

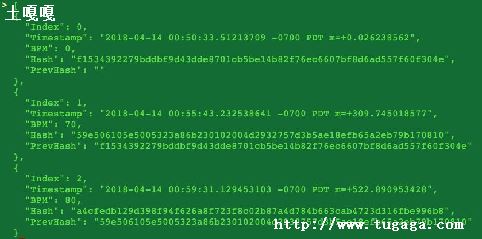
在前一小节中介绍了点亮第一个LED灯,这里我们准备进阶尝试下,输出第一段PWM波形.(PWM也就是脉宽调制,一种可调占空比的技术,得到的效果就是:如果用示波器测量引脚会发现有方波输出,而且高电平、低电平的时间是可调的.)
这里爪爪熊准备写成一个golang的库,并开源到github上,后续更新将直接更新到github中,如果你有兴趣可以和我联系. github.com/dpawsbear/bear_rpi_go
我在很多的教程中都看到说树莓派的PWM(硬件)只有一个GPIO能够输出,就是 GPIO1 .这可是不小的打击,因为我想使用至少四个 PWM ,还是不死心,想通过硬件手册上找寻蛛丝马迹,看看究竟怎么回事.
根据以上两个图对比可以发现如下规律:
为了验证个人猜想是否正确,这里先直接使用指令的模式,模拟配置下是否能够正常输出.
小节:树莓派具有四路硬件输出PWM能力,但是四路中只能输出两个独立(占空比独立)的PWM,同时四路输出的频率均是恒定的.
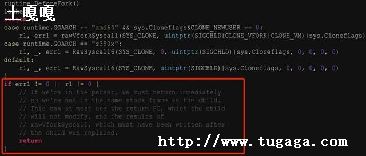
因为拿到了手册,这里我想直接操作寄存器的方式进行设置,也是顺便学习下Go语言处理寄存器的过程.首先需要拿到pwm 系列寄存器的基地址,但是翻了一圈手册,发现只有偏移,没有找到基地址.
以下是demo(pwm) 源码
切换到新语言始终是一大步,尤其是当您的团队成员只有一个时有该语言的先前经验.现在,Stream 的主要编程语言从 Python 切换到了 Go.这篇文章将解释stream决定放弃 Python 并转向 Go 的一些原因.
看看我如何开始 Go 教程中的一小段 Go 代码.(这是一个很棒的教程,也是学习 Go 的一个很好的起点.)
如果您是 Go 新手,那么在阅读那个小代码片段时不会有太多让您感到惊讶的事情.它展示了多个赋值、数据结构、指针、格式和一个内置的 HTTP 库.当我第一次开始编程时,我一直喜欢使用 Python 更高级的功能.Python 允许您在编写代码时获得相当的创意.例如,您可以:
这些功能玩起来很有趣,但是,正如大多数程序员会同意的那样,在阅读别人的作品时,它们通常会使代码更难理解.Go 迫使你坚持基础.这使得阅读任何人的代码并立即了解发生了什么变得非常容易. 注意:当然,它实际上有多"容易"取决于您的用例.如果你想创建一个基本的 CRUD API,我仍然推荐 Django + DRF或 Rails.
Go 的并发方法很容易使用.与 Node 相比,这是一种有趣的方法,开发人员必须密切关注异步代码的处理方式.Go 中并发的另一个重要方面是竞争检测器.这样可以很容易地确定异步代码中是否存在任何竞争条件.
Go 没有像 Rails 用于 Ruby、Django 用于 Python 或 Laravel 用于 PHP 那样的单一主导框架.这是 Go 社区内激烈争论的话题,因为许多人主张你不应该一开始就使用框架.我完全同意这对于某些用例是正确的.但是,如果有人想构建一个简单的 CRUD API,他们将更容易使用 Django/DJRF、Rails Laravel 或Phoenix.对于 Stream 的用例,我们更喜欢不使用框架.然而,对于许多希望提供简单 CRUD API 的新项目来说,缺乏主导框架将是一个严重的劣势.
Go 通过简单地从函数返回错误并期望调用代码来处理错误(或将其返回到调用堆栈)来处理错误.虽然这种方法有效,但很容易失去问题的范围,以确保您可以向用户提供有意义的错误.错误包通过允许您向错误添加上下文和堆栈跟踪来解决此问题.另一个问题是很容易忘记处理错误.像 errcheck 和 megacheck 这样的静态分析工具可以方便地避免犯这些错误.虽然这些变通办法效果很好,但感觉不太对劲.您希望该语言支持正确的错误处理.
Go 的包管理绝不是完美的.默认情况下,它无法指定特定版本的依赖项,也无法创建可重现的构建.Python、Node 和 Ruby 都有更好的包管理系统.但是,使用正确的工具,Go 的包管理工作得很好.您可以使用Dep来管理您的依赖项,以允许指定和固定版本.除此之外,我们还贡献了一个名为的开源工具VirtualGo,它可以更轻松地处理用 Go 编写的多个项目.
