

re模块被称为正则表达式,其作用为,创建一个"规则表达式",用于验证和查找符合规则的文本,广泛用于各种搜索引擎、账户密码的验证等.
预定义字符:
\D:匹配所有的非数字,包含下划线
\s:匹配所有空白字符(空格、TAB等)

\S:匹配所有非空白字符,包含下划线
\W:匹配所有非字母、汉字、数字,包含下划线
特殊字符:
$:匹配一行的结尾(必须放在正则表达式最后面)
^:匹配一行的开头(必须放在正则表达式最前面)
*:前面的字符可以出现0次或多次(0~无限)
+:前面的字符可以出现1次或多次(1~无限)
:变"贪婪模式"为"勉强模式",前面的字符可以出现0次或1次

.:匹配除了换行符"\n"之外的任意单个字符
|:两项都进行匹配
[ ]:代表一个集合,有如下三种情况
[abc]:能匹配其中的单个字符
{ }:用于标记前面的字符出现的频率,有如下情况:
{n,m}:代表前面字符最少出现n次,最多出现m次
{n,}:代表前面字符最少出现n次,最多不受限制
{,m}:代表前面字符最多出现n次,最少不受
{n}:前面的字符必须出现n次
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,
而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用.
①.、字符
贪婪模式:总是尝试匹配尽可能多的字符
非贪婪则相反,总是尝试匹配尽可能少的字符.
{0,} 匹配前一个字符 0 或多次,等同于 * 元字符
{+,} 匹配前一个字符 1 次或无限次,等同于 + 元字符
{0,1 }匹配前一个字符 0 次或 1 次,等同于 ? 元字符
如果 () 后面跟的是特殊元字符如 (adc)* 那么*控制的前导字符就是 () 里的整体内容,不再是前导一个字符
从断言的表达形式可以看出,它用的就是分组符号,只不过开头都加了一个问号,这个问号就是在说这是一个非捕获组,这个组没有编号,不能用来后向引用,只能当做断言.
匹配 titlexxx/title 中 xxx : (?=title).*(?=/title)
自己理解就是:
(1)非
[^a-z] 反取,不含a-z字母的
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用
match 尝试从字符串的 起始位置 匹配一个模式,如果不是起始位置匹配成功的话,返回none.
search 扫描 整个字符串 并返回 第一个成功 的匹配.
re.match与re.search的区别:
正则表达式替换函数
替换匹配成功的指定位置字符串,并且返回替换次数,可以用两个变量分别接受
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表.
注意: match 和 search 是匹配一次 ,findall 匹配所有.
用法:
注意1:一旦匹配成,再次匹配,是从前一次匹配成功的,后面一位开始的,也可以理解为匹配成功的字符串,不在参与下次匹配
一个意思是匹配组里的内容,
二个意思是匹配组里 0 内容(即是空白)
所以尽量避免用 * 否则会有可能匹配出空字符串
正则表达式,返回类型为表达式对象的
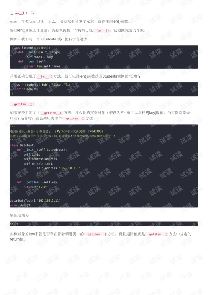
返回对象的,需要用正则方法取字符串,
. 匹配除换行符外的任意字符
\d 匹配数字
\D 匹配非数字
\w 匹配数字字母下划线,支持中文
\W 小写w的反集
[abc] 匹配abc中任意一个
[a-f] 匹配字母a到f中的任意一个
x|y 匹配x或者y
^ 匹配字符串的开头
$ 匹配字符串的结尾
* 匹配前一个字符,0次或多次
+ 匹配前一个字符,1次或多次
当前面不是数量表达式时,代表匹配0次或1次
举个栗子:
findall()函数的作用是匹配所有符合条件字符串,并以列表形式返回
可以看到在非贪婪模式下,列表中的每一项都匹配最少的字符数.
从前往后,匹配到符合条件的最短的每一个字符串
边界字符:
^ 限定开头
$ 限定结尾
匹配分组:
() 提取出来的只有括号里匹配到的部分
上文中已经用到这个方法了,返回匹配到的字符串列表,如果没有匹配到的内容,则返回空列表.
flags参数是可以省略的,不省略时代表具有其他特殊的功能,如忽略大小写,忽略换行符等,re.S代表匹配时忽略换行符
re.search()和re.findall()的参数是一样的,只是返回结果不同,如果匹配到了,就返回该结果的正则表达式对象;如果没有匹配到,则返回None
使用re.search()返回匹配到的第一个字符串的正则表达式对象,找到了就会停止匹配.所以呢这个函数比较适合在一个大文本中找第一个出现的字符串.
若想让这个字符串展示出来,还需要借助group()函数.
这个函数的作用是将正则表达式编译为一个正则表达式对象,如果要多次使用这个正则表达式的话,可以先编译,然后复用,使程序更高效一些,对这个对象继续使用.match(string)就可以显示匹配到的正则表达式对象,后续如果想要获取具体内容的话,和上面是一眼国的,直接使用group(0)就可以啦.
如果不考虑复用的话,和re.mach(pattern, string)的效果是一样的.
从运行结果也可以看出,re.match()和re.search()的区别,虽然二者都会返回匹配到的正则表达式对象,但是re.match()是从字符串的最开始位置开始匹配的,如果最开始的字符不匹配则会直接返回None;而re.search()则会一直往后找,直到找到第一个符合条件的字符串.
re.sub()函数用于替换字符串中的匹配项
将所有数字替换为了一个空格.
以上就是土嘎嘎小编为大家整理的python中的re函数相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!