

Python――Lambda表达式是一个匿名函数,Lambda 表达式基于数学中的lambda演算得名,直接对应于其中的 lambda 抽象,是一个匿名函数,即没有函数名的函数.
Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发.
Python解释器易于扩展,可以使用C或C++(或者其他可以通过C调用的语言)扩展新的功能和数据类型.Python 也可用于可定制化软件中的扩展程序语言.Python丰富的标准库,提供了适用于各个主要系统平台的源码或机器码.

扩展资料:
python的发展历程:
ABC是由Guido参加设计的一种教学语言.就Guido本人看来,ABC这种语言非常优美和强大,是专门为非专业程序员设计的.但是ABC语言并没有成功,究其原因,Guido认为是其非开放造成的.Guido决心在Python中避免这一错误.同时,他还想实现在ABC中闪现过但未曾实现的东西.
正则表达式是一个特殊的字符序列,它用来检查一个字符串是否与某种模式匹配.正则表达式在编译程序中至关重要,但并不是每个人都需要特别深入的学习和掌握.在此,只介绍一些最基本的应用.
①.、元字符
元字符是构成正则表达式的一些特殊字符.在正则表达式中,元字符被赋予了新的含义.
下面介绍一些常用的元字符及其含义:
. 匹配除换行符以外的任意字符.
w 匹配字母、数字、下划线或汉字.
W 匹配w所匹配的字符以外的字符.
s 匹配单个空白符(包括Tab键和换行符).
S 匹配除s匹配的字符以外的字符.
d 匹配数字.
b 匹配单词的分界符,如:空格、标点符号或换行符.
^ 匹配字符串的开始
$ 匹配字符串的结束
限定符是在正则表达式中用来指定数量的字符.常用的限定符有:
匹配前面的字符0或1次.如:zo?m可以匹配zom和zm,但不能匹配 zoom
+ 匹配前面的字符1或n次.如:zo?m可以匹配zom和zoom,但不能匹配zm
* 匹配前面的字符0或n次.如:zo?m可以匹配zom、zoom和zm
{n,} 匹配前面的字符至少n次.如:zo{1,}m可以匹配zom和zoom,但不能匹配zm
方括号"[ ]"里可以列出某个字符范围.如:[aeiou]表示匹配任意一个元音字母,[zqsl]表示匹配姓氏"赵钱孙李"的拼音第一个字母.
方括号"[ ]"中的"^"字符表示排除的意思,如:[^aeiou]表示匹配任意一个非元音字母的字符.
对于已经用于定义元字符和限定符的字符,需要加转义符""来表示.
再加上".": .
其他三段地址和第一段相似.
在正则表达式中,用"( )"括起来的部分是一个整体.
在正则表达式中,为了保证模式字符串为原生字符串(没有经过加工处理的字符串),可以在模式字符串前加上一个字符'r'或'R'.例如:
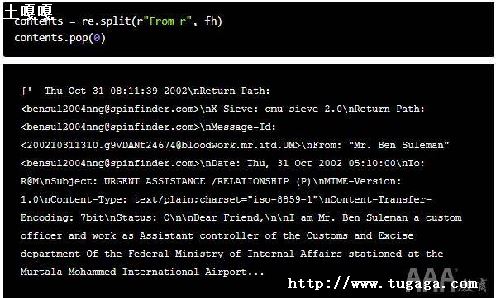
# 这里用到对的re.match()方法此时此刻呢介绍
import re # 导入re模块
re.match('bPy[a-z]+','Python') # 表达式'bPy[a-z]+'不能匹配'Python'
re.match('bPy[a-z]+','Python') # 表达式'bPy[a-z]+'可以匹配'Python'
在上述代码中,原本要用作匹配单词开始或结束的元字符'b'在表达式中字符串中会被视为转义一个字符'b',为了转义'b'就不得不再加一个''符号.
也可以采用下面的方法:
re.match(r'bPy[a-z]+','Python') #加字符'r',可以保证原生字符串
Match()方法 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none.
语法格式:
re.match(pattern, string, [flags])
其中,pattern表示匹配的正则表达式;string是要匹配的字符串;flags表示标志位,用于控制正则表达式的匹配方式,如:re.I表示不区分大小写.
例:
import re #导入re模块
print(re.match('www', '').span()) #span()函数可以获取匹配的位置
print(re.match('org', ''))
输出结果为:
None #从起始位置未能匹配成功
①.0、search()方法
search()方法用于在整个字符串中搜索第一个匹配的值,如果匹配成功,则返回Match对象,否则返回None.
re.search(pattern, string, [flags])
例如:
re.search(r'Pyw+','It's easy to use Python, but it's not easy to learn Python.')
可以看出,目标字符串"It's easy to use Python, but it's not easy to learn Python."中一共有两个'Python',search()方法可以从字符串的起始位置开始查找到'Python',当找到第一个匹配值后就停止查找,返回位置信息.
match()和search()的比较
match()要求目标字符串的起始位置就能匹配,search()对目标字符串全段进行逐次匹配,只要首次匹配成功就停止匹配.
请看下例:
import re
print(re.match(r'Pyw+','It's easy to use Python, but it's not easy to learn Python.'))
