import re
import traceback
from urllib.parse import urlparse
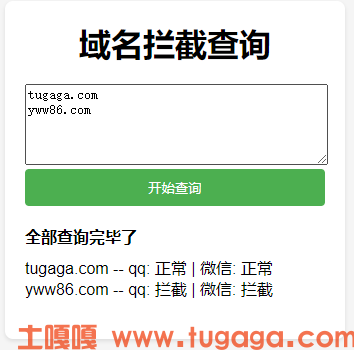
RAW_FILE = 'yuming.txt'
NEW_FILE = 'new_com_cn_ok.txt'
new_domains = []
def read():
with open(RAW_FILE, 'r',encoding="utf-8") as fp:
for line in fp.readlines():
try:
line = re.sub('\s', '', line)
parsed_result = urlparse(line)
netloc = parsed_result.netloc
path = parsed_result.path
if netloc:
domain = netloc
elif path:
domain = path
else:
print('该域名处理失败:{}'.format(line))
continue
domain_list = domain.split('.')
for _domain in domain_list:
if len(_domain) > 3: