

排课问题的本质是将课程、教师和学生在合适的时间段内分配到合适的教室中,涉及到的因素较多,是一个多目标的调度问题,在运筹学中被称为时间表问题(Timetable Problem,TTP).设一个星期有n个时段可排课,有m位教师需要参与排课,平均每位教师一个星期上k节课,在不考虑其他限制的情况下,能够推出的可能组合就有 种,如此高的复杂度是目前计算机所无法承受的.所以呢众多研究者提出了多种其他排课算法,如模拟退火,列表寻优搜索和约束满意等.
Github :
遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法.遗传算法的流程如下所示:
遗传算法首先针对待解决问题随机生成一组解,我们称之为种群(Population).种群中的每个个体都是问题的解,在优化的过程中,算法会计算整个种群的成本函数,从而得到一个与种群相关的适应度的序列.如下图所示:
为了得到新的下一代种群,首先根据适应度对种群进行排序,从中挑选出最优的几个个体加入下一代种群,这一个过程也被称为精英选拔.新种群余下的部分通过对选拔出来的精英个体进行修改得到.

对种群进行修改的方法参考了生物DAN进化的方法,一般使用两种方法: 变异 和 交叉 . 变异 的做法是对种群做一个微小的、随机的改变.如果解的编码方式是二进制,那么就随机选取一个位置进行0和1的互相突变;如果解的编码方式是十进制,那么就随机选取一个位置进行随机加减. 交叉 的做法是随机从最优种群中选取两个个体,以某个位置为交叉点合成一个新的个体.
经过突变和交叉后我们得到新的种群(大小与上一代种群一致),对新种群重复重复上述过程,直到达到迭代次数(失败)或者解的适应性达到我们的要求(成功),GA算法就结束了.
算法实现
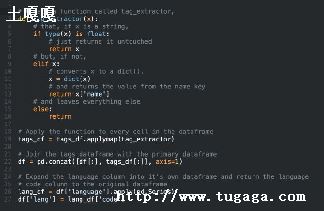
首先定义一个课程类,这个类包含了课程、班级、教师、教室、星期、时间几个属性,其中前三个是我们自定义的,后面三个是需要算法来优化的.
此时此刻呢定义cost函数,这个函数用来计算课表种群的冲突.当被测试课表冲突为0的时候,这个课表就是个符合规定的课表.冲突检测遵循下面几条规则:
使用遗传算法进行优化的过程如下,与上一节的流程图过程相同.
init_population :随机初始化不同的种群.
mutate :变异操作,随机对 Schedule 对象中的某个可改变属性在允许范围内进行随机加减.
crossover :交叉操作,随机对两个对象交换不同位置的属性.
evolution :启动GA算法进行优化.
实验结果
最优化
为什么要做最优化呢?因为在生活中,人们总是希望幸福值或其它达到一个极值,比如做生意时希望成本最小,收入最大,所以在很多商业情境中,都会遇到求极值的情况.
函数求根
这里「函数的根」也称「方程的根」,或「函数的零点」.
先把我们需要的包加载进来.import numpy as npimport scipy as spimport scipy.optimize as optimport matplotlib.pyplot as plt%matplotlib inline
函数求根和最优化的关系?什么时候函数是最小值或最大值?
两个问题一起回答:最优化就是求函数的最小值或最大值,同时也是极值,在求一个函数最小值或最大值时,它所在的位置肯定是导数为 0 的位置,所以要求一个函数的极值,必然要先求导,使其为 0,所以函数求根就是为了得到最大值最小值.
scipy.optimize 有什么方法可以求根?
函数求最小化
求最小值就是一个最优化问题.求最大值时只需对函数做一个转换,比如加一个负号,或者取倒数,就可转成求最小值问题.所以两者是同一问题.
初始值对最优化的影响是什么?
由上图可见,当初始值为 10 时,函数找到的是局部最小值点,可见 minimize 的默认算法对起始点的依赖性.
