

【常见的内置函数】
①.、enumerate(iterable,start=0)
是python的内置函数,是枚举、列举的意思,对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值.
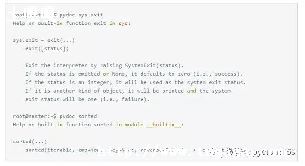
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表.如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用*号操作符,可以将元组解压为列表.
filter是将一个序列进行过滤,返回迭代器的对象,去除不满足条件的序列.
是用来判断某一个变量或者是对象是不是属于某种类型的一个函数,如果参数object是classinfo的实例,或者object是classinfo类的子类的一个实例,
返回True.如果object不是一个给定类型的的对象, 则返回结果总是False
用来将字符串str当成有效的表达式来求值并返回计算结果,表达式解析参数expression并作为Python表达式进行求值(从技术上说是一个条件列表),采用globals和locals字典作为全局和局部命名空间.
【常用的句式】
①.、format字符串格式化
format把字符串当成一个模板,通过传入的参数进行格式化,非常实用且强大.
常使用+连接两个字符串.
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块.其中if...else语句用来执行需要判断的情形.
循环语句就是遍历一个序列,循环去执行某个操作,Python中的循环语句有for和while.
有时需要使用另一个python文件中的脚本,这其实很简单,就像使用import关键字导入任何模块一样.
(1)Lambda函数
用于创建匿名函数,即没有名称的函数.它只是一个表达式,函数体比def简单很多.当我们需要创建一个函数来执行单个操作并且可以在一行中编写时,就可以用到匿名函数了.
Lamdba的主体是一个表达式,而不是一个代码块.仅仅能在lambda表达式中封装有限的逻辑进去.
利用Lamdba函数,往往可以将代码简化许多.
会将一个函数映射到一个输入列表的所有元素上,比如我们先创建了一个函数来返回一个大写的输入单词,然后将此函数应有到列表colors中的所有元素.
我们还可以使用匿名函数lamdba来配合map函数,这样可以更加精简.
当需要对一个列表进行一些计算并返回结果时,reduce()是个非常有用的函数.举个例子,当需要计算一个整数列表所有元素的乘积时,即可使用reduce函数实现.
它与函数的最大的区别就是,reduce()里的映射函数(function)接收两个参数,而map接收一个参数.
用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中.
它的两个参数,一个是序列、迭代器或其他支持迭代对象;另一个是下标起始位置,默认情况从0开始,也可以自定义计数器的起始编号.
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
当我们使用zip()函数时,如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同.
像Python这种解释性的语言,要想私有化部署的同时又保护好源码,就像是对于鱼和熊掌的追求.
虽然做不到尽善尽美,但是对代码进行混淆,增加一点破解的难度,或许能规避一些泄露的风险.
本次演示环境:linux
确保要发布的包根目录("demo")中有__main__.py文件,这个是程序执行入口.
编译
批量改名.pyc文件
移动.pyc文件
清理.py文件
清理__pycache__文件夹
打包成zip
运行时只要将zip文件作为参数即可
最终整合脚本
调用方式
对于在变量和函数名上的混淆有点小儿科,而对于跨文件的类名的混淆又太容易实现.
所以对于混淆程度的取舍,要视工程的规模而定.
在原来的工具 pyminifier上修复了几个bug.
安装:
或者clone下来,自行安装
使用例子
不同的配置对于源码的要求不同,以下是笔者踩过的坑.
其他混淆想法
结合混淆、编译和打包,尝试出以下发布脚本.
主要的思路 :创建一个工作目录tmp,然后在此目录下混淆、编译python代码,完成后把内容打包成pyc文件,再将pyc文件和其他配置文件移动到dist,发布dist即可.
Python:常用函数封装:
def is_chinese(uchar):
"""判断一个unicode是否是汉字"""
return True
else:
return False
def is_number(uchar):
"""判断一个unicode是否是数字"""
def is_alphabet(uchar):
"""判断一个unicode是否是英文字母"""
def is_other(uchar):
"""判断是否非汉字,数字和英文字符"""
if not (is_chinese(uchar) or is_number(uchar) or is_alphabet(uchar)):
"""半角转全角"""
inside_code=ord(uchar)
return uchar
inside_code+=0xfee0
return unichr(inside_code)
"""全角转半角"""
inside_code-=0xfee0
"""把字符串全角转半角"""
def uniform(ustring):
"""格式化字符串,完成全角转半角,大写转小写的工作"""
"""将ustring按照中文,字母,数字分开"""
retList=[]
utmp=[]
for uchar in ustring:
if is_other(uchar):
if len(utmp)==0:
continue
retList.append("".join(utmp))
utmp.append(uchar)
if len(utmp)!=0:
return retList
return 应该放在一个函数里面的,
使用cx_Freeze完成python打包exe主要有两种方法:
第一种,直接运行cxfreeze.bat通过:
定义:zip([iterable, ...])
zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),然后返回由这些 tuples组成的list(列表).若传入参数的长度不等,则返回list的长度和参数中长度最短的对象相同.利用*号操作符,可以将list unzip(解压),看下面的例子就明白了:
对于这个并不是很常用函数,下面举几个例子说明它的用法:
* 二维矩阵变换(矩阵的行列互换)
比如我们有一个由列表描述的二维矩阵
通过python列表推导的方法,我们也能轻易完成这个任务
另外一种让人困惑的方法就是利用zip函数:
这种方法速度更快但也更难以理解,将list看成tuple解压,恰好得到我们"行列互换"的效果,再通过对每个元素应用list()函数,将tuple转换为list
* 以指定概率获取元素
这个函数有个限制,指定概率的列表必须和元素一一对应,而且和为1,否则这个函数可能不能像预想的那样工作.
稍微解释下,先利用random.uniform()函数生成一个0-1之间的随机数并复制给x,利用zip()函数将元素和他对应的概率打包成tuple,然后将每个元素的概率进行叠加,直到和大于x终止循环
以上就是土嘎嘎小编为大家整理的python打包成函数相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!