输出结果:None
①.1、findall()方法
findall()方法用于在整个字符串中搜索所有匹配的值,如果匹配成功,则返回以匹配值为元素的列表,否则返回空列表.
re.findall(pattern, string[, flags])
print(re.findall(r'Pyw+','It's easy to use Python, but it's not easy to learn Python.'))
输出结果:['Python', 'Python']
可以看出,findall()的结果没有指出匹配的具体位置.
字符串替换
这里要用到sub()方法.它的语法格式如下:
re.sub(pattern, repl, string [,count] [,flgs])
其中,pattern是模式字符串;repl是用于替换的字符串;string是原字符串;可选参数count为模式匹配后替换的最大次数,省缺表示替换所有的匹配;可选参数flags的意义与前面的方法的该参数一致.
分隔字符串
这里要用到split()方法.它的返回值为一个列表,它的语法格式如下:
re.split(pattern, string [,maxsplit] [,flgs])
其中,pattern是模式字符串;string是原字符串;可选参数maxsplit为最大拆分次数,省缺表示拆分所有的匹配;可选参数flags的意义与前面的方法的该参数一致.
str='白日依山尽,黄河入海流.欲穷千里目,更上一层楼!'
re.split(r',|.|!',str) #按照","、"."、"!"分隔字符串.
['白日依山尽', '黄河入海流', '欲穷千里目', '更上一层楼', '']
注意,返回值列表中多出了一个空字符.
①.、函数定义
①使用def关键字定义函数
②
"""文档字符串,docstring,用来说明函数的作用"""
#函数体
return 表达式
注释的作用:说明函数是做什么的,函数有什么功能.
③遇到冒号要缩进,冒号后面所有的缩进的代码块构成了函数体,描述了函数是做什么的,即函数的功能是什么.Python函数的本质与数学中的函数的本质是一致的.
①函数必须先定义,才能调用,否则会报错.
③不要在定义函数的时候在函数体里面调用本身,否则会出不来,陷入循环调用.
④函数需要调用函数体才会被执行,单纯的只是定义函数是不会被执行的.
⑤Debug工具中Step into进入到调用的函数里,Step Into My Code进入到调用的模块里函数.
正则表达式是一个特殊的字符序列,可以帮助您使用模式中保留的专门语法来匹配或查找其他字符串或字符串集. 正则表达式在UNIX世界中被广泛使用.
注:很多开发人员觉得正则表达式比较难以理解,主要原因是缺少使用或不愿意在这上面花时间.
re模块在Python中提供对Perl类正则表达式的完全支持.如果在编译或使用正则表达式时发生错误,则re模块会引发异常re.error.
在这篇文章中,将介绍两个重要的功能,用来处理正则表达式. 然而,首先是一件小事:有各种各样的字符,这些字符在正则表达式中使用时会有特殊的意义. 为了在处理正则表达式时避免混淆,我们将使用:r'expression'原始字符串.
匹配单个字符的基本模式
编译标志可以修改正则表达式的某些方面.标志在re模块中有两个名称:一个很长的名称,如IGNORECASE,和一个简短的单字母形式,如.
①match函数
此函数尝试将RE模式与可选标志的字符串进行匹配.
下面是函数的语法 :
这里是参数的描述 :
pattern : 这是要匹配的正则表达式.
string : 这是字符串,它将被搜索用于匹配字符串开头的模式. |
flags : 可以使用按位OR(|)指定不同的标志. 这些是修饰符,如下表所列.
re.match函数在成功时返回匹配对象,失败时返回None.使用match(num)或groups()函数匹配对象来获取匹配的表达式.
示例
当执行上述代码时,会产生以下结果 :
下面是这个函数的语法 :
re.search函数在成功时返回匹配对象,否则返回None.使用match对象的group(num)或groups()函数来获取匹配的表达式.
Python提供基于正则表达式的两种不同的原始操作:match检查仅匹配字符串的开头,而search检查字符串中任何位置的匹配(这是Perl默认情况下的匹配).
使用正则表达式re模块中的最重要的之一是sub.
模块
此方法使用repl替换所有出现在RE模式的字符串,替换所有出现,除非提供max.此方法返回修改的字符串.
正则表达式文字可能包含一个可选修饰符,用于控制匹配的各个方面. 修饰符被指定为可选标志.可以使用异或(|)提供多个修饰符,如前所示,可以由以下之一表示 :
除了控制字符(+ ? . * ^ $ ( ) [ ] { } | ),所有字符都与其自身匹配. 可以通过使用反斜杠将其转换为控制字符.
字符常量
字符类
特殊字符类
重复匹配
非贪婪重复
这匹配最小的重复次数 :
用圆括号分组
反向引用
这与以前匹配的组再次匹配 :
备择方案
python|perl : 匹配"python"或"perl"
rub(y|le) : 匹配 "ruby" 或 "ruble"
Python(!+|?) : "Python"后跟一个或多个! 还是一个?
锚点
这需要指定匹配位置.
带括号的特殊语法
开课吧广场-人才学习交流平台-开课吧
以上就是土嘎嘎小编为大家整理的关于python函数表达式的信息相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!