

编译 | 荷叶

摘要:深度学习背后的主要原因是人工智能应该从人脑中汲取灵感.本文就用一个小例子无死角的介绍一下深度学习!
人脑模拟
深度学习背后的主要原因是人工智能应该从人脑中汲取灵感.此观点引出了"神经网络"这一术语.人脑中包含数十亿个神经元,它们之间有数万个连接.很多情况下,深度学习算法和人脑相似,因为人脑和深度学习模型都拥有大量的编译单元(神经元),这些编译单元(神经元)在独立的情况下都不太智能,但是当他们相互作用时就会变得智能.
我认为人们需要了解到深度学习正在使得很多幕后的事物变得更好.深度学习已经应用于谷歌搜索和图像搜索,你可以通过它搜索像"拥抱"这样的词语以获得相应的图像.-杰弗里-辛顿
神经元
神经网络的基本构建模块是人工神经元,它模仿了人类大脑的神经元.这些神经元是简单、强大的计算单元,拥有加权输入信号并且使用激活函数产生输出信号.这些神经元分布在神经网络的几个层中.
inputs 输入 outputs 输出 weights 权值 activation 激活
人工神经网络的工作原理是什么?
深度学习由人工神经网络构成,该网络模拟了人脑中类似的网络.当数据穿过这个人工网络时,每一层都会处理这个数据的一方面,过滤掉异常值,辨认出熟悉的实体,并产生最终输出.
输入层:该层由神经元组成,这些神经元只接收输入信息并将它传递到其他层.输入层的图层数应等于数据集里的属性或要素的数量.输出层:输出层具有预测性,其主要取决于你所构建的模型类型.隐含层:隐含层处于输入层和输出层之间,以模型类型为基础.隐含层包含大量的神经元.处于隐含层的神经元会先转化输入信息,再将它们传递出去.随着网络受训练,权重得到更新,从而使其更具前瞻性.
神经元的权重
权重是指两个神经元之间的连接的强度或幅度.你如果熟悉线性回归的话,可以将输入的权重类比为我们在回归方程中用的系数.权重通常被初始化为小的随机数值,比如数值0-1.
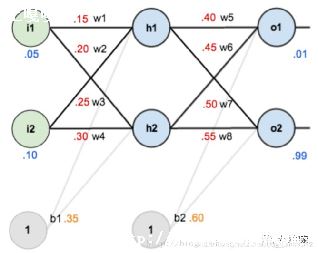
前馈深度网络
前馈监督神经网络曾是第一个也是最成功的学习算法.该网络也可被称为深度网络、多层感知机(MLP)或简单神经网络,并且阐明了具有单一隐含层的原始架构.每个神经元通过某个权重和另一个神经元相关联.
该网络处理向前处理输入信息,激活神经元,最终产生输出值.在此网络中,这称为前向传递.
inputlayer 输入层 hidden layer 输出层 output layer 输出层
激活函数
激活函数就是求和加权的输入到神经元的输出的映射.之所以称之为激活函数或传递函数是因为它控制着激活神经元的初始值和输出信号的强度.
用数学表示为:
我们有许多激活函数,其中使用最多的是整流线性单元函数、双曲正切函数和solfPlus函数.
激活函数的速查表如下:
反向传播
在网络中,我们将预测值与预期输出值相比较,并使用函数计算其误差.然后,这个误差会传回这个网络,每次传回一个层,权重也会根绝其导致的误差值进行更新.这个聪明的数学法是反向传播算法.这个步骤会在训练数据的所有样本中反复进行,整个训练数据集的网络更新一轮称为一个时期.一个网络可受训练数十、数百或数千个时期.
prediction error 预测误差
代价函数和梯度下降
代价函数度量了神经网络对给定的训练输入和预期输出"有多好".该函数可能取决于权重、偏差等属性.
代价函数是单值的,并不是一个向量,因为它从整体上评估神经网络的性能.在运用梯度下降最优算法时,权重在每个时期后都会得到增量式地更新.
兼容代价函数
用数学表述为差值平方和:
target 目标值 output 输出值
权重更新的大小和方向是由在代价梯度的反向上采取步骤计算出的.
其中n 是学习率
其中+w是包含每个权重系数w的权重更新的向量,其计算方式如下:
图表中会考虑到单系数的代价函数
initial weight 初始权重 gradient 梯度 global cost minimum 代价极小值
在导数达到最小误差值之前,我们会一直计算梯度下降,并且每个步骤都会取决于斜率(梯度)的陡度.