我们进行的一个有趣的实验是在 Python 中使用我们的排名提要功能并在 Go 中重写它.看看这个排名方法的例子:
Python 和 Go 代码都需要执行以下操作来支持这种排名方法:
与 Python 相比,我们系统的其他一些组件在 Go 中构建所需的时间要多得多.作为一个总体趋势,我们看到 开发 Go 代码需要更多的努力.但是,我们花更少的时间 优化 代码以提高性能.
我们评估的另一种语言是Elixir..Elixir 建立在 Erlang 虚拟机之上.这是一种迷人的语言,我们之所以考虑它,是因为我们的一名团队成员在 Erlang 方面拥有丰富的经验.对于我们的用例,我们注意到 Go 的原始性能要好得多.Go 和 Elixir 都可以很好地服务数千个并发请求.但是,如果您查看单个请求的性能,Go 对于我们的用例来说要快得多.我们选择 Go 而不是 Elixir 的另一个原因是生态系统.对于我们需要的组件,Go 有更成熟的库,而在许多情况下,Elixir 库还没有准备好用于生产环境.培训/寻找开发人员使用 Elixir 也更加困难.这些原因使天平向 Go 倾斜.Elixir 的 Phoenix 框架看起来很棒,绝对值得一看.
golang 中 map的实现结构为: 哈希表 + 链表. 其中链表,作用是当发生hash冲突时,拉链法生成的结点.
好了,全部的只是静态文件 src/runtime/map.go 中的定义. 实际上编译期间会给它加料 ,动态地创建一个新的结构:
上图就是 bmap的内存模型, HOB Hash 指的就是 top hash. 注意到 key 和 value 是各自放在一起的,并不是 key/value/key/value/... 这样的形式.源码里说明这样的好处是在某些情况下可以省略掉 padding 字段,节省内存空间.
map创建方法:
我们实际上是通过调用的 makemap ,来创建map的.实际工作只是初始化了hmap中的各种字段,如:设置B的大小, 设置hash 种子 hash 0.
注意 :
makemap 返回是*hmap 指针, 即 map 是引用对象, 对map的操作会影响到结构体内部 .
使用方式
对应的是下面两种方法
map的key的类型,实现了自己的hash 方式.每种类型实现hash函数方式不一样.
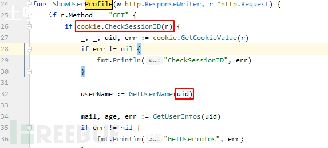
外层遍历bucket 中的链表
建议先不看此部分内容,看完后续 修改 map中元素 - 扩容 操作后 再回头看此部分内容.
扩容前的数据:
等量扩容后的数据:
等量扩容后,查找方式和原本相同, 不多做赘述.
两倍扩容后的数据
两倍扩容后,oldbuckets 的元素,可能被分配成了两部分.查找顺序如下:
使用方式:
步骤如下:
扩容条件 :
扩容的标识 : h.oldbuckets != nil
扩容前:
等量扩容结果
双倍扩容会将old buckets上的元素分配到x, y两个部key 1 B == 0 分配到x部分,key 1 B == 1 分配到y部分
注意: 当前只对双倍扩容描述, 等量扩容只是重新填充了一下元素, 相对位置没有改变.
可以看到,每一遍历生成迭代器的时候,会随机选取一个bucket 以及 一个cell开始. 从前往后遍历,再次遍历到起始位置时,遍历完成.
内核线程(Kernel-Level Thread ,KLT)
轻量级进程(Light Weight Process,LWP):轻量级进程就是我们通常意义上所讲的线程,由于每个轻量级进程都由一个内核线程支持,所以呢只有先支持内核线程,才能有轻量级进程
用户线程与系统线程一一对应,用户线程执行如lo操作的系统调用时,来回切换操作开销相对比较大
多个用户线程对应一个内核线程,当内核线程对应的一个用户线程被阻塞挂起时候,其他用户线程也阻塞不能执行了.
多对多模型是可以充分利用多核CPU提升运行效能的
go线程模型包含三个概念:内核线程(M),goroutine(G),G的上下文环境(P);
GMP模型是goalng特有的.
P与M一般是一一对应的.P(上下文)管理着一组G(goroutine)挂载在M(内核线程)上运行,图中左边蓝色为正在执行状态的goroutine,右边为待执行状态的goroutiine队列.P的数量由环境变量GOMAXPROCS的值或程序运行runtime.GOMAXPROCS()进行设置.
当G1结束后,M1会重新拿回P来完成,如果拿不到就丢到全局runqueue中,然后自己放到线程池或转入休眠状态.空闲的上下文P会周期性的检查全局runqueue上的goroutine,并且执行它.
