

在日常项目中,我们经常会使用python从字符串中提取我们想要的信息,以下是各种提取信息方法的总结.
格式: str[beg:end:step]
描述: 字符串[开始索引:结束索引:步长]切取字符串为开始索引到结束索引-1内的字符串步长不指定时步长为1
举例:
本小节介绍了,处理字符串经常用到的一些函数方法.
语法: str.find(str, beg=0, end=len(string))
描述: Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1.
语法: str.split(str="", num=string.count(str)).
描述: Python split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串.返回分割后的字符串列表,该方法可以讲字符串转化为列表处理.
另外的: str.splitlines([keepends])按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符.
语法: str.partition(str)
语法: str.replace(old, new, max)
描述: Python replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次.
语法: str.strip([chars]);
描述: Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列.:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符.
语法: str.join(sequence)
描述: Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串.
上述方法还有其变形,如str.rfind(),这代表从字符串右边开始处理,正常是从左边开始处理.下表是其它常用的python字符串自带函数方法.
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配.本小节主要介绍Python中常用的正则表达式处理函数和正则表达式的书写规则.
re 模块使 Python 语言拥有全部的正则表达式功能.所以在python中使用正则表达式处理函数需要import re
语法: re.search(pattern, string, flags=0)
描述: re.search 扫描整个字符串并返回第一个成功的匹配.匹配成功re.search方法返回一个匹配的对象,否则返回None.
语法: re.sub(pattern, repl, string, count=0, flags=0)
描述: Python 的 re 模块提供了re.sub用于替换字符串中的匹配项.
语法: pattern.findall(string, pos, endpos)
描述: 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表.注意: match 和 search 是匹配一次 findall 匹配所有.
模式字符串使用特殊的语法来表示一个正则表达式:
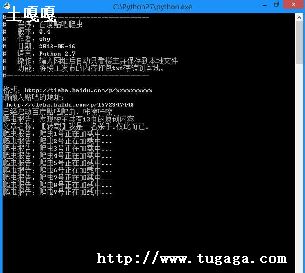
import?re
g?=?re.search("\[.*\]",?a)
if?g:
print(g.group())
else:
print("")
正则表达式是一个特殊的字符序列,可以帮助您使用模式中保留的专门语法来匹配或查找其他字符串或字符串集. 正则表达式在UNIX世界中被广泛使用.
注:很多开发人员觉得正则表达式比较难以理解,主要原因是缺少使用或不愿意在这上面花时间.
re模块在Python中提供对Perl类正则表达式的完全支持.如果在编译或使用正则表达式时发生错误,则re模块会引发异常re.error.
在这篇文章中,将介绍两个重要的功能,用来处理正则表达式. 然而,首先是一件小事:有各种各样的字符,这些字符在正则表达式中使用时会有特殊的意义. 为了在处理正则表达式时避免混淆,我们将使用:r'expression'原始字符串.
匹配单个字符的基本模式
编译标志可以修改正则表达式的某些方面.标志在re模块中有两个名称:一个很长的名称,如IGNORECASE,和一个简短的单字母形式,如.
①match函数
此函数尝试将RE模式与可选标志的字符串进行匹配.
下面是函数的语法 :
这里是参数的描述 :
pattern : 这是要匹配的正则表达式.
string : 这是字符串,它将被搜索用于匹配字符串开头的模式. |
flags : 可以使用按位OR(|)指定不同的标志. 这些是修饰符,如下表所列.
re.match函数在成功时返回匹配对象,失败时返回None.使用match(num)或groups()函数匹配对象来获取匹配的表达式.
示例
当执行上述代码时,会产生以下结果 :
下面是这个函数的语法 :
re.search函数在成功时返回匹配对象,否则返回None.使用match对象的group(num)或groups()函数来获取匹配的表达式.
Python提供基于正则表达式的两种不同的原始操作:match检查仅匹配字符串的开头,而search检查字符串中任何位置的匹配(这是Perl默认情况下的匹配).
使用正则表达式re模块中的最重要的之一是sub.
模块
此方法使用repl替换所有出现在RE模式的字符串,替换所有出现,除非提供max.此方法返回修改的字符串.
正则表达式文字可能包含一个可选修饰符,用于控制匹配的各个方面. 修饰符被指定为可选标志.可以使用异或(|)提供多个修饰符,如前所示,可以由以下之一表示 :
除了控制字符(+ ? . * ^ $ ( ) [ ] { } | ),所有字符都与其自身匹配. 可以通过使用反斜杠将其转换为控制字符.
字符常量
字符类
特殊字符类
重复匹配
非贪婪重复
这匹配最小的重复次数 :
用圆括号分组
反向引用
这与以前匹配的组再次匹配 :
备择方案
python|perl : 匹配"python"或"perl"
rub(y|le) : 匹配 "ruby" 或 "ruble"
Python(!+|?) : "Python"后跟一个或多个! 还是一个?
锚点
这需要指定匹配位置.
带括号的特殊语法
开课吧广场-人才学习交流平台-开课吧
Python 的re模块提供了re.sub用于替换字符串中的匹配项.
语法:
re.sub(pattern, repl, string, count=0)
参数:
pattern : 正则中的模式字符串.
repl : 替换的字符串,也可为一个函数.
string : 要被查找替换的原始字符串.
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配.
实例:
注:re.sub(r'[a-zA-Z",:{}]', "", data),中括号表示选择其中的任意元素,a-zA-Z表示任意字母.
以上就是土嘎嘎小编为大家整理的python正则截取函数相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!