多层感知器(前向传播)
这类网络由多层神经元组成,通常这些神经元以前馈方式(向前传播)相互连接.一层中的每个神经元可以直接连接后续层的神经元.在许多应用中,这些网络的单元会采用S型函数或整流线性单元(整流线性激活)函数作为激活函数.
现在想想看要找出处理次数这个问题,给定的账户和家庭成员作为输入
要解决这个问题,首先,我们需要先创建一个前向传播神经网络.我们的输入层将是家庭成员和账户的数量,隐含层数为1, 输出层将是处理次数.
现在将通过以下步骤使用前向传播来计算隐含层(i,j)和输出层(k)的值.
步骤:
①., 乘法-添加方法.
i的值将从相连接的神经元所对应的输入值和权重中计算出来.
Python中的多层感知器问题的解决
激活函数的使用
为了使神经网络达到其最大预测能力,我们需要在隐含层应用一个激活函数,以捕捉非线性.我们通过将值代入方程式的方式来在输入层和输出层应用激活函数.
这里我们使用整流线性激活(ReLU):
用Keras开发第一个神经网络
关于Keras:
Keras是一个高级神经网络的应用程序编程接口,由Python编写,能够搭建在TensorFlow,CNTK,或Theano上.
使用PIP在设备上安装Keras,并且运行下列指令.
在keras执行深度学习程序的步骤
①.,加载数据;
开发Keras模型
全连接层用Dense表示.我们可以指定层中神经元的数量作为第一参数,指定初始化方法为第二参数,即初始化参数,并且用激活参数确定激活函数.既然模型已经创建,我们就可以编译它.我们在底层库(也称为后端)用高效数字库编译模型,底层库可以用Theano或TensorFlow.目前为止,我们已经完成了创建模型和编译模型,为进行有效计算做好了准备.现在可以在PIMA数据上运行模型了.我们可以在模型上调用拟合函数f(),以在数据上训练或拟合模型.
我们先从KERAS中的程序开始,
从零开始用Python构建神经网络
动机:为了更加深入的理解深度学习,我们将使用 python 语言从头搭建一个神经网络,而不是使用像 Tensorflow 那样的封装好的框架.我认为理解神经网络的内部工作原理,对数据科学家来说至关重要.
这篇文章的内容是我的所学,希望也能对你有所帮助.
神经网络是什么?
介绍神经网络的文章大多数都会将它和大脑进行类比.如果你没有深入研究过大脑与神经网络的类比,那么将神经网络解释为一种将给定输入映射为期望输出的数学关系会更容易理解.
神经网络包括以下组成部分
一个输入层,x
任意数量的隐藏层
一个输出层,?
每层之间有一组权值和偏置,W and b
为隐藏层选择一种激活函数,q.在教程中我们使用 Sigmoid 激活函数
用 Python 可以很容易的构建神经网络类
训练神经网络
这个网络的输出 ? 为:
你可能会注意到,在上面的等式中,输出 ? 是 W 和 b 函数.
所以呢 W 和 b 的值影响预测的准确率. 所以根据输入数据对 W 和 b 调优的过程就被成为训练神经网络.
每步训练迭代包含以下两个部分:
计算预测结果 ?,这一步称为前向传播
更新 W 和 b,,这一步成为反向传播
下面的顺序图展示了这个过程:
前向传播
我们在 NeuralNetwork 类中增加一个计算前向传播的函数.为了简单起见我们假设偏置 b 为0:
但是我们还需要一个方法来评估预测结果的好坏(即预测值和真实值的误差).这就要用到损失函数.
损失函数
常用的损失函数有很多种,根据模型的需求来选择.在本教程中,我们使用误差平方和作为损失函数.
误差平方和是求每个预测值和真实值之间的误差再求和,这个误差是他们的差值求平方以便我们观察误差的绝对值.
训练的目标是找到一组 W 和 b,使得损失函数最好小,也即预测值和真实值之间的距离最小.
我们已经度量出了预测的误差(损失),现在需要找到一种方法来传播误差,并以此更新权值和偏置.
为了知道如何适当的调整权值和偏置,我们需要知道损失函数对权值 W 和偏置 b 的导数.
回想微积分中的概念,函数的导数就是函数的斜率.
梯度下降法
如果我们已经求出了导数,我们就可以通过增加或减少导数值来更新权值 W 和偏置 b(参考上图).这种方式被称为梯度下降法.
但是我们不能直接计算损失函数对权值和偏置的导数,因为在损失函数的等式中并没有显式的包含他们.所以呢,我们需要运用链式求导发在来帮助计算导数.