那么怎么才能不管初始值在哪个位置,都能找到全局最小值点呢?

如何找到全局最优点?
可以使用 basinhopping 函数找到全局最优点,相关背后算法,可以看帮助文件,有提供论文的索引和出处.
当起始点在比较远的位置,依然成功找到了全局最小值点.
如何求多元函数最小值?
曲线拟合
曲线拟合和最优化有什么关系?
曲线拟合的问题是,给定一组数据,它可能是沿着一条线散布的,这时要找到一条最优的曲线来拟合这些数据,也就是要找到最好的线来代表这些点,这里的最优是指这些点和线之间的距离是最小的,这就是为什么要用最优化问题来解决曲线拟合问题.
举例说明,给一些点,找到一条线,来拟合这些点.
上面的点整体上呈现一个线性关系,要找到一条斜线来代表这些点,这就是经典的一元线性回归.目标就是找到最好的线,使点和线的距离最短.要优化的函数是点和线之间的距离,使其最小.点是确定的,而线是可变的,线是由参数值,斜率和截距决定的,这里就是要通过优化距离找到最优的斜率和截距.
上式就是误差平方和.
误差平方和是什么?有什么作用?
误差平方和公式为:
误差平方和大,表示真实的点和预测的线之间距离太远,说明拟合得不好,最好的线,应该是使误差平方和最小,即最优的拟合线,这里是条直线.
误差平方和就是要最小化的目标函数.
最小二乘(Least Square)是什么?
上面用的是 minimize 方法,这个问题的目标函数是误差平方和,这就又有一个特定的解法,即最小二乘.
最小二乘的思想就是要使得观测点和估计点的距离的平方和达到最小,这里的"二乘"指的是用平方来度量观测点与估计点的远近(在古汉语中"平方"称为"二乘"),"最小"指的是参数的估计值要保证各个观测点与估计点的距离的平方和达到最小.
非线性最小二乘
有约束的最小化
有约束的最小化是指,要求函数最小化之外,还要满足约束条件,举例说明.
不等式约束
介绍下相关理论,先来看下存在等式约束的极值问题求法,比如下面的优化问题.
目标函数是 f(w),下面是等式约束,通常解法是引入拉格朗日算子,这里使用 bb 来表示算子,得到拉格朗日公式为
l 是等式约束的个数.
然后分别对 w 和bb 求偏导,使得偏导数等于 0,然后解出 w 和bibi,至于为什么引入拉格朗日算子可以求出极值,原因是 f(w) 的 dw 变化方向受其他不等式的约束,dw的变化方向与f(w)的梯度垂直时才能获得极值,而且在极值处,f(w) 的梯度与其他等式梯度的线性组合平行,所以呢他们之间存在线性关系.(参考<<最优化与KKT条件>>)
对于不等式约束的极值问题
scipy.optimize.minimize 中包括了多种最优化算法,每种算法使用范围不同,详细参考官方文档.
Python 是一种解释型语言.这就是说,与C 语言和C 的衍生语言不同,Python 代码在运行之前不需要编译.其他解释型语言还包括PHP 和Ruby.
- Python 是动态类型语言,指的是你在声明变量时,不需要说明变量的类型.你可以直接编写类似x=111 和x="I'm a string"这样的代码,程序不会报错.
- Python 非常适合面向对象的编程(OOP),因为它支持通过组合(composition)与继承(inheritance)的方式定义类(class).
- Python 中没有访问说明符(access specifier,类似C++中的public 和private),这么设计的依据是"大家都是成年人了".
- 在Python 语言中,函数是第一类对象(first-class objects).这指的是它们可以被指定给变量,函数既能返回函数类型,也可以接受函数作为输入.类(class)也是第一类对象.
- Python 代码编写快,但是运行速度比编译语言通常要慢.好在Python 允许加入基于C语言编写的扩展,所以呢我们能够优化代码,消除瓶颈,这点通常是可以实现的.numpy 就是一个很好地例子,它的运行速度真的非常快,因为很多算术运算其实并不是通过Python 实现的.
