

outname = "outname.cst"
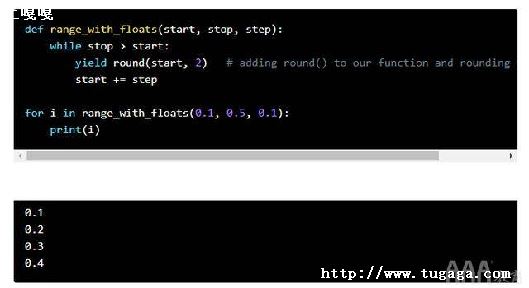
# �ڴ˴����øú���.�����嶨�������ڵ�����ǰ.����ͨ��import
read_ESRT_......(file = inname, fileOut = outname)
# ����������ֻ���ַ�������,ָ������ļ�·��.ע����python��,���� \ ��,�����ʹ�� \\ ˫б��,����������,����ǰ r
python�ĺ�������������"���ô��ݣ���ַ���ݣ�".
python�и�ֵ���Ĺ��̣�x = 1����������һ���ڴ�����һ�����Ͷ������洢����1,Ȼ���ñ���xȥָ���������,ʵ���Ͼ���ָ������ڴ棨�����е��C�����е�ָ�����ƣ�.
��Python��,��Ϊÿ���������һ�����ű�,����ܵ�������еı���,����㲻�ܵ�������еı���,���ҵ����������ͬ������ʱ,�������ᱻ���������ε�.����? ���� ?��Ϊ�����ֲ���������һ���µķ��ű�.
�ֲ������������ڸú����ڲ�,һ������ִ�����,�ñ����ͱ�����.
ȫ�ֱ����������ں����ⲿ�����,�������������ļ�.ȫ�ֱ�������ֱ���ں�������Ӧ��,�������Ҫ�ں����ڲ��ı�ȫ�ֱ���,����ʹ��global�ؼ��ֽ�������.
ע�� ��Ĭ��ֵ�ں���? ���� ?��������
�ڶ��庯��ʱ,���Ѿ�ִ�������ľֲ�����
python�в��ɱ������ǹ����ڴ��ַ�ģ�����ͬ���������ɱ��������ݸ���������ͬ����a,b,a,b���ڴ��еĵ�ַ��һ����.
��Ԫ���ԣ�Unit Testing��
Ϊ�����д���ԡ���������ĵ�λ���������ڼ���bug�ij���,������������ǶԳ���Ԥ��Ŀ�����е�����.ͨ��,���Բ����ܱ�֤��ȷ��,��Ϊ�Դ�����������, ���ܵ����뷶Χ�Լ����ܵļ��㷶Χ�����֮��,ֻ��������С��һ�����ܱ�ʵ�ʵؽ� �в���.�������,ͨ����ϸ��ѡ����Եķ�����Ŀ��,������ߴ��������.
������ͬ���͵IJ��Զ����Խ���,��������Բ��ԡ����ܲ����Լ����ϲ��Ե�.����, ����ֻ����Ԫ����һ�Ե����ĺ��������뷽�����в���,ȷ�������Ԥ�ڵ���Ϊ.
TDD��һ���ؼ�����,������������һ������ʱ��������Ϊ������һ���������� �����״�Ϊ���дһ����������.��Ȼ,���Խ�ʧ��,��Ϊ���ǻ�û��ʵ�ʱ�д�÷���.����,���DZ�д�÷���,һ������ͨ���˲���,�Ϳ��Է������в���,ȷ�����������ӵĴ���û���κ�Ԥ����ĸ�����.һ�����в���������ϣ���������Ϊ�¹��ܱ�д�IJ��ԣ�,�Ϳ��Զ����ǵĴ�����м��,�������оݵ����ų�����Ϊ�������ǵ�����������Ȼ,ǰ�������ǵIJ������ʵ���.
