它有缺陷.有的时候你会发现有些变量其实在栈空间上分配完全没问题的,但编译后程序还是把这些数据放在了堆上.如果你了解 Go 语言编译器逃逸分析的机制,在写代码的时候就可以有意识地绕开这些缺陷,使你的程序更高效.
Go 语言虽然在内存管理方面降低了编程门槛,即使你不了解堆栈也能正常开发,但如果你要在性能上较真的话,还是要掌握这些基础知识.
这里举一个小例子,来对比下堆栈的差别:
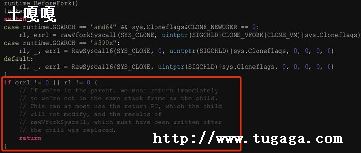
stack 函数中的变量 i 在函数退出会自动释放;而 heap 函数返回的是对变量 i 的引用,也就是说 heap() 退出后,表示变量 i 还要能被访问,它会自动被分配到堆空间上.
他们编译出来的代码如下:
逻辑的复杂度不言而喻,从上面的汇编中可看到, heap() 函数调用了 runtime.newobject() 方法,它会调用 mallocgc 方法从 mcache 上申请内存,申请的内部逻辑前面文章已经讲述过.堆内存分配不仅分配上逻辑比栈空间分配复杂,它最致命的是会带来很大的管理成本,Go 语言要消耗很多的计算资源对其进行标记回收(也就是 GC 成本).
我们在 go build 编译代码时,可使用 -gcflags '-m' 参数来查看逃逸分析日志.
以上面的两个函数为例,编译的日志输出是:
日志中的 i escapes to heap 表示该变量数据逃逸到了堆上.
需要使用堆空间,所以逃逸,这没什么可争议的.但编译器有时会将 不需要 使用堆空间的变量,也逃逸掉.这里是容易出现性能问题的大坑.网上有很多相关文章,列举了一些导致逃逸情况,其实总结起来就一句话:
多级间接赋值容易导致逃逸 .
这里的多级间接指的是,对某个引用类对象中的引用类成员进行赋值.Go 语言中的引用类数据类型有 func , interface , slice , map , chan , *Type(指针) .
记住公式 Data.Field = Value ,如果 Data , Field 都是引用类的数据类型,则会导致 Value 逃逸.这里的等号 = 不单单只赋值,也表示参数传递.
根据公式,我们假设一个变量 data 是以下几种类型,相应的可以得出结论:
下面给出一些实际的例子:
如果变量值是一个函数,函数的参数又是引用类型,则传递给它的参数都会逃逸.
上例中 te 的类型是 func(*int) ,属于引用类型,参数 *int 也是引用类型,则调用 te(j) 形成了为 te 的参数(成员) *int 赋值的现象,即 te.i = j 会导致逃逸.代码中其他几种调用都没有形成 多级间接赋值 情况.
同理,如果函数的参数类型是 slice , map 或 interface{} 都会导致参数逃逸.
匿名函数的调用也是一样的,它本质上也是一个函数变量.有兴趣的可以自己测试一下.
只要使用了 Interface 类型(不是 interafce{} ),那么赋值给它的变量一定会逃逸.因为 interfaceVariable.Method() 先是间接的定位到它的实际值,再调用实际值的同名方法,执行时实际值作为参数传递给方法.相当于 interfaceVariable.Method.this = realValue
向 channel 中发送数据,本质上就是为 channel 内部的成员赋值,就像给一个 slice 中的某一项赋值一样.所以 chan *Type , chan map[Type]Type , chan []Type , chan interface{} 类型都会导致发送到 channel 中的数据逃逸.
这本来也是情理之中的,发送给 channel 的数据是要与其他函数分享的,为了保证发送过去的指针依然可用,只能使用堆分配.
可变参数如 func(arg ...string) 实际与 func(arg []string) 是一样的,会增加一层访问路径.这也是 fmt.Sprintf 总是会使参数逃逸的原因.
Benchmark 和 pprof 给出的结果:
熟悉堆栈概念可以让我们更容易看透 Go 程序的性能问题,并进行优化.
多级间接赋值会导致 Go 编译器出现不必要的逃逸,在一些情况下可能我们只需要修改一下数据结构就会使性能有大幅提升.这也是很多人不推荐在 Go 中使用指针的原因,因为它会增加一级访问路径,而 map , slice , interface{} 等类型是不可避免要用到的,为了减少不必要的逃逸,只能拿指针开刀了.
大多数情况下,性能优化都会为程序带来一定的复杂度.建议实际项目中还是怎么方便怎么写,功能完成后通过性能分析找到瓶颈所在,再对局部进行优化.
Goroutine调度是一个很复杂的机制,下面尝试用简单的语言描述一下Goroutine调度机制,想要对其有更深入的了解可以去研读一下源码.
首先介绍一下GMP什么意思:
G ----------- goroutine: 即Go协程,每个go关键字都会创建一个协程.
M ---------- thread内核级线程,所有的G都要放在M上才能运行.
P ----------- processor处理器,调度G到M上,其维护了一个队列,存储了所有需要它来调度的G.
Goroutine 调度器P和 OS 调度器是通过 M 结合起来的,每个 M 都代表了 1 个内核线程,OS 调度器负责把内核线程分配到 CPU 的核上执行
模型图:
避免频繁的创建、销毁线程,而是对线程的复用.
①.)work stealing机制
当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程.