详细可以翻看下方第一个参考链接,写得真好.
最后用大佬的总结来做最后的收尾――――
Go语言运行时,通过核心元素G,M,P 和 自己的调度器,实现了自己的并发线程模型.调度器通过对G,M,P的调度实现了两级线程模型中操作系统内核之外的调度任务.整个调度过程中会在多种时机去触发最核心的步骤 "一整轮调度",而一整轮调度中最关键的部分在"全力查找可运行G",它保证了M的高效运行(换句话说就是充分使用了计算机的物理资源),一整轮调度中还会涉及到M的启用停止.最后别忘了,还有一个与Go程序生命周期相同的系统监测任务来进行一些辅助性的工作.
浅析Golang的线程模型与调度器
Golang CSP并发模型
Golang线程模型
Goroutine调度是一个很复杂的机制,下面尝试用简单的语言描述一下Goroutine调度机制,想要对其有更深入的了解可以去研读一下源码.
首先介绍一下GMP什么意思:
G ----------- goroutine: 即Go协程,每个go关键字都会创建一个协程.
M ---------- thread内核级线程,所有的G都要放在M上才能运行.
P ----------- processor处理器,调度G到M上,其维护了一个队列,存储了所有需要它来调度的G.
Goroutine 调度器P和 OS 调度器是通过 M 结合起来的,每个 M 都代表了 1 个内核线程,OS 调度器负责把内核线程分配到 CPU 的核上执行
模型图:
避免频繁的创建、销毁线程,而是对线程的复用.
①.)work stealing机制
当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程.
如果有空闲的P,则获取一个P,继续执行G0.
如果没有空闲的P,则将G0放入全局队列,等待被其他的P调度.然后M0将进入缓存池睡眠.
如下图
GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上同时运行
在Go中一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死.
具体可以去看另一篇文章
【Golang详解】go语言调度机制 抢占式调度
当创建一个新的G之后优先加入本地队列,如果本地队列满了,会将本地队列的G移动到全局队列里面,当M执行work stealing从其他P偷不到G时,它可以从全局G队列获取G.
协程经历过程
我们创建一个协程 go func()经历过程如下图:
说明:
G只能运行在M中,一个M必须持有一个P,M与P是1:1的关系.M会从P的本地队列弹出一个可执行状态的G来执行,如果P的本地队列为空,就会想其他的MP组合偷取一个可执行的G来执行;
一个M调度G执行的过程是一个循环机制;会一直从本地队列或全局队列中获取G
上面说到P的个数默认等于CPU核数,每个M必须持有一个P才可以执行G,一般情况下M的个数会略大于P的个数,这多出来的M将会在G产生系统调用时发挥作用.类似线程池,Go也提供一个M的池子,需要时从池子中获取,用完放回池子,不够用时就再创建一个.
work-stealing调度算法:当M执行完了当前P的本地队列队列里的所有G后,P也不会就这么在那躺尸啥都不干,它会先尝试从全局队列队列寻找G来执行,如果全局队列为空,它会随机挑选另外一个P,从它的队列里中拿走一半的G到自己的队列中执行.
如果一切正常,调度器会以上述的那种方式顺畅地运行,但这个世界没这么美好,总有意外发生,以下分析goroutine在两种例外情况下的行为.
Go runtime会在下面的goroutine被阻塞的情况下运行另外一个goroutine:
用户态阻塞/唤醒
系统调用阻塞
当M执行某一个G时候如果发生了阻塞操作,M会阻塞,如果当前有一些G在执行,调度器会把这个线程M从P中摘除,然后再创建一个新的操作系统的线程(如果有空闲的线程可用就复用空闲线程)来服务于这个P.当M系统调用结束时候,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列.如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中,然后这个G会被放入全局队列中.
队列轮转
可见每个P维护着一个包含G的队列,不考虑G进入系统调用或IO操作的情况下,P周期性的将G调度到M中执行,执行一小段时间,将上下文保存下来,然后将G放到队列尾部,然后从队列中重新取出一个G进行调度.
M0
M0是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量rutime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个G,在之后M0就和其他的M一样了
G0
G0是每次启动一个M都会第一个创建的goroutine,G0仅用于负责调度G,G0不指向任何可执行的函数,每个M都会有一个自己的G0,在调度或系统调用时会使用G0的栈空间,全局变量的G0是M0的G0
一个G由于调度被中断,此后如何恢复?
中断的时候将寄存器里的栈信息,保存到自己的G对象里面.当再次轮到自己执行时,将自己保存的栈信息复制到寄存器里面,这样就接着上次之后运行了.
我这里只是根据自己的理解进行了简单的介绍,想要详细了解有关GMP的底层原理可以去看Go调度器 G-P-M 模型的设计者的文档或直接看源码
参考: ()
()