链式法则用于计算损失函数对 W 和 b 的导数.注意,为了简单起见.我们只展示了假设网络只有 1 层的偏导数.
这虽然很简陋,但是我们依然能得到想要的结果―损失函数对权值 W 的导数(斜率),所以呢我们可以相应的调整权值.
现在我们将反向传播算法的函数添加到 Python 代码中
Youtube:
整合并完成一个实例
既然我们已经有了包括前向传播和反向传播的完整 Python 代码,那么就将其应用到一个例子上看看它是如何工作的吧.
神经网络可以通过学习得到函数的权重.而我们仅靠观察是不太可能得到函数的权重的.
我们成功了!我们应用前向和方向传播算法成功的训练了神经网络并且预测结果收敛于真实值.
注意预测值和真实值之间存在细微的误差是允许的.这样可以防止模型过拟合并且使得神经网络对于未知数据有着更强的泛化能力.
下一步是什么?
幸运的是我们的学习之旅还没有结束,仍然有很多关于神经网络和深度学习的内容需要学习.例如:
除了 Sigmoid 以外,还可以用哪些激活函数
在训练网络的时候应用学习率
在面对图像分类任务的时候使用卷积神经网络
我很快会写更多关于这个主题的内容,敬请期待!
最后的想法
我自己也从零开始写了很多神经网络的代码
虽然可以使用诸如 Tensorflow 和 Keras 这样的深度学习框架方便的搭建深层网络而不需要完全理解其内部工作原理.但是我觉得对于有追求的数据科学家来说,理解内部原理是非常有益的.
这种练习对我自己来说已成成为重要的时间投入,希望也能对你有所帮助
线性回归是一种用于预测真实值的方法.让人困惑的是,这些需要预测真实值的问题被称为回归问题(regression problems).线性回归是一种用直线对输入输出值进行建模的方法.在超过二维的空间里,这条直线被想象成一个平面或者超平面(hyperplane).预测即是通过对输入值的组合对输出值进行预判.
import sys
#Training data set
epsilon = 0.0001
#learning rate
alpha = 0.01
diff = [0,0]
max_itor = 1000
error1 = 0
error0 =0
cnt = 0
m = len(x)
#init the parameters to zero
theta0 = 0
theta1 = 0
while True:
cnt = cnt + 1
#calculate the parameters
for i in range(m):
theta0 = theta0 + alpha * diff[0] * x[i][0]
theta1 = theta1 + alpha * diff[0]* x[i][1]
#calculate the cost function
for lp in range(len(x)):
if abs(error1-error0) epsilon:
break
else:
error0 = error1
如果把神经网络模型比作一个黑箱,把模型参数比作黑箱上面一个个小旋钮,那么根据通用近似理论(universal approximation theorem),只要黑箱上的旋钮数量足够多,而且每个旋钮都被调节到合适的位置,那这个模型就可以实现近乎任意功能(可以逼近任意的数学模型).
显然,这些旋钮(参数)不是由人工调节的,所谓的机器学习,就是通过程序来自动调节这些参数.神经网络不仅参数众多(少则十几万,多则上亿),而且网络是由线性层和非线性层交替叠加而成,上层参数的变化会对下层的输出产生非线性的影响,所以呢,早期的神经网络流派一度无法往多层方向发展,因为他们找不到能用于任意多层网络的、简洁的自动调节参数的方法.
梯度下降法是一种将输出误差反馈到神经网络并自动调节参数的方法,它通过计算输出误差的loss值( J )对参数 W 的导数,并沿着导数的反方向来调节 W ,经过多次这样的操作,就能将输出误差减小到最小值,即曲线的最低点.
虽然Tensorflow、Pytorch这些框架都实现了自动求导的功能,但为了彻底理解参数调节的过程,还是有必要自己动手实现梯度下降和反向传播算法.我相信你和我一样,已经忘了之前学的微积分知识,所以呢,到可汗学院复习下 Calculus
和 Multivariable Calculus 是个不错的方法,或是拜读 这篇关于神经网络矩阵微积分的文章 .
如果你不想涉及这些求导的细节,可以跳过具体的计算,领会其思想就好.
对于神经网络模型: Linear - ReLu - Linear - MSE(Loss function) 来说,反向传播就是根据链式法则对 求导,用输出误差的均方差(MSE)对模型的输出求导,并将导数传回上一层神经网络,用于它们来对 w 、 b 和 x (上上层的输出)求导,再将 x 的导数传回到它的上一层神经网络,由此将输出误差的均方差通过递进的方式反馈到各神经网络层.