����,���DZ�д��һ������,�ú������ض�������λ�ò���һ���ַ���,����������������ʼ���ǵ�TDD��
def insert_at��string, position, insert��:
"""Returns a copy of string with insert inserted at the position
string = "ABCDE"
result =[]
... result.append(insert_at(string, i,"-"))
['ABC-DE', 'ABCD-E', '-ABCDE','A-BCDE', 'AB-CDE']
['ABC-DE', 'ABCD-E', 'ABCDE-', 'ABCDE-']
"""
return string
�Բ������κβ����ĺ�������ͨ������None��,����ͨ����������pass���ɵ�һ��suite,����Щ����ֵ�����õ�,���ǻ��߷���һ������������0��,����ij������IJ���������Ҳ����������������.���ڸ����ӵ������,����fake������ܸ�����һһ����������,�ṩmock����ĵ�����ģ���ǿ��õ�.��
����doctestʱ��ʧ��,���г�ÿ��Ԥ���ڵ��ַ�����'ABCD-EF'��'ABCDE-F' �ȣ�,����ʵ�ʻ�ȡ���ַ��������еĶ���'ABCD-EF'��.һ��ȷ��doctest�dz�ֵĺ���ȷ��,�Ϳ��Ա�д�ú��������岿��,�ڱ�����ֻ�Ǽ�return string[:position] + insert+string[position:].��������DZ�д���� return string[:position] + insert,֮���� string [:position]������ճ����ĩβ�Ա����һЩ�������,��ôdoctest��������ʾ����.��
Python�ı����ṩ��������Ԫ����ģ��,һ����doctest,�����ǰ�涼���ᵽ��,��һ����unittest.����,����һЩ������Python�ĵ��������Թ���.������������������nose (code.google.com/p/python-nose)��py.test (codespeak.net/py/dist/test/test.html), nose �������ṩ�ȱ���unittest ģ����㷺�Ĺ���,ͬʱ�������ģ��ļ�����,py.test���������unittest��Щ��ͬ�ķ���,��ͼ����������������Դ���.������������ģ�鶼֧�ֲ��Է���,������û��Ҫдһ������IJ��Գ�����Ϊģ�齫�Լ��������Գ���.��ʹ�ò���������������ijһ���� (������Щ�Ѿ������õ�ģ��)��ú�����.��Щ�Բ������ع��е���,�ھ���ʹ���ĸ����Թ���֮ǰ,��������(�Լ��κ���������������)������ģ������о�����ֵ �õ�.
if __name__ =="__main__":
import doctest
doctest.testmod()
�ڳ����ڲ�ʹ��doctestҲ�ǿ��ܵ�.����,blocks.py����(��ģ���ں���)���Լ�������doctest,�������´����β��
if __name__== "__main__":
main()
��һ��ִ��doctest�ķ�����ʹ��unittestģ�鴴�������IJ��Գ���.�ڸ�����, unittestģ���Ǹ���Java��JUnit��Ԫ���Կ���н�ģ��,�����ڴ����������������IJ�����.unittestģ����Ի���doctests������������,������Ҫ֪�������ģ��������κ������ֻҪ֪�������doctest����.������,Ϊ��blocks.py��������һ��������,���ǿ��Դ������µļ���(�����Ϊtest_blocks.py)��
import unittest
import blocks
suite = unittest.TestSuite()
suite.addTest(doctest.DocTestSuite(blocks))
runner = unittest.TextTestRunner()
print(runner.run(suite))
ע��,���������ַ���,����������ϻ���һ��������Լ������������������Ч��ģ����.������,��Ϊconvert-incidents.py�ij���IJ��Բ���д������.��Ϊimport convert-incidents������Ч��,��Python��ʶ����,���ӷ�����Ч�ģ��ܿ���һԼ���ǿ��ܵ�,����Ľ��������ʹ��������Чģ�����ij����ļ���,����,ʹ���»����滻���ӷ���.����չʾ�Ľṹ������һ��������,����һ���������������������,��������IJ�����,���������ǵ��͵Ļ���unittest�IJ���.����ʱ,��һ�ض�ʵ���������½����
...
.............................................................................................................
OK
������dz��Խ����Է��뿪�������������Ҫ���Ե�ÿ�������ģ�鶼��һ������������,�Ͳ�Ҫ��ʹ��doctests,����ֱ��ʹ��unittestģ��Ĺ��ܡ�������������ϰ����ʹ��JUnit�������в���ʱounittestģ��Ὣ���Է����ڴ��롪���Դ�����Ŀ�����Ա�д��Ա�뿪����Ա���ܲ�һ�£�����,���ַ����ر�����.����,unittest��Ԫ���Ա�дΪ������Pythonģ��,������,��������docstring�ڲ���д��������ʱ�ܵ������Ժ������Ե�����.
