

len(list)
列表元素个数
max(list)
返回列表元素最大值
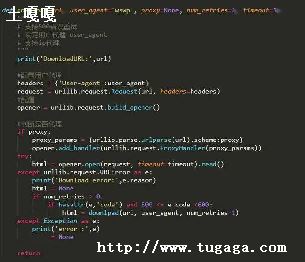
min(list)
返回列表元素最小值
list(seq)
将元组转换为列表
序号
方法
①.
list.append(obj)
在列表末尾添加新的对象
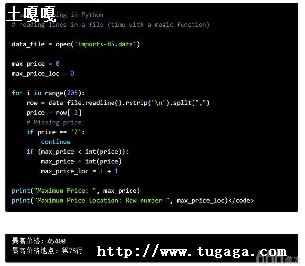
list.count(obj)
统计某个元素在列表中出现的次数
list.extend(seq)
在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
list.index(obj)
从列表中找出某个值第一个匹配项的索引位置
list.insert(index, obj)
将对象插入列表
list.pop([index=-1])
移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
list.remove(obj)
移除列表中某个值的第一个匹配项
list.reverse()
反向列表中元素
list.sort( key=None, reverse=False)
对原列表进行排序
①.0
list.clear()
清空列表
①.1
list.copy()
复制列表
python提供了常用的数据结构,其中之一就是set,python中的set是不支持索引的、值不能重复、无需插入的容器.
简单记录下set常用的操作函数:
①新建一个set:
set("Hello"),这样会转成单个字符的值进行插入,结果是'H','e','l','o','l'因为重复只能插入一次.
add()用于增加一个元素值,
update([]),用于增加多个元素值,参数为list,注意如果用add增加多个值,会报参数类型错误.
remove()用于删除一个set中的元素,这个值在set中必须存在,如果不存在的话,会引发KeyError错误.
discard()用于删除一个set中的元素,这个值不必一定存在,不存在的情况下删除也不会触发错误.
set提供了一个pop()函数,这个函数随机返回一个元素值,然后把这个值删除,如果set为空,调用这个函数会返回Key错误.
clear(),将set全部清空.
issubset和issuperset,
①.0.其他操作:
以上只是一部分操作的描述,如果有错误,敬请指正.
我要纠正推荐答案中的说法!
del并不是用来"删除引用指向的内存空间",python中的del和c++中的delete是完全两个概念,不要误人子弟..
一般来讲,del是用来删除变量的引用的,例如a = 1; del a,这里a是对1这个值的引用(python中所有的变量都可视作引用),而del a就是删除这一引用关系,也就是说,1不再被a这个变量引用了,同时a这个变量名也从变量表中剔除了.
如果还是不太清楚,我举这个例子你就明白了:
a = object()
b = a
del a
print b
print a # 该句会报a未定义的异常
这段代码中,a引用了一个新对象object(),而b=a使得b也引用了这个对象,a和b虽然是两个变量,但它们引用的是同一个对象,有点类似于c++中的两个指针指向同一个对象.
而后面del a仅仅只是把a这个变量对object()的引用删掉了,同时a的变量名也失效了,但并不表示object()这个对象被删除了,它还在,并且b还引用着它呢.从后面print b能正常输出就可以看出这一点.
python的内存释放采用的是引用计数机制,也就是当一个对象没有任何引用它的变量了,那么它就会自动被释放,无需人工干预.
字典是一种通过名字或者关键字引用的得数据结构,其键可以是数字、字符串、元组,这种结构类型也称之为映射.字典类型是Python中唯一内建的映射类型,基本的操作包括如下:
(1)len():返回字典中键―值对的数量;
(10)has_key函数:检查字典中是否含有给出的键
(11)items和iteritems函数:items将所有的字典项以列表方式返回,列表中项来自(键,值),iteritems与items作用相似,但是返回的是一个迭代器对象而不是列表
第一段:字典的创建
①1 直接创建字典
printd
printd['two']
printd['three']
运算结果:
=======RESTART: C:\Users\Mr_Deng\Desktop\test.py=======
printu'items中的内容:'
printitems
printu'利用dict创建字典,输出字典内容:'
d=dict(items)
printu'查询字典中的内容:'
printd['one']
items中的内容:
利用dict创建字典,输出字典内容:
查询字典中的内容:
或者通过关键字创建字典
printu'输出字典内容:'
输出字典内容:
第二段:字典的格式化字符串
print"three is %(three)s."%d
第三段:字典方法
d.clear()
{}
请看下面两个例子
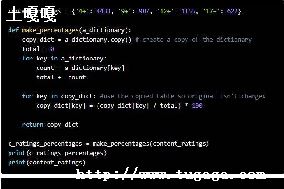
d={}
dd=d
d['one']=1
printdd
printu'初始X字典:'
printx
printu'X复制到Y:'
y=x.copy()
printu'Y字典:'
printy
printu'修改Y中的值,观察输出:'
printu'删除Y中的值,观察输出'
y['test'].remove('c')
初始X字典:
X复制到Y:
Y字典:
修改Y中的值,观察输出:
删除Y中的值,观察输出
注:在复制的副本中对值进行替换后,对原来的字典不产生影响,但是如果修改了副本,原始的字典也会被修改.deepcopy函数使用深复制,复制其包含所有的值,这个方法可以解决由于副本修改而使原始字典也变化的问题.
fromcopyimportdeepcopy
x={}
x['test']=['a','b','c','d']
z=deepcopy(x)
printu'输出:'
printz
printu'修改后输出:'
x['test'].append('e')
运算输出:
输出:
{'test': ['a','b','c','d']}
修改后输出:
{'test': ['a','b','c','d','e']}
d=dict.fromkeys(['one','two','three'])
{'three':None,'two':None,'one':None}
或者指定默认的对应值
d=dict.fromkeys(['one','two','three'],'unknow')
{'three':'unknow','two':'unknow','one':'unknow'}
printd.get('one')
printd.get('four')
None
注:get函数可以访问字典中不存在的键,当该键不存在是返回None
printd.has_key('one')
printd.has_key('four')
True
False
list=d.items()
forkey,valueinlist:
printkey,':',value
one :1
it=d.iteritems()
fork,vinit:
print"d[%s]="%k,v
d[one]=1
printu'keys方法:'
list=d.keys()
printlist
printu'\niterkeys方法:'
it=d.iterkeys()
forxinit:
keys方法:
['three','two','one']
iterkeys方法:
three
two
one
d.pop('one')
d.popitem()
printd.setdefault('one',1)
d={
}
x={'one':1}
d.update(x)
printd.values()