

这个问题要具体分析:
第一,事务隔离级别基本两种模式,一种是阻塞式(read committed,repeatable read,serializable)
,一种是非阻塞式(read uncommitted,snapshot).
默认是read committed,这种情况一般在更新表的时候,如果不使用hint 提示,基本是先对表添加IX锁,级别不算高,基本和其他锁兼容,但是repeatable read,serializable 事务隔离级别就会先对表添加IX锁,然后向X锁转化,而X锁和大多数锁都不兼容,容易发生表阻塞.
第二种隔离级别不会有以上问题,但是又引入了其它的问题.
好了,全部的一种情况.
所以适当的文件分组和表分区 是有必要的.
留个问题你自己去想.
两个SQL,两个连接,同时执行.
SQL SERVER里的锁机制:
NOLOCK(不加锁)
此选项被选中时,SQL Server 在读取或修改数据时不加任何锁. 在这种情况下,用户有可能读取到未完成事务(Uncommited Transaction)或回滚(Roll Back)中的数据, 即所谓的"脏数据".
HOLDLOCK(保持锁)
此选项被选中时,SQL Server 会将此共享锁保持至整个事务结束,而不会在途中释放. 例如," SELECT * FROM my_table HOLDLOCK"就要求在整个查询过程中,保持对表的锁定,直到查询完成才释放锁定.
UPDLOCK(修改锁)
此选项被选中时,SQL Server 在读取数据时使用修改锁来代替共享锁,并将此锁保持至整个事务或命令结束.使用此选项能够保证多个进程能同时读取数据但只有该进程能修改数据.
TABLOCK(表锁)
此选项被选中时,SQL Server 将在整个表上置共享锁直至该命令结束. 这个选项保证其他进程只能读取而不能修改数据.
PAGLOCK(页锁)
此选项为默认选项, 当被选中时,SQL Server 使用共享页锁.
TABLOCKX(排它表锁)
此选项被选中时,SQL Server 将在整个表上置排它锁直至该命令或事务结束.这将防止其他进程读取或修改表中的数据.
:您好!锁是数据库中的一个非常重要的概念,它主要用于多用户环境下保证数据库完整性和一致性. 我们知道,多个用户能够同时操纵同一个数据库中的数据,会发生数据不一致现象.即如果没有锁定且多个用户同时访问一个数据库
死锁,简而言之,两个或者多个trans,同时请求对方正在请求的某个对象,导致双方互相等待.简单的例子如下:
------------------------------------------------------------------------
①IDBConnection.BeginTransaction 1.IDBConnection.BeginTransaction
好,我们看一个简单的例子,来解释一下,应该如何解决死锁问题.
-- Batch #1
CREATE DATABASE deadlocktest
GO
USE deadlocktest
SET NOCOUNT ON
IF OBJECT_ID ('t1') IS NOT NULL DROP TABLE t1
IF OBJECT_ID ('p1') IS NOT NULL DROP PROC p1
DECLARE @x int
SET @x = 1
WHILE (@x = 1000) BEGIN
SET @x = @x + 1
END
CREATE CLUSTERED INDEX cidx ON t1 (c1)
好,打开一个新的查询窗口,我们开始执行下面的query:
开始执行后,然后我们打开第三个查询窗口,执行下面的query:
WHILE (1=1) BEGIN
TRUNCATE TABLE #t1
开始执行,哈哈,很快,我们看到了这样的错误信息:
那么,我们该如何解决它?
这种方式,我们可以解决大部分的Sql Server死锁问题.那么,发生这个死锁的根本原因是什么呢?为什么增加一个non clustered index,问题就解决了呢? 这次,我们分析一下,为什么会死锁呢?再回顾一下两个sp的写法:
CREATE PROC p1 @p1 int AS
那么,什么导致了死锁?
需要从事件日志中,看sql的死锁信息:
The SELECT is waiting for a Shared KEY lock on index t1.cidx. The UPDATE holds a conflicting X lock.
The UPDATE is waiting for an eXclusive KEY lock on index t1.idx1. The SELECT holds a conflicting S lock.
首先,我们看看p1的执行计划.怎么看呢?可以执行set statistics profile on,这句就可以了.下面是p1的执行计划
|--Top(ROWCOUNT est 0)
|--Clustered Index Seek(OBJECT:([t1].[cidx]), SEEK:([t1].[c1]=[@p1]) ORDERED FORWARD)
通过聚集索引的seek找到了一行,然后开始更新.这里注意的是,update的时候,它会申请一个针对clustered index的X锁的.
SO.........,问题就这样被发现了.
最后提醒一下大家,就是说,某个query使用非聚集索引来select数据,那么它会在非聚集索引上持有一个S锁.当有一些select的列不在该索引上,它需要根据rowid找到对应的聚集索引的那行,然后找到其他数据.而此时,第二个的查询中,update正在聚集索引上忙乎:定位、加锁、修改等.但因为正在修改的某个列,是另外一个非聚集索引的某个列,所以此时,它需要同时更改那个非聚集索引的信息,这就需要在那个非聚集索引上,加第二个X锁.select开始等待update的X锁,update开始等待select的S锁,死锁,就这样发生鸟.
那么,为什么我们增加了一个非聚集索引,死锁就消失鸟?我们看一下,按照上文中自动增加的索引之后的执行计划:
哦,对于clustered index的需求没有了,因为增加的覆盖索引已经足够把所有的信息都select出来.就这么简单.
下面的方法,有助于将死锁减至最少(详细情况,请看SQLServer联机帮助,搜索:将死锁减至最少即可.
按同一顺序访问对象.
避免事务中的用户交互.
保持事务简短并处于一个批处理中.
使用较低的隔离级别.
使用基于行版本控制的隔离级别.
将 READ_COMMITTED_SNAPSHOT 数据库选项设置为 ON,使得已提交读事务使用行版本控制.
使用快照隔离.
使用绑定连接.
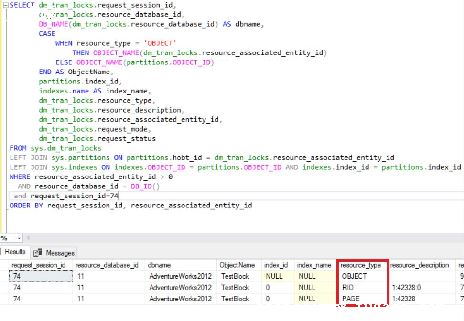
①.、首先需要判断是哪个用户锁住了哪张表.
查询被锁表
select?request_session_id?spid,OBJECT_NAME(resource_associated_entity_id)?tableName?
from?sys.dm_tran_locks?where?resource_type='OBJECT'
查询后会返回一个包含spid和tableName列的表.
其中spid是进程名,tableName是表名.
查询主机名
xxx就是spid列的进程,检索后会列出很多信息,其中就包含主机名.
关闭进程
exec(@sql)
PS:有些时候强行杀掉进程是比较危险的,所以最好可以找到执行进程的主机,在该机器上关闭进程.