

os是python自带的系统模块,需要import使用
os 源于英文Operating System(操作系统)的缩写
cwd 则是源于Current Working Directory,中文意思是 当前工作目录
所以os.getcwd() 指获取当前工作目录
示例:
getcwd()方法语法格式如下:
都说到这里了大家应该明白,举例来讲,os.getcwd()、sys.path[0] (sys.argv[0])和 file 的区别是这样的:
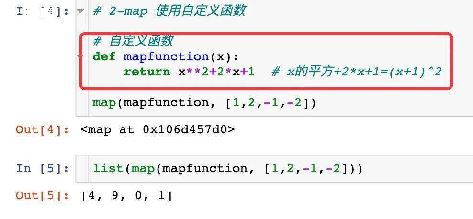
假设目录结构是:
然后我们在C:\test下面执行
这时sub_path.py里面与各种用法对应的值其实是:
无
path的准确定位对于import包,读写文件都非常重要,

如果一时不能理解,可以在文件执行开头多加几个
print帮助我们确定那个路径是我们希望拿到的,然后将其设为全局变量就好了
对基础运行环境有疑问的,推荐参考: python函数深入浅出 0.基础篇
time 是python带的非内置库,使用时需要import,主要用于处理和时间相关的操作.
time.sleep用于给定时间内挂起(等待)当前线程的执行.
time.sleep() 函数的例子:
可以看到虽然都是打印出一样的结果,但time.sleep()加入了等待时间
这里还要解释一下python中线程与进程的区别.
举个例子,厨房做菜看成是一个进程,那么这个进程下面就可能有多个人或一个人(cpu基本执行单元,即线程)来执行,多个人可以分别洗菜,刷碗,摆盘等等同时作业,他们又是共享这个厨房的资源的.每个人存在一定的资源竞争关系,比如炉火只有1个.
这里time.sleep是针对线程执行的,也就是其中一个人去sleep睡觉了,不影响其他人的继续工作.
参数
该函数没有返回值.
结果类似如下:
time.sleep()常用于推迟执行的场景
在python中,与时间相关的模块有:time,datetime以及calendar
这是os模块下操作目录和文件相关的函数
listdir() 只返回文件夹下所有文件名的列表(list)
:
math 模块则会把参数转换为 float.
listdir()方法语法格式如下:
path -- 需要列出的目录路径,默认为当前路径
其他相关的操作文件(文件夹)函数如下:
当我们需要遍历某个文件夹下文件/目录通常有两种操作
当获取文件后如何获取其后缀名,判断是否指定格式的文档、图片比如txt,doc,bmp,png,gif,jpg等:
熟练操作文件和目录,可以帮组我们写批量脚本时更高效,也是重要的python基础之一.
字典是一种通过名字或者关键字引用的得数据结构,其键可以是数字、字符串、元组,这种结构类型也称之为映射.字典类型是Python中唯一内建的映射类型,基本的操作包括如下:
(1)len():返回字典中键―值对的数量;
(10)has_key函数:检查字典中是否含有给出的键
(11)items和iteritems函数:items将所有的字典项以列表方式返回,列表中项来自(键,值),iteritems与items作用相似,但是返回的是一个迭代器对象而不是列表
第一段:字典的创建
①1 直接创建字典
printd
printd['two']
printd['three']
运算结果:
=======RESTART: C:\Users\Mr_Deng\Desktop\test.py=======
printu'items中的内容:'
printitems
printu'利用dict创建字典,输出字典内容:'
d=dict(items)
printu'查询字典中的内容:'
printd['one']
items中的内容:
利用dict创建字典,输出字典内容:
查询字典中的内容:
或者通过关键字创建字典
printu'输出字典内容:'
输出字典内容:
第二段:字典的格式化字符串
print"three is %(three)s."%d
第三段:字典方法
d.clear()
{}
请看下面两个例子
d={}
dd=d
d['one']=1
printdd
printu'初始X字典:'
printx
printu'X复制到Y:'
y=x.copy()
printu'Y字典:'
printy
printu'修改Y中的值,观察输出:'
printu'删除Y中的值,观察输出'
y['test'].remove('c')
初始X字典:
X复制到Y:
Y字典:
修改Y中的值,观察输出:
删除Y中的值,观察输出
注:在复制的副本中对值进行替换后,对原来的字典不产生影响,但是如果修改了副本,原始的字典也会被修改.deepcopy函数使用深复制,复制其包含所有的值,这个方法可以解决由于副本修改而使原始字典也变化的问题.
fromcopyimportdeepcopy
x={}
x['test']=['a','b','c','d']
z=deepcopy(x)
printu'输出:'
printz
printu'修改后输出:'
x['test'].append('e')
运算输出:
输出:
{'test': ['a','b','c','d']}
修改后输出:
{'test': ['a','b','c','d','e']}
d=dict.fromkeys(['one','two','three'])
{'three':None,'two':None,'one':None}
或者指定默认的对应值
d=dict.fromkeys(['one','two','three'],'unknow')
{'three':'unknow','two':'unknow','one':'unknow'}
printd.get('one')
printd.get('four')
None
注:get函数可以访问字典中不存在的键,当该键不存在是返回None
printd.has_key('one')
printd.has_key('four')
True
False
list=d.items()
forkey,valueinlist:
printkey,':',value
one :1
it=d.iteritems()
fork,vinit:
print"d[%s]="%k,v
d[one]=1
printu'keys方法:'
list=d.keys()
printlist
printu'\niterkeys方法:'
it=d.iterkeys()
forxinit:
keys方法:
['three','two','one']
iterkeys方法:
three
two
one
d.pop('one')
d.popitem()
printd.setdefault('one',1)
d={
}
x={'one':1}
d.update(x)
printd.values()
以上就是土嘎嘎小编为大家整理的python函数操作逻辑相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!