- Python 用途非常广泛――网络应用,自动化,科学建模,大数据应用,等等.它也常被用作"胶水语言",帮助其他语言和组件改善运行状况.
- Python 让困难的事情变得容易,所以呢程序员可以专注于算法和数据结构的设计,而不用处理底层的细节.
黑马程序员含有全套的介绍,并且有和其他语言的对比.他们很多公开课也说过.我就是看黑马的课学的Python,祝好
怎么学python
俗话说得好,"摩天大楼从地起",学习任何编程语言都一定要把该语言的基础打牢,而怎么打地基呢?秘诀只有一条:多敲代码多敲代码多敲代码.学习前期建议找一本讲python基础的书或博客,把里面的例题跟着操作一遍,在基础打扎实后,可上一些比较出名的竞赛项目的网站如kaggle等,通过做项目去巩固知识.
推荐理由:全面介绍了Python的基础知识、基本概念,高级主题,还有Python程序测试、打包、发布等知识,及10个具有实际意义的Python项目的开发过程,涉及的范围较广,既能为初学者夯实基础,又能帮助程序员提升技能,适合各个层次的Python开发人员阅读参考.
基础知识
代码规范
① 缩进
#一个完整的语句首句要顶格
i=0
#同一代码块的语句应缩进一致
print(i)
i+=1
编程语言的注释,即对代码的解释和说明.给代码加上注释,可提高代码的可读性,当你阅读一段他人写的代码时,通过注释迅速掌握代码的大致意思,读起代码将更加得心应手.
python语言的注释分为单行注释和多行注释,在注释符后的内容计算机会自动跳过不去执行.
单行注释:在需注释语句前加"#",可在代码后使用,也可另起一行使用
i=1 #在代码后使用注释
#另起一行使用注释
多行注释:在语句开头和结尾处加三个单引号或三个双引号(前后须一致)
'''
使用单引号的多行注释
"""
使用双引号的多行注释
使用注释除了起到望文生义,迅速了解代码意思的作用外,还有一个小妙处,可以将某段未完成或需要修改的代码隐蔽起来,暂时不让计算机执行.
python中默认以行结束作为代码结束的标记,而有时候为了阅读方便,我们需要将一个完整代码跨行表示,这时候我们可以使用续行符:反斜杠"\"来将一行语句分为多行显示:
score = eng_score + \
math_score + \
his_score
注意:若语句中使用大括号{}、中括号[]或小括号()将数据括起来,则不需要使用续行符,如下所示:
name=['Ada','Ailsa','Amy',
'Barbara','Betty','Blanche'
'Carina','Carrie','Carry'
'Daisy','Darcy','Diana']
什么是算法
算法是指解决某项问题的流程或步骤,我们可以用一个很贴近生活的例子去理解,假如你需要做一道"西红柿炒鸡蛋",根据菜谱:先准备食材,然后下油热锅,将西红柿倒进去翻炒后,加入蛋液翻炒至熟.
这就是我们完成"西红柿炒鸡蛋"这道菜所用的"算法",而完成这个算法所需要的就是原料和操作说明,下面来看看原料和说明是什么.
变量
Python语言中的"原料"即对象,在python里万物皆对象,而对象通过引用变量唯一存在,引用上面的例子,可以将"鸡蛋"理解为"对象",而给它取的名字"小红家鸡生的蛋"则是"变量".
变量的概念想必大家不会陌生,和中学方程中学的变量基本上是一致的.变量可以理解为对事物的一个代号或者贴的一个标签,是一个可重复使用的量;而不同于方程中的变量,编程语言中的变量不仅仅是数值型, 还可以是字符型、逻辑型等其他数据类型.