���������,��������ͨ������unittest.TestCase������ʵ�ֵ�,����ÿ������ ��"test"��ͷ�ķ�������һ����������.���������Ҫ����κδ�������,�Ϳ�����һ����ΪsetUp()�ķ�����ʵ�֣����Ƶ�,���κ���������,Ҳ����ʵ��һ����Ϊ tearDown()�ķ���.�ڲ����ڲ�,�д����ɹ�����ʹ�õ�unittest.TestCase����,���� assertTrue()��assertEqual()��assertAlmostEqual()�����ڲ��Ը����������ã���assertRaises() �Լ�����,�������ܶ��Ӧ���淽��,����assertFalse()��assertNotEqual()��failIfEqual()�� failUnlessEqual ()��.
�ṹ�Ͽ�,���Բ�ͬ��������ʵ������һ����,������,���ǽ�ֻΪ�����б���д��������,����������������ϰ.test_Atomic.pyģ����뵼��unittestģ����Ҫ���в��Ե�Atomicģ��.
����unittest�ļ�ʱ,����ͨ����������ģ����dz���.��ÿ��ģ���ڲ�,���Ƕ���һ������unittest.TestCase����.����,test_Atomic.pyģ���н�һ�������� unittest-TestCase����,Ҳ����TestAtomic (�Ժ�����н���),�����������н���:
if name == "__main__":
unittest.main()
������ʹ�ø�ģ����Ե�������.��Ȼ,��ģ��Ҳ���Ա����벢���������Գ��������С��������ֻ�Ƕ���������е�һ��,��һ�����������.
�����Ҫ���������Գ���������test_Atomic.pyģ��,��ô���Ա�дһ��������Ƶij���.����ϰ����ʹ��unittestģ��ִ��doctests,���磺
import test_Atomic
suite = unittest.TestLoader().loadTestsFromTestCase(test_Atomic.TestAtomic)
pnnt(runner.run(suite))
����,�����Ѿ�������һ����������,����ͨ����unittestģ���ȡtest_Atomic ģ��ʵ�ֵ�,����ʹ����ÿһ��test*()����(��ʵ������test_list_success()��test_list_fail(),�Ժ�ܿ�ͻῴ��)��Ϊ��������.
�������ڽ��鿴TestAtomic���ʵ��.��ͨ��������(������unittest.TestCase ����),����ô��������,û�б�Ҫʵ�ֳ�ʼ������.����һ������,���ǽ���Ҫ���� һ������,������Ҫ��������,�������ǽ�ʵ��������������.
def setUp(self)��
self.original_list = list(range(10))
�����Ѿ�ʹ���� unittest.TestCase.setUp()���������������IJ�������Ƭ��.
def test_list_succeed(self):
items = self.original_list[:]
with Atomic.Atomic(items) as atomic:
self.assertEqual(items,
def test_list_fail(self):
with self.assertRaises(AttributeError):
atomic.poop() # Typo
self.assertListEqual(items, self.original_list)
����������Profiling��
����������к���,���������˱�Ԥ����Ҫ��ö���ڴ�,��ô����ͨ����ѡ����㷨�����ݽṹ������,�������Ե�Ч�ķ�ʽ����ʵ��.���������ԭ����ʲô, ��õķ�������ȷ���ҵ����ⷢ���ĵط�,����ֻ�Ǽ�˴��벢��ͼ��������Ż�. ����Ż��ᵼ������bug,���߶Գ����б����Գ����������ܲ�û��ʵ��Ӱ��IJ��ֽ�������,���Ⲣ�ǽ������ķѴ�ʱ��ĵط�.
����������profiling֮ǰ,ע��һЩ����ѧϰ��ʹ�õ�Python�������ϰ�����������,���Ҷ���߳������ܲ�������.��Щ�����������ض���ij��Python�汾��, ���Ǻ�����Python������Ʒ��.��һ,����Ҫֻ������ʱ,���ʹ��Ԫ������б��� �ڶ�,ʹ��������,�����Ǵ������Ԫ����б��������Ͻ��е�������������,����ʹ��Python���õ����ݽṹ dicts��lists��tuples ����ʵ���Լ����Զ���ṹ,��Ϊ���õ����ݽṹ���Ǿ����˸߶��Ż��ģ�����,��С�ַ����в������ַ���ʱ, ��Ҫ��С�ַ�����������,�������б����ۻ�,����ַ����б���ϳ�Ϊһ���������ַ���������,Ҳ�����һ��,���ij������(����������)��Ҫ���ʹ�����Խ��з���(�������ģ���е�ij������),���ij�����ݽṹ�н��з���,��ô�Ϻõ������Ǵ�����ʹ��һ���ֲ����������ʸö���,�Ա��ṩ����ķ����ٶ�.
