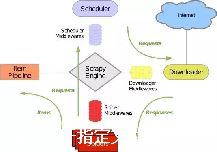
目标任务:将之前新浪网的Scrapy爬虫项目,修改为基于RedisSpider类的scrapy-redis分布式爬虫项目,将数据存入redis数据库.
第一段:item文件,和之前项目一样不需要改变
# -*- coding: utf-8 -*-import scrapy
import sys reload(sys) sys.setdefaultencoding("utf-8")
class SinanewsItem(scrapy.Item):
# 大类的标题和url parentTitle = scrapy.Field() parentUrls = scrapy.Field()
# 小类的标题和子url subTitle = scrapy.Field() subUrls = scrapy.Field() # 小类目录存储路径 subFilename = scrapy.Field() # 小类下的子链接 sonUrls = scrapy.Field() # 文章标题和内容 head = scrapy.Field() content = scrapy.Field()第二段:spiders爬虫文件,使用RedisSpider类替换之前的Spider类,其余地方做些许改动即可,具体代码如下:
# -*- coding: utf-8 -*-import scrapy
import os from sinaNews.items import SinanewsItem from scrapy_redis.spiders import RedisSpider import sys reload(sys) sys.setdefaultencoding("utf-8")class SinaSpider(RedisSpider):
name = "sina" # 启动爬虫的命令 redis_key = "sinaspider:strat_urls" # 动态定义爬虫爬取域范围 def init(self, args, **kwargs): domain = kwargs.pop('domain', '') self.allowed_domains = filter(None, domain.split(',')) super(SinaSpider, self).init(args, **kwargs)第三段:settings文件设置
SPIDER_MODULES = ['sinaNews.spiders'] NEWSPIDER_MODULE = 'sinaNews.spiders'# 使用scrapy-redis里的去重组件,不使用scrapy默认的去重方式
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis里的调度器组件,不使用默认的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 允许暂停,redis请求记录不丢失 SCHEDULER_PERSIST = True # 默认的scrapy-redis请求队列形式(按优先级) SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" # 队列形式,请求先进先出栈形式,请求先进后出
# 只是将数据放到redis数据库,不需要写pipelines文件
ITEM_PIPELINES = { # 'Sina.pipelines.SinaPipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400, }# LOG_LEVEL = 'DEBUG'
# Introduce an artifical delay to make use of parallelism. to speed up the
crawl.
DOWNLOAD_DELAY = 1
# 指定数据库的主机IP REDIS_HOST = "192.16⑧1③26" # 指定数据库的端口号 REDIS_PORT = 6379执行命令:
本次直接使用本地的redis数据库,将settings文件中的REDIS_HOST和REDIS_PORT注释掉.
启动爬虫程序
scrapy runspider sina.py执行程序后终端窗口显示如下:
表示程序处于等待状态,此时在redis数据库端执行如下命令:
http://news.sina.com.cn/guide/为起始url,此时程序开始执行.
# -*- coding: utf-8 -*-import scrapy
import sys reload(sys) sys.setdefaultencoding("utf-8")class SinanewsItem(scrapy.Item):
# 大类的标题和url parentTitle = scrapy.Field() parentUrls = scrapy.Field()# 小类的标题和子url subTitle = scrapy.Field() subUrls = scrapy.Field() # 小类目录存储路径 subFilename = scrapy.Field() # 小类下的子链接 sonUrls = scrapy.Field() # 文章标题和内容 head = scrapy.Field() content = scrapy.Field()# -*- coding: utf-8 -*-import scrapy
import os from sinaNews.items import SinanewsItem from scrapy_redis.spiders import RedisSpider import sys reload(sys) sys.setdefaultencoding("utf-8")class SinaSpider(RedisSpider):
name = "sina" # 启动爬虫的命令 redis_key = "sinaspider:strat_urls" # 动态定义爬虫爬取域范围 def init(self, args, **kwargs): domain = kwargs.pop('domain', '') self.allowed_domains = filter(None, domain.split(',')) super(SinaSpider, self).init(args, **kwargs)SPIDER_MODULES = ['sinaNews.spiders'] NEWSPIDER_MODULE = 'sinaNews.spiders'# 使用scrapy-redis里的去重组件,不使用scrapy默认的去重方式
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis里的调度器组件,不使用默认的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 允许暂停,redis请求记录不丢失 SCHEDULER_PERSIST = True # 默认的scrapy-redis请求队列形式(按优先级) SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" # 队列形式,请求先进先出栈形式,请求先进后出
# 只是将数据放到redis数据库,不需要写pipelines文件
ITEM_PIPELINES = { # 'Sina.pipelines.SinaPipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400, }# LOG_LEVEL = 'DEBUG'
# Introduce an artifical delay to make use of parallelism. to speed up the
crawl.
DOWNLOAD_DELAY = 1
# 指定数据库的主机IP REDIS_HOST = "192.16⑧1③26" # 指定数据库的端口号 REDIS_PORT = 6379scrapy runspider sina.py
以上就是土嘎嘎小编为大家整理的Python爬虫scrapy-redis分布式实例_一)相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!