

MongoDB分片是指将数据水平分隔为多个部分,存储在不同的服务器上.这样做的目的是为了解决单一MongoDB实例容量有限的问题,以此来满足庞大数据量的存储需求.
以下是在Linux上安装配置服务器的步骤:
解压后放在/usr/local/mongodb-shard目录下
在/usr/local/mongodb-shard下创建mkdir db/cs1/db
创建配置文件touch cs1.cfg
添加内容
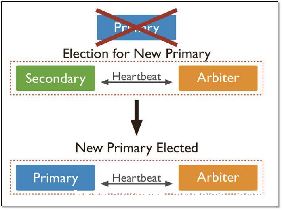
mongod分片组是用于MongoDB分片的核心部分.主要作用是将数据分布在不同的服务器上.
以下是在Linux上安装mongod分片组的步骤:
解压后放置在/usr/local/mongodb-shard文件夹中
在/usr/local/mongodb-shard下创建mkdir db/shard1/db
创建配置文件touch shard1.cfg
路由器(mongos)是MongoDB分片的入口,它将所有的读写请求路由到正确的mongod实例上.
以下是在Linux上安装路由器(mongos)的步骤:
创建配置文件touch mongos1.cfg
启动mongos/usr/local/mongodb-shard/bin/mongos --config /usr/local/mongodb-shard/mongos1.cfg
场景:假设有一个名为customers的集合,他们的数据比较大,现希望将该集合进行分片.
在mongos实例中运行以下命令创建索引:
use db
db.customers.createIndex({phone:1,email:1})
在mongos实例中运行以下命令启用分片:
use admin
sh.enableSharding("db")
sh.shardCollection("db.customers",{phone:1,email:1})
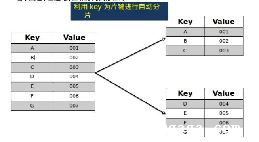
这个命令的含义是:使用phone和email字段将集合db.customers进行分片.这样做后,每条文档都会分配到不同的mongod实例中存储.
以上内容可能不是太好理解,下面我将通过一个简单的例子说明怎样进行MongoDB分片.
假设我们的数据包含两个collection:名称为students和teachers,students至少拥有1000万条数据,teachers仅有几千条数据.在这种情况下,我们可以将students进行分片,而将teachers保留在单实例中.
具体步骤如下:
# clone mongoD2
mongod --port 20001 --dbpath /data/db2_1 --replSet myset --fork --logpath /data/db2_1/log
# create dir
mkdir /data/db2_2 /data/db2_3
# Start the second and third instances
mongod --port 20002 --dbpath /data/db2_2 --replSet myset --fork --logpath /data/db2_2/log
mongod --port 20003 --dbpath /data/db2_3 --replSet myset --fork --logpath /data/db2_3/log
mongos --configdb myset/localhost:20001,localhost:20002,localhost:20003 --port 20000 --fork --logpath /data/mongos.log
此时,我们要将students集合进行分片,我们应该做的第一步是向MongoDB导入一些数据.然后我们在MongoS实例上运行以下命令:
# Insert data
for(i=1; i<2000000; i++) {
db.students.insert({sid:i,name:"test",score:i0})
}
# Enable Sharding
sh.enableSharding("test")
sh.shardCollection("test.students",{sid: "hashed"})
现在,列表test.students已经成功进行分片.
通过以上步骤,MongoDB分片集群就可以顺利地建立了.我们可以向其中的任何一个mongos节点发出任何查询请求,mongos会将请求转发到正确的MongoDB分片集群服务器上.这样,我们就可以存储更多的数据来处理业务需求了.