Python�����ṩ�������ر����õ�ģ��,���Ը������˴������������.һ����timeitģ�顪����ģ������ڶ�һС��Python������м�ʱ,����������������������ض������������ܽ��бȽϵȳ���.��һ����cProfileģ��,������profile ��������ܡ�����ģ��Ե��ü����������������ϸ�ֽ�,�Ա㷢������ƿ������.
if __name__ == "__main__":
repeats = 1000
for function in ("function_a", "function_b", "function_c"):
t = timeit.Timer("{0}(X, Y)".format(function),"from __main__ import {0}, X, Y".format(function))
sec = t.timeit(repeats) / repeats
����timeit.Timer()�����ӵĵ�һ��������������Ҫִ�в���ʱ�Ĵ���,����ʽ���ַ���.����,���ַ�����"function_a(X,Y)"���ڶ��������ǿ�ѡ��,����һ����ִ�е��ַ���,��һ�����ڴ���ʱ�Ĵ���֮ǰ,�Ա��ṩһЩ��������.����,���Ǵ� __main__ (��this)ģ�鵼���˴����Եĺ���,����������Ϊ�������ݴ���ı���(X ��Y),�����������ڸ�ģ��������Ϊȫ�ֱ����ṩ��.����Ҳ���Ժ������������ģ���е�������һ�������е������.
����timeit.Timer�����timeit()����ʱ,���Ƚ�ִ�й����ӵĵڶ�������(�����), ֮��ִ�й����ӵĵ�һ������������ִ��ʱ����м�ʱ.timeit.Timer.timeit()�����ķ���ֵ�����������ʱ��,������float.Ĭ�������,timeit()�����ظ�100���,�������� ����Щִ�е�������,������һ�ض�������,ֻ��Ҫ1000�η����Ϳ��Ը������õĽ��, �����ض��ظ�����������������ʽָ��.�ڶ�ÿ���������м�ʱ��,ʹ���ظ��������������г�������,�͵õ���ƽ��ִ��ʱ��,���ڿ���̨�д�ӡ����������ִ��ʱ��.
����һʵ����,function_a()��Ȼ�����ġ������ٶ�������ʹ�õ��������ݶ���. ����Щ�����һһ�����������ݲ�ͬ������ܲ�����Ӱ�졪��������Ҫʹ�ö����������ݶ�ÿ���������в���,�Ա㸲���д����ԵIJ�������,������ִ��ʱ���ƽ��ִ��ʱ����бȽ�.
֮�����ǿ������ض����������������м�ʱ,�Ա�����������ıȽ�.
cProfile.run("for i in ranged 1000): {0}(X, Y)".format(function))
���DZ��뽫�ظ��Ĵ���������Ҫ���ݸ�cProfile.run()�����Ĵ����ڲ�,������Ҫ���κδ���,��Ϊģ�麯����ʹ����ʡ��Ѱ����Ҫʹ�õĺ��������.����û��ʹ����ʽ��print()���,��ΪĬ�������,cProfile.run()�������ڿ���̨�д�ӡ�����.��������������к�������ؽ��(��Щ���б�ʡ��,��ʽҲ��������������,�Ա���ҳ����Ӧ)��
ncalls tottime percall cumtime percall filename:lineno(function)
��.000 0.001 0.000 0.001 0.000 {built-in method len}
ncalls ("���õĴ���")���г��˶�ָ������(��filename:lineno(function)���г�) �ĵ��ô���.����һ�������ظ��� 1000�ε���,�����ر��뽫���������ס.tottime ("�ܵ�ʱ��")���г���ij�������кķѵ���ʱ��,�����ų��˺������õ����������ڲ����ѵ�ʱ��.��һ��percall���г��˶Ժ�����ÿ�ε��õ�ƽ��ʱ��(tottime // ncalls). cumtime ("�ۻ�ʱ��")�г����ں����кķѵ�ʱ��,���Ұ����˺������õ����������ڲ����ѵ�ʱ��.�ڶ���percall���г��˶Ժ�����ÿ�ε��õ�ƽ��ʱ��,��������õĺ����ķѵ�ʱ��.
