

MySQL Replication
InnoDB Cluster
InnoDB ClusterSet
InnoDB ReplicaSet
MMM
MHA
Galera Cluster
MySQL Cluster
MySQL Fabric
参考
MySQL 中的集群部署方案
这里来聊聊,MySQL 中常用的部署方案.
MySQL Replication 是官方提供的主从同步方案,用于将一个 MySQL 的实例同步到另一个实例中.Replication 为保证数据安全做了重要的保证,是目前运用最广的 MySQL 容灾方案.Replication 用两个或以上的实例搭建了 MySQL 主从复制集群,提供单点写入,多点读取的服务,实现了读的 scale out.
上面的栗子,一个主库(M),三个从库(S),通过 replication,Master 生成 event 的 binlog,然后发给 slave,Slave 将 event 写入 relaylog,然后将其提交到自身数据库中,实现主从数据同步.
对于数据库之上的业务层来说,基于 MySQL 的主从复制集群,单点写入 Master ,在 event 同步到 Slave 后,读逻辑可以从任何一个 Slave 读取数据,以读写分离的方式,大大降低 Master 的运行负载,同时提升了 Slave 的资源利用.
优点:
①.、通过读写分离实现横向扩展的能力,写入和更新操作在源服务器上进行,从服务器中进行数据的读取操作,通过增大从服务器的个数,能够极大的增强数据库的读取能力;
实现原理
在主从复制中,从库利用主库上的 binlog 进行重播,实现主从同步,复制的过程中蛀主要使用到了 dump thread,I/O thread,sql thread 这三个线程.
IO thread: 在从库执行 start slave 语句时创建,负责连接主库,请求 binlog,接收 binlog 并写入 relay-log;
dump thread:用于主库同步 binlog 给从库,负责响应从 IO thread 的请求.主库会给每个从库的连接创建一个 dump thread,然后同步 binlog 给从库;
sql thread:读取 relay log 执行命令实现从库数据的更新.
来看下复制的流程:
①.、主库收到更新命令,执行更新操作,生成 binlog;
不过 MySQL Replication 有个严重的缺点就是主从同步延迟.
因为数据是进行主从同步的,那么就会遇到主从同步延迟的情况.
为什么会出现主从延迟?
①.、从库机器的性能比主库差;
大量查询放在从库上,可能会导致从库上耗费了大量的 CPU 资源,进而影响了同步速度,造成主从延迟.
有事务产生的时候,主库必须要等待事务完成之后才能写入到 binlog,假定执行的事务是一个非常大的数据插入,这些数据传输到从库,从库同步这些数据也需要一定的时间,就会导致从节点出现数据延迟.
如果从库的复制能力,低于主库,那么在主库写入压力很大的情况下,就会造成从库长时间数据延迟的情况出现.
如何解决?
①.、优化业务逻辑,避免出现多线程大事务的并发场景;
semi-sync 半同步复制
MySQL 有三种同步模式,分别是:
半同步复制潜在的问题
这样会存在问题就是,主库已经将该事务的 commit 存储到了引擎层,应用已经可以看到数据的变化了,只是在等待从库的返回,如果此时主库宕机,可能从库还没有写入 Relay Log,就会发生主从库数据不一致.
不过看下来增强半同步复制,在同步给从库之后,因为自己的数据还没有提交,然后宕机了,主库中也是会存在数据的丢失,不过应该想到的是,这时候主库宕机了,是会重新在从库中选主的,这样新选出的主库数据是没有发生丢失的.
MySQL Group Replication
引入复制组主要是为了解决传统异步复制和半同步复制可能产生数据不一致的问题.
在不同组成员并发执行的事务可能存在冲突.冲突是通过检查和比较两个不同并发事务的 write set 来验证的,这个过程称为认证.在认证期间,冲突检测在行级别执行的:如果在不同组成员上执行的两个并发事务更新了同一行数据,则存在冲突.根据冲突认证检测机制判断,按照顺序,第一次提交的会正常执行,第二次提交的事务会在事务发起的原始组成员上执行回滚,,组中的其他成员对该事务执行删除.如果两个事务经常发生冲突,那么最好将这两个事务放在同一个组成员中执行,这样它们在本地锁管理器的协调下将都有机会提交成功,而不至于因为处在两个不同的组成员中由于冲突认证而导致其中一个事务被频繁回滚.
最终,所有组内成员以相同的顺序接收同一组事务.所以呢组内成员以相同的顺序应用相同的修改,保证组内数据强一致性.
