

call sp_add();
是不是你定义的过程有问题吧,并没有指出返回结果来
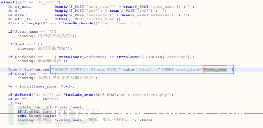
像我这样是可以的:
CREATE PROCEDURE sp_add(a int, b int,out c int)
begin
set c=a+ b;
end;
调用过程:
select @a;
create function 函数名称(参数列表)
reurns 返回值类型
函数体
执行的方法很简单:
加载
** create function 函数名称 returns {string|real|integer}
** soname 你定义的动态库位置
释放!
** drop function 函数名称
打开你的navicat for mysql.不清楚的同学请看下图.
在打开的界面上的工具栏处,找到"query"工具,单击.
打开你要操作的数据库,eg:我要操作:本地>> webdb
找到变亮的New Query ,单击打开.弹出一个窗口.
这里说明一下,窗口中有两个tab窗口,一个是Query Editor,另一个是Query Builder.前者是需要自己手动写sql语句,后者者可以通过可视化操作,生成sql语句.快去亲自试试吧!
如果对你有用请单击"有用".谢谢.
调用如:select 函数名(参数列表).
mysql中的UDF(自定义函数),可以写好一些方法或?函数,然后进行调用,而且是在SQL语句中可以进行调用.?
DROP FUNCTION CalculateAmount?
BEGIN?
DECLARE totalCredits FLOAT;?
SELECT SUM(amount) INTO totalAmount FROM credit_user WHERE id =userid;?
RETURN totalAmount;?
END?
要注意的是,在UDF中,不要定义与数据表中重名的列.而在SQL中,?则可以像SELECT CalculateAmount(1);那样去调用了.
序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
分布函数:PERCENT_RANK()、CUME_DIST()
前后函数:LAG()、LEAD()
头尾函数:FIRST_VALUE()、LAST_VALUE()
其它函数:NTH_VALUE()、NTILE()
例子:
首先有一个表字段:id score(分数)user_id
①序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
用途:显示分区中的当前行号,对查询结果进行排序.
执行sql:
用途:每行按照公式(rank-1) / (rows-1)进行计算.其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数
LAG和LEAD分析函数可以在同一次查询中取出同一字段的前N行的数据(LAG)和后N行的数据(LEAD)作为独立的列
在实际应用当中,若要用到取今天和昨天的某字段差值时,LAG和LEAD函数的应用就显得尤为重要.当然,这种操作可以用表的自连接实现,但是LAG和LEAD与LEFT JOIN、RIGHT JOIN等自连接相比,效率更高,SQL更简洁.下面我就对这两个函数做一个简单的介绍.
函数语法如下:
lag(exp_str,offset,defval) OVER(PARTITION BY ...ORDER BY ...)
lead(exp_str,offset,defval) OVER(PARTITION BY ...ORDER BY ...)
参数说明:
exp_str是字段名
defval默认值,当两个函数取上N/下N个值,当在表中从当前行位置向前数N行已经超出了表的范围时,LAG()函数将defval这个参数值作为函数的返回值,若没有指定默认值,则返回NULL,那么在数学运算中,总要给一个默认值才不会出错.
注意:这里是序号的上一条或下一条
用途:返回第一个(FIRST_VALUE(expr))或最后一个(LAST_VALUE(expr))expr的值
FIRST_VALUE()的结果容易理解,直接在结果的所有行记录中输出同一个满足条件的首个记录;
LAST_VALUE()默认统计范围是 rows between unbounded preceding and current row,也就是取当前行数据与当前行之前的数据的比较.
那么如果我们直接在每行数据中显示最后的那个数据,需在order by 条件的后面加上语句: rows between unbounded preceding and unbounded following , 也就是前面无界和后面无界之间的行比较.
加上语句,执行sql:
结果:
简单理解就是,取最大的还是最小的结合ORDER BY使用,或者取第一个还是或者最后一个
参考: ;wfr=spiderfor=pc
① 建立MySQL 连接:mysql_connect
resource mysql_connect([string $server[, string $username [, string $password [, bool $new_link [, int $client flags]]]]])
打开或重复使用一个到MySQL服务器的连接.其中,server代表MySQL服务器,可以包括端口号,例如"hostname:port".username和password分别代表登录MySQL服务器使用的用户名和密码.
bool mysql_select_db(string $database_name[, resource $link_identifier])
设定与指定的连接标识符所关联的服务器上的当前数据库.如果没有指定连接标识符,则使用上一个打开的连接.如果没有打开的连接,本函数将无参数地调用mysql_connect()来尝试打开一个数据库连接.如果成功则返回true,失败则返回false.每个其后的mysgl_query()调用都会作用于活动数据库.
resource mysql_query(string $query[, resource $link_identifier])
向与指定的连接标识的关联的服务器中的当前活动数据库发送一条查询.如果没有指定 link_identifier,则使用上一个打开的连接.如果没有打开的连接,本函数会尝试无参数地调用mysql_connect()函数来建立一个连接,查询结果会被缓存.mysql_query()仅对SELECT、SHOW、EXPLAIN或DESCRIBE语句返回一个资源标识符,如果查询执行不正确则返回false.对于其他类型的SQL语句,mysgl_query()在执行成功时返回true,出错时返回false.非false的返回值意味着查询是合法的并能够被服务器执行但是并不说明任何影响到的或返回的行数.因为一条查询执行成功了但并未影响到或并未返回任何行的情况是可能发生的.
array mysql_fetch_row(resource $result)
从和指定的结果标识关联的结果集中取得一行数据并作为数组返回.每个结果的列储存在一个索引数组的单元中,偏移量从0开始.依次调用mysql_fetch_row()将返回结果集中的下一行,如果没有更多行则返回false.
array mysql_fetch_array(resource $result[, int $result_type])
mysql_fetch_row()的扩展版本.除了将数据以数字索引方式储存在数组中之外,还可以将数据作为关联索引储存,用字段名作为键名.如果结果中出现字段名重名的现象,最后一列将优先.要访问同名的其他列,必须用该列的数字索引或给该列起个别名.对有别名的列,用别名来访问其内容.
bool mysql_close([resource $link_identifier])
mysql_close()关闭指定的连接标识所关联的到MySQL服务器的非持久连接.如果没有指定link_identifier,则关闭上一个打开的连接.
例PHP中使用MySQL数据库(mysql.php)
php//连接MySQL数据库
//选择当前数据库
//等效为执行USE test
mysql_select_db('test');
//在当前数据库执行SQL语句
$query = "SELECT * FROM students";
$result = mysql_query($query);
//操作上次查询返回的结果集,注意$result变量一般是需要的
while($student = mysql_fetch_array($result)) {
echo 'pre';
print_r($student);
echo '/pre';
}
以上就是土嘎嘎小编为大家整理的mysql怎么执行函数相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!