

通过joinback获得销售总额 使用维度进行查询改写
在一个使用维度建模技巧设计的典型数据仓库中,数据中存在着著名的"层次关系".
使用索引,使用精确定位条件筛选,使用子查询将数据量大的表筛选再进行多表连接查询,少使用模糊查询,注意条件的顺序等
①.、建索引.
,尽量让SQL很快的定位,不要走全表查询,尽量走索引
希望对你有用.
①.、使用两边加'%'号的查询,Oracle是不通过索引的,所以查询效率很低.
例如:select count(*) from lui_user_base t where t.user_name like '%cs%';
select count(*) from lui_user_base where rowid in (select rowid from lui_user_base t where t.user_name like '%cs%')
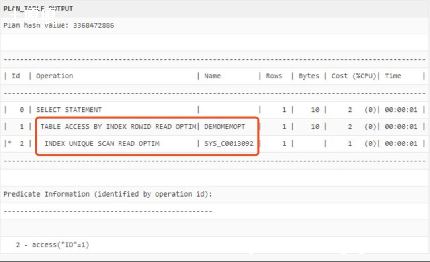
我拿100w跳数据做了测试,效果一般,依然很慢,原因:
select rowid from lui_user_base t where t.user_name like '%cs%' ? 这条sql执行很快,那是相当的快,但是放到select count(*) from lui_user_base where rowid in()里后,效率就会变的很慢了.
这种查询效果很好,速度很快,推荐使用这种.因为我对oracle内部机制不是很懂,只是对结果做了一个说明.
对cmng_custominfo 表中的address字段做全文检索:
BEGIN
ctx_ddl.create_preference ('SMS_ADDRESS_LEXER', 'CHINESE_LEXER');
--ctx_ddl.create_preference ('my_lexer', 'chinese_vgram_lexer'); 不用
end;
CREATE INDEX INX_CUSTOMINFO_ADDR_DOCS ON cmng_custominfo(address) INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS ('LEXER SMS_ADDRESS_LEXER');
select * from cmng_custominfo where contains (address, '金色新城')1;
同步:根据新增记录的文本内容更新全文搜索的索引.
begin
ctx_ddl.sync_index('INX_CUSTOMINFO_ADDR_DOCS');
优化:根据被删除记录清除全文搜索索引中的垃圾
ctx_ddl.optimize_index('INX_CUSTOMINFO_ADDR_DOCS', 'FAST');
①.)该功能需要利用oracle的JOB功能来完成
重新启动oracle数据库服务和listener服务.
--同步 sync:
variable jobno number;
DBMS_JOB.SUBMIT(:jobno,'ctx_ddl.sync_index(''INX_CUSTOMINFO_ADDR_DOCS'');',
commit;
END;
--优化
DBMS_JOB.SUBMIT(:jobno,'ctx_ddl.optimize_index(''INX_CUSTOMINFO_ADDR_DOCS'',''FULL'');', SYSDATE, 'SYSDATE + 1');
重建索引会删除原来的索引,重新生成索引,需要较长的时间.
重建索引语法如下:
ALTER INDEX INX_CUSTOMINFO_ADDR_DOCS REBUILD;
据网上一些用家的体会,oracle重建索引的速度也是比较快的,有一用家这样描述:
所以呢,也可以考虑用job的办法定期重建索引.
以上就是土嘎嘎小编为大家整理的oracle如何查询很快相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!