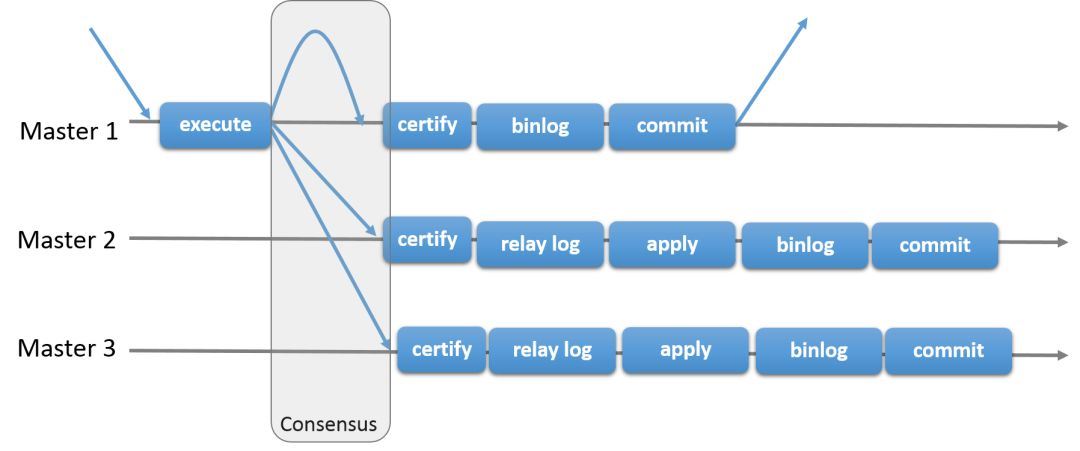
有下面的几种特性:
①.、避免脑裂:MGR 中不会出现脑裂的现象;
组复制的应用场景
①.、弹性复制:需要非常灵活的复制基础设施的环境,其中MySQL Server的数量必须动态增加或减少,并且在增加或减少Server的过程中,对业务的副作用尽可能少.例如,云数据库服务;
InnoDB Cluster 是官方提供的高可用方案,是 MySQL 的一种高可用性(HA)解决方案,它通过使用 MySQL Group Replication 来实现数据的自动复制和高可用性,InnoDB Cluster 通常包含下面三个关键组件:
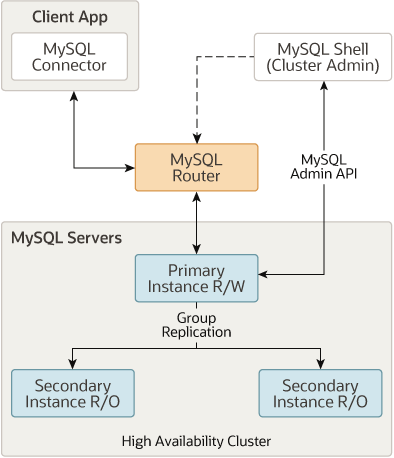
MySQL Server 基于 MySQL Group Replication 构建,提供自动成员管理,容错,自动故障转移动能等.InnoDB Cluster 通常以单主模式运行,一个读写实例和多个只读实例.不过也可以选用多主模式.
①.、高可用性:通过 MySQL Group Replication,InnoDB Cluster 能够实现数据在集群中的自动复制,从而保证数据的可用性;
缺点:
①.、复杂性:InnoDB Cluster 的部署和管理比较复杂,需要对 MySQL 的工作原理有一定的了解;
MySQL InnoDB ClusterSet 通过将主 InnoDB Cluster 与其在备用位置(例如不同数据中心)的一个或多个副本链接起来,为 InnoDB Cluster 部署提供容灾能力.
InnoDB ClusterSet 使用专用的 ClusterSet 复制通道自动管理从主集群到副本集群的复制.如果主集群由于数据中心损坏或网络连接丢失而变得无法使用,用户可以激活副本集群以恢复服务的可用性.
InnoDB ClusterSet 的特点:
①.、主集群和副本集群之间的紧急故障转移可以由管理员通过 MySQL Shell,使用 AdminAPI 进行操作;
InnoDB ClusterSet 的限制:
①.、InnoDB ClusterSet 只支持异步复制,不能使用半同步复制,无法避免异步复制的缺陷:数据延迟、数据一致性等;
InnoDB ReplicaSet 由单个主节点和多个辅助节点(传统上称为 MySQL 复制源和副本)组成.
与 InnoDB cluster 类似, MySQL Router 支持针对 InnoDB ReplicaSet 的引导, 这意味着可以自动配置 MySQL Router 以使用 InnoDB ReplicaSet, 而无需手动配置文件. 这使得 InnoDB ReplicaSet 成为一种快速简便的方法, 可以启动和运行 MySQL 复制和 MySQL Router, 非常适合扩展读取, 并在不需要 InnoDB 集群提供高可用性的用例中提供手动故障转移功能.