① 变量的性质
先定义后使用在python中引用变量需要先定义,否则会报错,但与其他编程语言如C语言不同,python定义变量不需要事先定义变量类型,变量类型随变量所赋值的类型决定可重复赋值及运算在python中变量可以重复赋值使用,变量间也可相互赋值,同时可以对变量进行运算操作#变量可重复赋值
#可对变量做运算
i+1
#查看变量的数据类型
type(a)
只能包含:数字、字母、下划线不能以数字开头,不能包含python保留字、关键字、函数名慎用小写字母l和大写字母O, 避免与数字1和0混淆建议用驼峰命名法,即以单词加""命名,如:studentname#查看python有哪些保留字
import keyword
print(keyword.kwlist)
多重赋值对同一对象可以引用多个变量,例如一个人可以有多重身份,Mr Li 是一位父亲,同时也是一位教师,不同的变量,实质指向的对象是同一事物.father = teacher = 'Mr Li'
语句
了解完算法中的"原料",我们再来看看算法中的"操作说明"是什么呢?算法中的"操作说明"可以说是算法的"灵魂",就好像一道菜完成的作品如何,很大程度取决于厨师的厨艺(即做菜秘籍).构成算法"操作步骤"的是语句,其中包含python的基本语句和控制流程语句.控制流程语句的语法相对较复杂,在后面的文章再继续介绍,我们先认识一下python的基本语句:
① 输出语句
python中输出值的方式主要有两种:表达式和print( )函数,两者的区别在于,表达式输出的结果为一个python对象,而在实际运用中,为方便阅读,通常需要按照一定格式输出结果,print( )函数就很好地解决此问题.
print( )语法:
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
print( )参数:
objects -- 复数,表示可以一次输出多个对象.输出多个对象时,需要用 , 分隔.sep -- 用来间隔多个对象,默认值是一个空格.end -- 用来设定以什么结尾.默认值是换行符 "\n",可换成其他字符串.file -- 要写入的文件对象.flush -- 输出是否被缓存通常决定于 file,但如果 flush 关键字参数为 True,流会被强制刷新.#打印多个值,设置中间分隔符为"-"
print("广州","上海","深圳",sep="-")
#先以默认结尾符"\n"输出,再以结尾符设置为"-",注意区别二者区别
print("广州")
print("上海")
print("深圳")
print("广州",end="-")
print("上海",end="-")
print("深圳",end="-")
以上代码实行结果为:
在python中获取键盘输入数据的函数是input()函数,input函数会自动将输入的数据转为字符串类型,并自动忽略换行符,同时可给出提示字符串.如果需要得到其他类型的数据,可对其进行强制性类型转换.
input( )语法:
input([prompt])
input( )参数:
prompt: 给输入者的提示信息,可选参数age=input("请输入您的年龄:")
想象一下,您有一个线性方程组和不等式系统.这样的系统通常有许多可能的解决方案.线性规划是一组数学和计算工具,可让您找到该系统的特定解,该解对应于某些其他线性函数的最大值或最小值.
混合整数线性规划是 线性规划 的扩展.它处理至少一个变量采用离散整数而不是连续值的问题.尽管乍一看混合整数问题与连续变量问题相似,但它们在灵活性和精度方面具有显着优势.
整数变量对于正确表示自然用整数表示的数量很重要,例如生产的飞机数量或服务的客户数量.
一种特别重要的整数变量是 二进制变量 .它只能取 零 或 一 的值,在做出是或否的决定时很有用,例如是否应该建造工厂或者是否应该打开或关闭机器.您还可以使用它们来模拟逻辑约束.
线性规划是一种基本的优化技术,已在科学和数学密集型领域使用了数十年.它精确、相对快速,适用于一系列实际应用.
混合整数线性规划允许您克服线性规划的许多限制.您可以使用分段线性函数近似非线性函数、使用半连续变量、模型逻辑约束等.它是一种计算密集型工具,但计算机硬件和软件的进步使其每天都更加适用.
通常,当人们试图制定和解决优化问题时,第一个问题是他们是否可以应用线性规划或混合整数线性规划.
