

①.、首先,需要了解python中输入函数y=xtanx的作用.
实际项目中经常遇到读取二进制问题,Python下读取二进制文件一般用Python的文件打开读写相关函数和struct.
①获取文件名filename,可用对话框,也可以直接手写
binFile=open(filename,'rb')
realContext=struct.unpack(format,context)
读入四个字符
对应格式参考
binFile.close()
binFile.seek(100)

python的常用内置函数
①abs() 函数返回数字的绝对值
dict()
{} ? ? ?#创建一个空字典类似于u={},字典的存取方式一般为key-value
help('math')查看math模块的用处
help(a)查看列表list帮助信息
dir(help)
['__call__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
a
①.0
next(it)
id(a)
a=["tom","marry","leblan"]
list(enumerate(a))
oct(10)
①.0. bin() 返回一个整数 int 或者长整数 long int 的二进制表示
bin(10)
'0b1010'
'0b1111'
①.1.eval() 函数用来执行一个字符串表达式,并返回表达式的值
f=open('test.txt')
bool()
False
bool(1)
True
bool(10)
bool(10.0)
isinstance(a,int)
isinstance(a,str)
class ? User(object):
? ? def__init__(self):
class Persons(User):
? ? ? ? ? super(Persons,self).__init__()
float(1)
①0
float(10)
①.0.0
iter(a)
for i in iter(a):
... ? ? ? ? print(i)
...
tuple(a)
s = "playbasketball"
len(s)
len(a)
class User(object):
? ?def __init__(self,name):
? ? ? ? ? ? self.name = name
? def get_name(self):
? ? ? ? ? ? return self.get_name
? @property
? ?def name(self):
? ? ? ? ? ?return self_name
list(b)
range(10)
range(0, 10)
class w(object):
a = w()
getattr(a,'s')
complex(1)
(1+0j)
complex("1")
max(b)
class Num(object):
...? ? a=1
.. print1 = Num()
print('a=',print1.a)
a= 1
print('b=',print1.b)
print('c=',print1.c)
delattr(Num,'b')
Traceback (most recent call last):? File "", line 1, inAttributeError: 'Num' object has no attribute 'b'
hash("tom")
a= set("tom")
b = set("marrt")
a,b
({'t', 'm', 'o'}, {'m', 't', 'a', 'r'})
ab#交集
{'t', 'm'}
a|b#并集
{'t', 'm', 'r', 'o', 'a'}
a-b#差集
{'o'}
①.、创建文件和数据集
import numpy as np
f['data'] = imgData #将数据写入文件的主键data下面
f.close() #关闭文件
for key in f.keys():
print(f[key].name)
print(f[key].shape)
print(f[key].value)
输出结果:
/data
[[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]]
/labels
Process finished with exit code 0
写入读取pkl文件
①.)字典类型:
import pickle
dict_data={'name':["张三","李四"]}
with open("dict_data.pkl","wb") as fo:
pickle.dump(dict_data,fo)
with open("dict_data","rb") as fo:
dict_data=pickle.load(fo,encoding='bytes')
print(dict_data.keys())
print(dict_data)
print(dict_data["name"])
结果如下:
dict_keys(['name'])
{'name': ['张三', '李四']}
['张三', '李四']
list_data=["张三","李四"]
with open ("list_data","wb") as fo:
pickle.dump(list_data,fo)
with open("list_data","rb") as fo:
pickle.load(fo,encoding='bytes')
print(list_data)
print(list_data.keys())
pirnt(list_data["name"])
mat文件
mat数据格式是Matlab的数据存储的标准格式.在Matlab中主要使用load()函数导入一个mat文件,使用save()函数保存一个mat文件.对于文件data.mat:
load('data.mat')
save('data_1.mat','A')
其中'A'表示要保存的内容.
在python读取mat文件:
①.、读取文件:
import scipy.io as scio
file1='E://data.mat'
data=scio.loadmat(file1)
注意,读取出来的data是字典格式,可以通过函数type(data)查看.
print type(data)
结果显示
type 'dict'
找到mat文件中的矩阵:
print data['A']
【常见的内置函数】
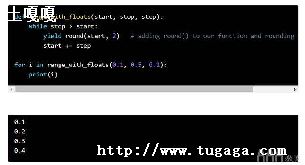
①.、enumerate(iterable,start=0)
是python的内置函数,是枚举、列举的意思,对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值.
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表.如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用*号操作符,可以将元组解压为列表.
filter是将一个序列进行过滤,返回迭代器的对象,去除不满足条件的序列.
是用来判断某一个变量或者是对象是不是属于某种类型的一个函数,如果参数object是classinfo的实例,或者object是classinfo类的子类的一个实例,
返回True.如果object不是一个给定类型的的对象, 则返回结果总是False
用来将字符串str当成有效的表达式来求值并返回计算结果,表达式解析参数expression并作为Python表达式进行求值(从技术上说是一个条件列表),采用globals和locals字典作为全局和局部命名空间.
【常用的句式】
①.、format字符串格式化
format把字符串当成一个模板,通过传入的参数进行格式化,非常实用且强大.
常使用+连接两个字符串.
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块.其中if...else语句用来执行需要判断的情形.
循环语句就是遍历一个序列,循环去执行某个操作,Python中的循环语句有for和while.
有时需要使用另一个python文件中的脚本,这其实很简单,就像使用import关键字导入任何模块一样.
以上就是土嘎嘎小编为大家整理的python的读入函数相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!