InnoDB ReplicaSet 的限制:
①.、没有自动故障转移,在主节点不可用的情况下,需要使用 AdminAPI 手动触发故障转移,然后才能再次进行任何更改.但是,辅助实例仍可用于读取;
使用 InnoDB ReplicaSets 的主要原因是你有更好的写性能.使用 InnoDB ReplicaSets 的另一个原因是它们允许在不稳定或慢速网络上部署,而 InnoDB Cluster 则不允许.
MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序.MMM 使用 Perl 语言开发,主要用来监控和管理 MySQL Master-Master(双主)复制,可以说是 MySQL 主主复制管理器.
双主模式,业务上同一时刻只能一个主库进行数据的写入.另一个主备库,会在主服务器失效时,进行主备切换和故障转移.
MMM 中是通过一个 VIP(虚拟 IP) 的机制来保证集群的高可用的.整个集群中,在主节点会提供一个 VIP 地址来提供数据读写服务,当出现故障的时候,VIP 就会从原来的主节点便宜到其他节点,由其他节点提供服务.
MMM无法完全的保证数据一致性,所以适用于对数据的一致性要求不是很高的场景.(因为主备上的数据不一定是最新的,可能还没从库的新.解决方法:开启半同步).
MMM 的优缺点
优点:高可用性,扩展性好,出现故障自动切换,对于主主同步,在同一时间只提供一台数据库写操作,保证数据的一致性.
缺点:无法完全保数据的一致性,建议采用半同步复制方式,减少失败的概率;目前 MMM 社区已经缺少维护,不支持基于 GTID 的复制.
适用场景:
MMM的适用场景为数据库访问量大,业务增长快,并且能实现读写分离的场景.
Master High Availability Manager and Tools for MySQL,简称 MHA .是一套优秀的作为 MySQL 高可用性环境下故障切换和主从提升的高可用软件.
MHA 由两部分组成;
MHA Manager(管理节点)和MHA Node(数据节点).
MHA Manager 可以单独部署在一台独立的机器上管理多个 master-slave 集群,也可以部署在一台 slave节点上.MHA Node 运行在每台 MySQL 服务器上,MHA Manager 会定时探测集群中的 master 节点,当 master 出现故障时,它可以自动将最新数据的 slave 提升为新的 master,然后将所有其他的 slave 重新指向新的 master.
整个故障转移过程对应用程序完全透明.
在 MHA 自动故障切换过程中,MHA 试图从宕机的主服务器上最大限度的保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的.例如,主服务器硬件故障或无法通过 ssh 访问,MHA 没法保存二进制日志,只进行故障转移而丢失了最新的数据.
目前 MHA 主要支持一主多从的架构,要搭建 MHA,要求一个复制集群中必须最少有三台数据库服务器 ,一主二从,即一台 master,一台充当备用 master,另外一台充当从库,因为至少需要三台服务器.
MHA 工作原理总结如下:
①.、从宕机崩溃的 master 保存二进制日志事件(binlog events);
①.、可以支持基于 GTID 的复制模式;
①.、需要编写脚本或利用第三方工具来实现 Vip 的配置;
Galera Cluster 是由 Codership 开发的MySQL多主集群,包含在 MariaDB 中,同时支持 Percona xtradb、MySQL,是一个易于使用的高可用解决方案,在数据完整性、可扩展性及高性能方面都有可接受的表现.
主要功能
①.、同步复制;
优势
①.、数据一致:同步复制保证了整个集群的数据一致性,无论何时在任何节点执行相同的select查询,结果都一样;
分析下原理
Galera Cluster 中主要用到了同步复制,主库中的单个更新事务需要在所有从库中同步更新,当主库提交事务,集群中的所有节点数据保持一致.
异步复制,主库将数据更新传播给从库后立即提交事务,而不论从库是否成功读取或重放数据变化,所以异步复制会存在短暂的,主从数据同步不一致的情况出现.
不过同步复制的缺点也是很明显的,同步复制协议通常使用两阶段提交或分布式锁协调不同节点的操作,也及时说节点越多需要协调的节点也就越多,那么事务冲突和死锁的概率也就会随之增加.
我们知道 MGR 组复制的引入也是为了解决传统异步复制和半同步复制可能产生数据不一致的问题,MGR 中的组复制,基于 Paxos 协议,原则上事务的提交,主要大多数节点 ACK 就可以提交了.
Galera Cluster 中的同步需要同步数据到所有节点,保证所有节点都成功.基于专有通信组系统 GCommon ,所有节点都必须有 ACK.
Galera 复制是一种基于验证的复制,基于验证的复制使用通信和排序技术实现同步复制,通过广播并发事务之间建立的全局总序来协调事务提交.简单的讲就是事务必须以相同的顺序应用于所有实例.
事务现在本地执行,然后发送的其他节点做冲突验证,没有冲突的时候所有节点提交事务,否则在所有节点回滚.