以下文章说明了线性规划和混合整数线性规划的一些用例:
随着计算机能力的增强、算法的改进以及更多用户友好的软件解决方案的出现,线性规划,尤其是混合整数线性规划的重要性随着时间的推移而增加.
解决线性规划问题的基本方法称为,它有多种变体.另一种流行的方法是.
混合整数线性规划问题可以通过更复杂且计算量更大的方法来解决,例如,它在幕后使用线性规划.这种方法的一些变体是,它涉及使用 切割平面 ,以及.
有几种适用于线性规划和混合整数线性规划的合适且众所周知的 Python 工具.其中一些是开源的,而另一些是专有的.您是否需要免费或付费工具取决于问题的规模和复杂性,以及对速度和灵活性的需求.
值得一提的是,几乎所有广泛使用的线性规划和混合整数线性规划库都是以 Fortran 或 C 或 C++ 原生和编写的.这是因为线性规划需要对(通常很大)矩阵进行计算密集型工作.此类库称为求解器.Python 工具只是求解器的包装器.
Python 适合围绕本机库构建包装器,因为它可以很好地与 C/C++ 配合使用.对于本教程,您不需要任何 C/C++(或 Fortran),但如果您想了解有关此酷功能的更多信息,请查看以下资源:
基本上,当您定义和求解模型时,您使用 Python 函数或方法调用低级库,该库执行实际优化工作并将解决方案返回给您的 Python 对象.
几个免费的 Python 库专门用于与线性或混合整数线性规划求解器交互:
在本教程中,您将使用SciPy和PuLP来定义和解决线性规划问题.
在本节中,您将看到线性规划问题的两个示例:
您将在下一节中使用 Python 来解决这两个问题.
考虑以下线性规划问题:
你需要找到X和?使得红色,蓝色和黄色的不平等,以及不平等X 0和? 0,是满意的.同时,您的解决方案必须对应于z的最大可能值.
您需要找到的自变量(在本例中为 x 和 y )称为 决策变量 .要最大化或最小化的决策变量的函数(在本例中为 z) 称为 目标函数 、 成本函数 或仅称为 目标 .您需要满足的 不等式 称为 不等式约束 .您还可以在称为 等式约束 的约束中使用方程.
这是您如何可视化问题的方法:
如果您忽略红色、蓝色和黄色区域,则仅保留灰色区域.灰色区域的每个点都满足所有约束,是问题的潜在解决方案.该区域称为 可行域 ,其点为 可行解 .在这种情况下,有无数可行的解决方案.
您想最大化z.对应于最大z的可行解是 最优解 .如果您尝试最小化目标函数,那么最佳解决方案将对应于其可行的最小值.
请注意,z是线性的.你可以把它想象成一个三维空间中的平面.这就是为什么最优解必须在可行区域的 顶点 或角上的原因.在这种情况下,最佳解决方案是红线和蓝线相交的点,稍后您将看到.
有时,可行区域的整个边缘,甚至整个区域,都可以对应相同的z值.在这种情况下,您有许多最佳解决方案.
您现在已准备好使用绿色显示的附加等式约束来扩展问题:
现在的解决方案必须满足绿色等式,所以呢可行区域不再是整个灰色区域.它是绿线从与蓝线的交点到与红线的交点穿过灰色区域的部分.后一点是解决方案.
如果插入x的所有值都必须是整数的要求,那么就会得到一个混合整数线性规划问题,可行解的集合又会发生变化:
您不再有绿线,只有沿线的x值为整数的点.可行解是灰色背景上的绿点,此时最优解离红线最近.
这三个例子说明了 可行的线性规划问题 ,因为它们具有有界可行区域和有限解.
如果没有解,线性规划问题是 不可行的 .当没有解决方案可以同时满足所有约束时,通常会发生这种情况.
例如,考虑如果添加约束x + y 1会发生什么.那么至少有一个决策变量(x或y)必须是负数.这与给定的约束x 0 和y 0相冲突.这样的系统没有可行的解决方案,所以呢称为不可行的.