如果有空闲的P,则获取一个P,继续执行G0.
如果没有空闲的P,则将G0放入全局队列,等待被其他的P调度.然后M0将进入缓存池睡眠.
如下图
GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上同时运行
在Go中一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死.
具体可以去看另一篇文章
【Golang详解】go语言调度机制 抢占式调度
当创建一个新的G之后优先加入本地队列,如果本地队列满了,会将本地队列的G移动到全局队列里面,当M执行work stealing从其他P偷不到G时,它可以从全局G队列获取G.
协程经历过程
我们创建一个协程 go func()经历过程如下图:
说明:
G只能运行在M中,一个M必须持有一个P,M与P是1:1的关系.M会从P的本地队列弹出一个可执行状态的G来执行,如果P的本地队列为空,就会想其他的MP组合偷取一个可执行的G来执行;
一个M调度G执行的过程是一个循环机制;会一直从本地队列或全局队列中获取G
上面说到P的个数默认等于CPU核数,每个M必须持有一个P才可以执行G,一般情况下M的个数会略大于P的个数,这多出来的M将会在G产生系统调用时发挥作用.类似线程池,Go也提供一个M的池子,需要时从池子中获取,用完放回池子,不够用时就再创建一个.
work-stealing调度算法:当M执行完了当前P的本地队列队列里的所有G后,P也不会就这么在那躺尸啥都不干,它会先尝试从全局队列队列寻找G来执行,如果全局队列为空,它会随机挑选另外一个P,从它的队列里中拿走一半的G到自己的队列中执行.
如果一切正常,调度器会以上述的那种方式顺畅地运行,但这个世界没这么美好,总有意外发生,以下分析goroutine在两种例外情况下的行为.
Go runtime会在下面的goroutine被阻塞的情况下运行另外一个goroutine:
用户态阻塞/唤醒
系统调用阻塞
当M执行某一个G时候如果发生了阻塞操作,M会阻塞,如果当前有一些G在执行,调度器会把这个线程M从P中摘除,然后再创建一个新的操作系统的线程(如果有空闲的线程可用就复用空闲线程)来服务于这个P.当M系统调用结束时候,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列.如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中,然后这个G会被放入全局队列中.
队列轮转
可见每个P维护着一个包含G的队列,不考虑G进入系统调用或IO操作的情况下,P周期性的将G调度到M中执行,执行一小段时间,将上下文保存下来,然后将G放到队列尾部,然后从队列中重新取出一个G进行调度.
M0
M0是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量rutime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个G,在之后M0就和其他的M一样了
G0
G0是每次启动一个M都会第一个创建的goroutine,G0仅用于负责调度G,G0不指向任何可执行的函数,每个M都会有一个自己的G0,在调度或系统调用时会使用G0的栈空间,全局变量的G0是M0的G0
一个G由于调度被中断,此后如何恢复?
中断的时候将寄存器里的栈信息,保存到自己的G对象里面.当再次轮到自己执行时,将自己保存的栈信息复制到寄存器里面,这样就接着上次之后运行了.
我这里只是根据自己的理解进行了简单的介绍,想要详细了解有关GMP的底层原理可以去看Go调度器 G-P-M 模型的设计者的文档或直接看源码
参考: ()
()
在Go语言中有一些调试技巧能帮助我们快速找到问题,有时候你想尽可能多的记录异常但仍觉得不够,搞清楚堆栈的意义有助于定位Bug或者记录更完整的信息.
本文将讨论堆栈跟踪信息以及如何在堆栈中识别函数所传递的参数.
Functions
先从这段代码开始:
Listing 1
01 package main
①.0 }
Panic: Want stack trace
goroutine 1 [running]:
/Users/bill/Spaces/Go/Projects/src/github.com/goinaction/code/
main.main()
runtime.forcegchelper()
runtime.goexit()
runtime.bgsweep()
堆栈信息中显示了在panic抛出这个时间所有的goroutines状态,发生的panic的goroutine会显示在最上面.
01 goroutine 1 [running]:
下面我们关注参数是如何传递的:
// Declaration
main.Example(slice []string, str string, i int)
// Call to Example by main.
Example(slice, "hello", 10)
// Stack trace
第1个参数是string类型的slice,我们知道在Go语言中slice是引用类型,即slice变量结构会包含三个部分:指针、长度(Lengthe)、容量(Capacity)
// Slice parameter value
// Slice header values
Figure 1
figure provided by Georgi Knox
我们现在来看第二个参数,它是string类型,string类型也是引用类型,它包括两部分:指针、长度.
// String parameter value
"hello"
// String header values
main.Example(slice []string,?str string, i int)
最后一个参数integer是single word值.
// Integer parameter value
// Integer value
main.Example(slice []string, str string,?i int)
现在我们可以匹配代码中的参数到堆栈信息了.
Methods
如果我们将Example作为结构体的方法会怎么样呢?
①.0 ? ? var t trace
①.1 ? ? t.Example(slice, "hello", 10)
如上所示修改代码,将Example定义为trace的方法,并通过trace的实例t来调用Example.
再次运行程序,会发现堆栈信息有一点不同:
panic: Want stack trace
temp/main.go:11 +0xae
Packing
如果有多个参数可以填充到一个single word, 则这些参数值会合并打包:
Listing 10
Listing 11
这是本例的堆栈信息,看下图的具体分析:
// Parameter values
// Word value
Bits ? ?Binary ? ? ?Hex ? Value