��cProfile����ѧ��,ԭʼ����ָ�ľ��Ƿǵݹ�ĺ�������.
�����������һ���dz��̵Ŀ���̨�Ựʵ��,Ϊʹ���ʺ�ҳ��չʾ,�������ʵ�����,�����Լ����������Դ���չʾ��
Welcome to the profile statistics browser.
% read profile.dat
profile.dat% callers function_b
Random listing order was used
Function was called by...
ncalls tottime cumtime
profile.dat% callees function_b
Function called...
��.000 0.001 0.001 built-in method len
profile.dat% quit
����help���Ի�ȡ�����б�,help����������������Ի�ȡ������ĸ�����Ϣ.����, help stats���г����Ը���stats����IJ���.��������һЩ���õĹ���,�����ṩprofile���ݵ�ͼ�λ�չʾ��ʽ,���� RunSnakeRun (), �ù�����Ҫ������wxPython GUI��.
ʹ��timeit��cProfileģ��,���ǿ���ʶ��������Լ���������Щ�����ķѳ���Ԥ�ڵ�ʱ�䣻ʹ��cProfileģ��,������ȷ���ʱ������������.
װ��Pycharm
��. ���Ӷϵ�
Python�Դ���pdb��,������pdb�����Գ����Ǻܷ����,��Ȼ��,ʲôԶ�̵���,���߳�֮��,pdb�Ǹ㲻����.
��pdb�����ж��ַ�ʽ��ѡ��
�� ����������Ŀ�����,����-m����,��������myscript.py�Ļ��ϵ���dz����ִ�е�һ��֮ǰ
python -m pdb myscript.py
import pdb
import mymodule
pdb.run('mymodule.test()')
a = 1
pdb.set_trace()
c = a + b
print (c)
Ȼ���������нű�,����pdb.set_trace()�Ǿͻᶨ����,�Ϳ��Կ������Ե���ʾ��(Pdb)��
���õĵ�������
h(elp),���ӡ��ǰ�汾Pdb���õ�����,���Ҫ��ѯij������,�������� h [command],���磺"h l" �� �鿴list����
l(ist),�����г���ǰ��Ҫ���еĴ����
(Pdb) l
(Pdb) b
Num Type Disp Enb Where
(Pdb) cl
Clear all breaks? y
disable/enable,����/����ϵ�
n(ext),�ó���������һ��,�����ǰ�����һ����������,��n�Dz�����뱻���õĺ������е�
s(tep),��n����,���������ǰ��һ����������,��ôs����뱻���õĺ�������
c(ont(inue)),�ó�����������,ֱ�������ϵ�
j(ump),�ó�����ת��ָ��������
- pdb.set_trace()
a(rgs),��ӡ��ǰ�����IJ���

(Pdb) a
_logger =
_toStepNum = 10
_cmpMap = {'_bcmpbinarylog': 'True', '_bcmpLog': 'True', '_bcmpresp': 'True'}
p,�����õ�����֮һ,��ӡij������
(Pdb) p _new
��,��̾�ź���������,����ֱ�Ӹı�ij������
q(uit),�˳�����
�������������µ��Գ���Ҳ��һ��ͦ����˼������,��¼��������һ��
w ,Print a stack trace, with the most recent frame at the bottom.An arrow indicates the "current frame", which determines the context of most commands. 'bt' is an alias for this command.
d ,Move the current frame one level down in the stack trace
(to a newer frame).
u ,Move the current frame one level up in the stack trace
(to an older frame).
ʹ�� u �� d ����,���ǿ�����ջ֮֡���л�,���Ի�ȡ����������ı�����Ϣ.w������ʾ�����һЩջ֡��Ϣ.
���Ͼ������¸�С��Ϊ���������python���Ժ����ļ���python���Ժ����ļ��������ѯ��ѯ�������,���������С����µ�����ֻҪ�ܶԷ�˿������,�����������Ĺ����Ͷ���,��Ҫ���ǽ���վ�����������ߵ�����Ŷ����