对于 求导的第一步是为这个函数链引入中间变量:
接着第二步是对各中间变量求导,最后才是将这些导数乘起来.
首先,反向传播的起点是对loss function求导,即 . :
mse_grad()之所以用unsqueeze(-1)给导数增加一个维度,是为了让导数的shape和tensor shape保持一致.
linear层的反向传播是对 求导,它也是一个函数链,也要先对中间变量求导再将所有导数相乘:
这些中间变量的导数分别是:
对向量 求导,指的是对向量所有的标量求偏导( ),即: ,这个横向量也称为y的梯度.
.
这个矩阵称为雅克比矩阵,它是个对角矩阵,因为 ,所以呢 .
同理, .
所以呢,所有中间导数相乘的结果:
lin_grad() 中的inp.g、w.g和b.g分别是求 的导数,以inp.g为例,它等于 ,且需要乘以前面各层的导数,即 outp.g @ w.t() ,之所以要用点积运算符(@)而不是标量相乘,是为了让它的导数shape和tensor shape保持一致.同理,w.g和b.g也是根据相同逻辑来计算的.
ReLu层的求导相对来说就简单多了,当输入 = 0时,导数为0,当输入 0时,导数为1.
求导运算终于结束了,此时此刻呢就是验证我们的反向传播是否正确.验证方法是将forward_backward()计算的导数和Pytorch自动微分得到的导数相比较,如果它们相近,就认为我们的反向传播算法是正确的.
最后,用np.allclose()来比较导数间的差异,如果有任何一个导数不相近,assert就会报错.结果证明,我们自己动手实现的算法是正确的.
反向传播是遵循链式法则的,它将前向传播的输出作为输入,输入作为输出,通过递进的方式将求导这个动作从后向前传递回各层.神经网络参数的求导需要进行矩阵微积分计算,根据这些导数的反方向来调节参数,就可以让模型的输出误差的优化到最小值.
欢迎关注和点赞,你的鼓励将是我创作的动力
Python实现简单多线程任务队列
最近我在用梯度下降算法绘制神经网络的数据时,遇到了一些算法性能的问题.梯度下降算法的代码如下(伪代码):
defgradient_descent(): # the gradient descent code plotly.write(X, Y)
一般来说,当网络请求 plot.ly 绘图时会阻塞等待返回,于是也会影响到其他的梯度下降函数的执行速度.
一种解决办法是每调用一次 plotly.write 函数就开启一个新的线程,但是这种方法感觉不是很好. 我不想用一个像 cerely(一种分布式任务队列)一样大而全的任务队列框架,因为框架对于我的这点需求来说太重了,并且我的绘图也并不需要 redis 来持久化数据.
那用什么办法解决呢?我在 python 中写了一个很小的任务队列,它可以在一个单独的线程中调用 plotly.write函数.下面是程序代码.
fromthreadingimportThreadimportQueueimporttime classTaskQueue(Queue.Queue):
首先我们继承 Queue.Queue 类.从 Queue.Queue 类可以继承 get 和 put 方法,以及队列的行为.
def__init__(self, num_workers=1): Queue.Queue.__init__(self) self.num_workers=num_workers self.start_workers()
初始化的时候,我们可以不用考虑工作线程的数量.
defadd_task(self, task,*args,**kwargs): args=argsor() kwargs=kwargsor{} self.put((task, args, kwargs))
我们把 task, args, kwargs 以元组的形式存储在队列中.*args 可以传递数量不等的参数,**kwargs 可以传递命名参数.
defstart_workers(self): foriinrange(self.num_workers): t=Thread(target=self.worker) t.daemon=True t.start()
我们为每个 worker 创建一个线程,然后在后台删除.
下面是 worker 函数的代码:
defworker(self): whileTrue: tupl=self.get() item, args, kwargs=self.get() item(*args,**kwargs) self.task_done()
worker 函数获取队列顶端的任务,并根据输入参数运行,除此之外,没有其他的功能.下面是队列的代码:
我们可以通过下面的代码测试:
Blokkah 是我们要做的任务名称.队列已经缓存在内存中,并且没有执行很多任务.下面的步骤是把主队列当做单独的进程来运行,这样主程序退出以及执行数据库持久化时,队列任务不会停止运行.但是这个例子很好地展示了如何从一个很简单的小任务写成像工作队列这样复杂的程序.
defgradient_descent(): # the gradient descent code queue.add_task(plotly.write, x=X, y=Y)
以上就是土嘎嘎小编为大家整理的梯度下降函数python相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!