另一个示例是添加与绿线平行的第二个等式约束.这两行没有共同点,所以呢不会有满足这两个约束的解决方案.
一个线性规划问题是 无界的 ,如果它的可行区域是无界,将溶液不是有限.这意味着您的变量中至少有一个不受约束,可以达到正无穷大或负无穷大,从而使目标也无限大.
例如,假设您采用上面的初始问题并删除红色和黄色约束.从问题中删除约束称为 放松 问题.在这种情况下,x和y不会在正侧有界.您可以将它们增加到正无穷大,从而产生无限大的z值.
在前面的部分中,您研究了一个与任何实际应用程序无关的抽象线性规划问题.在本小节中,您将找到与制造业资源分配相关的更具体和实用的优化问题.
数学模型可以这样定义:
最后,产品数量不能为负,所以呢所有决策变量必须大于或等于零.
与前面的示例不同,您无法方便地将其可视化,因为它有四个决策变量.但是,无论问题的维度如何,原理都是相同的.
在本教程中,您将使用两个Python 包来解决上述线性规划问题:
SciPy 设置起来很简单.安装后,您将拥有开始所需的一切.它的子包 scipy.optimize 可用于线性和非线性优化.
PuLP 允许您选择求解器并以更自然的方式表述问题.PuLP 使用的默认求解器是COIN-OR Branch and Cut Solver (CBC).它连接到用于线性松弛的COIN-OR 线性规划求解器 (CLP)和用于切割生成的COIN-OR 切割生成器库 (CGL).
另一个伟大的开源求解器是GNU 线性规划工具包 (GLPK).一些著名且非常强大的商业和专有解决方案是Gurobi、CPLEX和XPRESS.
除了在定义问题时提供灵活性和运行各种求解器的能力外,PuLP 使用起来不如 Pyomo 或 CVXOPT 等替代方案复杂,后者需要更多的时间和精力来掌握.
您可以使用pip以下方法安装两者:
您可能需要运行pulptest或sudo pulptest启用 PuLP 的默认求解器,尤其是在您使用 Linux 或 Mac 时:
在 MacOS 上,您可以使用 Homebrew:
在 Debian 和 Ubuntu 上,使用apt来安装glpk和glpk-utils:
在Fedora,使用dnf具有glpk-utils:
您可能还会发现conda对安装 GLPK 很有用:
安装完成后,可以查看GLPK的版本:
有关详细信息,请参阅 GLPK 关于使用Windows 可执行文件和Linux 软件包进行安装的教程.
在本节中,您将学习如何使用 SciPy优化和求根库进行线性规划.
要使用 SciPy 定义和解决优化问题,您需要导入scipy.optimize.linprog():
现在您已经linprog()导入,您可以开始优化.
让我们首先解决上面的线性规划问题:
linprog()仅解决最小化(而非最大化)问题,并且不允许具有大于或等于符号 ( ) 的不等式约束.要解决这些问题,您需要在开始优化之前修改您的问题:
引入这些更改后,您将获得一个新系统:
该系统与原始系统等效,并且将具有相同的解决方案.应用这些更改的唯一原因是克服 SciPy 与问题表述相关的局限性.
下一步是定义输入值:
您将上述系统中的值放入适当的列表、元组或NumPy 数组中:
注意:请注意行和列的顺序!
约束左侧和右侧的行顺序必须相同.每一行代表一个约束.
来自目标函数和约束左侧的系数的顺序必须匹配.每列对应一个决策变量.
下一步是以与系数相同的顺序定义每个变量的界限.在这种情况下,它们都在零和正无穷大之间:
此语句是多余的,因为linprog()默认情况下采用这些边界(零到正无穷大).
注:相反的float("inf"),你可以使用math.inf,numpy.inf或scipy.inf.
最后,是时候优化和解决您感兴趣的问题了.你可以这样做linprog():
参数c是指来自目标函数的系数.A_ub和b_ub分别与不等式约束左边和右边的系数有关.同样,A_eq并b_eq参考等式约束.您可以使用bounds提供决策变量的下限和上限.
