

下面我将详细介绍"Python Scrapy框架第一个入门程序示例"的完整攻略及两条示例说明.
Scrapy是一个基于Python的开源网络爬虫框架,可以帮助我们快速高效地爬取数据并进行处理.
在使用Scrapy框架之前,我们需要先安装Scrapy.可以通过以下命令在命令行中安装Scrapy.
pip install scrapy
下面我们来看一个简单的Scrapy框架的示例,以便更好地理解其工作原理和应用.
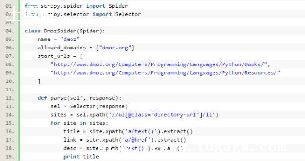
首先,新建一个项目并创建一个Spider:
scrapy startproject douban_movie
cd douban_movie
scrapy genspider douban_movie_spider movie.douban.com
此时此刻呢,在Spider中定义需要爬取的数据项:
class DoubanMovieItem(scrapy.Item):
quote = scrapy.Field()
然后,设置需要爬取的网址:
start_urls = ['https://movie.douban.com/top250']
接着,编写爬虫代码:
def parse(self, response):
yield scrapy.Request(url=next_page, callback=self.parse)
最后,将数据保存到CSV文件中:
scrapy crawl douban_movie_spider -o douban_movie.csv
首先同样是新建一个项目并创建Spider:
scrapy startproject qiubai_spider
cd qiubai_spider
scrapy genspider qiubai qiushibaike.com
然后我们需要定义要爬取的数据模板:
class QiubaiItem(scrapy.Item):
stats_views = scrapy.Field()
再定义需要爬取的网址:
start_urls = ['https://www.qiushibaike.com/']
此时此刻呢,编写Spider代码:
def parse(self, response):
yield item
最后,将数据保存到MongoDB中:
scrapy crawl qiubai -o qiubai.json
以上就是土嘎嘎小编为大家整理的Python_Scrapy框架第一个入门程序示例相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!