节点用写集中的主键与当前节点中未完成事务的所有写集的主键比较,确定节点是否可以提交事务,同时满足下面三个条件会被任务存在冲突,验证失败:
验证失败,节点将删除写集,集群将回滚原始事务,对于所有的节点都是如此,每个节点单独进行验证.因为所有节点都以相同的顺序接收事务,它们对事务的结果都会做出相同的决定,要么全成功,要么都失败.成功后自然就提交了,所有的节点又会重新达到数据一致的状态.节点之间不交换"是否冲突"的信息,各个节点独立异步处理事务.
MySQL Cluster 是一个高度可扩展的,兼容 ACID 事务的实时数据库,基于分布式架构不存在单点故障,MySQL Cluster 支持自动水平扩容,并能做自动的读写负载均衡.
MySQL Cluster 使用了一个叫 NDB 的内存存储引擎来整合多个 MySQL 实例,提供一个统一的服务集群.
NDB 是一种内存性的存储引擎,使用 Sarding-Nothing 的无共享的架构.Sarding-Nothing 指的是每个节点有独立的处理器,磁盘和内存,节点之间没有共享资源完全独立互不干扰,节点之间通过告诉网络组在一起,每个节点相当于是一个小型的数据库,存储部分数据.这种架构的好处是可以利用节点的分布性并行处理数据,调高整体的性能,还有就是有很高的水平扩展性能,只需要增加节点就能增加数据的处理能力.
MySql Cluster 中包含三种节点,分别是管理节点(NDB Management Server)、数据节点(Data Nodes)和 SQL查询节点(SQL Nodes) .
SQL Nodes 是应用程序的接口,像普通的 mysqld 服务一样,接受用户的 SQL 输入,执行并返回结果.Data Nodes 是数据存储节点,NDB Management Server 用来管理集群中的每个 node.
其中数据节点会存储集群中的数据分区和分区的副本,来看下 MySql Cluster 是如何对数据进行分片的操作的,首先来了解下下面几个概念
节点组(Node Group): 一组数据节点的集合.节点组的个数=节点数 / 副本数;
另外,在可用性方面,数据的副本在组内交叉分配,一个节点组内只有要一台机器可用,就可以保证整个集群的数据完整性,实现服务的整体可用.
分区(Partition):MySql Cluster 是一个分布式的存储系统,数据按照 分区 划分成多份存储在各数据节点中,分区个数由系统自动计算,分区数 = 数据节点数 / LDM 线程数;
副本(Replica):分区数据的备份,有几个分区就有几个副本,为了避免单点,保证 MySql Cluster 集群的高可用,原始数据对应的分区和副本通常会保存在不同的主机上,在一个节点组内进行交叉备份.
这样,对于一张表的一个 Partition 来说,在整个集群有两份数据,并分布在两个独立的 Node 上,实现了数据容灾.同时,每次对一个 Partition 的写操作,都会在两个 Replica 上呈现,如果 Primary Replica 异常,那么 Backup Replica 可以立即提供服务,实现数据的高可用.
mysql cluster 的优点
mysql cluster 的缺点
MySQL Fabric 会组织多个 MySQL 数据库,将大的数据分散到多个数据库中,即数据分片(Data Shard),同时同一个分片数据库中又是一个主从结构,Fabric 会挑选合适的库作为主库,当主库挂掉的时候,又会重新在从库中选出一个主库.
MySQL Fabric 的特点:
①.、高可用;
MySQL Fabric-aware 连接器把从 MySQL Fabric 获取的路由信息存储到缓存中,然后凭借该信息将事务或查询发送给正确的 MySQL 服务器.
同时,每一个分片组,可以又多个一个服务器组成,构成主从结构,当主库挂掉的时候,又会重新在从库中选出一个主库.保证节点的高可用.
HA Group 保证访问指定 HA Group 的数据总是可用的,同时其基础的数据复制是基于 MySQL Replication 实现的.
缺点
事务及查询只支持在同一个分片内,事务中更新的数据不能跨分片,查询语句返回的数据也不能跨分片.
①.、MySQL Replication 是官方提供的主从同步方案,用于将一个 MySQL 的实例同步到另一个实例中,在主从复制中,从库利用主库上的 binlog 进行重播,实现主从同步,默认是异步同步,针对其在不同场景下的一些缺陷,衍生出了半同步复制,强同步复制等数据高可用的方案;
①.0、MySQL Fabric 会组织多个 MySQL 数据库,将大的数据分散到多个数据库中,即数据分片(Data Shard),同时同一个分片数据库中又是一个主从结构,Fabric 会挑选合适的库作为主库,当主库挂掉的时候,又会重新在从库中选出一个主库.