您可以使用该参数method来定义要使用的线性规划方法.有以下三种选择:
linprog() 返回具有以下属性的数据结构:
您可以分别访问这些值:
这就是您获得优化结果的方式.您还可以以图形方式显示它们:
如前所述,线性规划问题的最优解位于可行区域的顶点.在这种情况下,可行区域只是蓝线和红线之间的绿线部分.最优解是代表绿线和红线交点的绿色方块.
如果要排除相等(绿色)约束,只需删除参数A_eq并b_eq从linprog()调用中删除:
解决方案与前一种情况不同.你可以在图表上看到:
在这个例子中,最优解是红色和蓝色约束相交的可行(灰色)区域的紫色顶点.其他顶点,如黄色顶点,具有更高的目标函数值.
您可以使用 SciPy 来解决前面部分所述的资源分配问题:
和前面的例子一样,你需要从上面的问题中提取必要的向量和矩阵,将它们作为参数传递给.linprog(),然后得到结果:
opt.statusis0和opt.successis True,说明优化问题成功求解,最优可行解.
SciPy 的线性规划功能主要用于较小的问题.对于更大和更复杂的问题,您可能会发现其他库更适合,原因如下:
幸运的是,Python 生态系统为线性编程提供了几种替代解决方案,这些解决方案对于更大的问题非常有用.其中之一是 PuLP,您将在下一节中看到它的实际应用.
PuLP 具有比 SciPy 更方便的线性编程 API.您不必在数学上修改您的问题或使用向量和矩阵.一切都更干净,更不容易出错.
像往常一样,您首先导入您需要的内容:
现在您已经导入了 PuLP,您可以解决您的问题.
您现在将使用 PuLP 解决此系统:
第一步是初始化一个实例LpProblem来表示你的模型:
您可以使用该sense参数来选择是执行最小化(LpMinimize或1,这是默认值)还是最大化(LpMaximize或-1).这个选择会影响你的问题的结果.
一旦有了模型,就可以将决策变量定义为LpVariable类的实例:
您需要提供下限,lowBound=0因为默认值为负无穷大.该参数upBound定义了上限,但您可以在此处省略它,因为它默认为正无穷大.
可选参数cat定义决策变量的类别.如果您使用的是连续变量,则可以使用默认值"Continuous".
您可以使用变量x和y创建表示线性表达式和约束的其他 PuLP 对象:
当您将决策变量与标量相乘或构建多个决策变量的线性组合时,您会得到一个pulp.LpAffineExpression代表线性表达式的实例.
注意:您可以增加或减少变量或表达式,你可以乘他们常数,因为纸浆类实现一些Python的特殊方法,即模拟数字类型一样__add__(),__sub__()和__mul__().这些方法用于像定制运营商的行为+,-和*.
类似地,您可以将线性表达式、变量和标量与运算符 ==、=以获取表示模型线性约束的纸浆.LpConstraint实例.
注:也有可能与丰富的比较方法来构建的约束.__eq__(),.__le__()以及.__ge__()定义了运营商的行为==,=.
考虑到这一点,下一步是创建约束和目标函数并将它们分配给您的模型.您不需要创建列表或矩阵.只需编写 Python 表达式并使用+=运算符将它们附加到模型中:
在上面的代码中,您定义了包含约束及其名称的元组.LpProblem允许您通过将约束指定为元组来向模型添加约束.第一个元素是一个LpConstraint实例.第二个元素是该约束的可读名称.
设置目标函数非常相似:
或者,您可以使用更短的符号:
现在您已经添加了目标函数并定义了模型.
注意:您可以使用运算符将 约束或目标附加到模型中,+=因为它的类LpProblem实现了特殊方法.__iadd__(),该方法用于指定 的行为+=.
对于较大的问题,lpSum()与列表或其他序列一起使用通常比重复+运算符更方便.例如,您可以使用以下语句将目标函数添加到模型中:
它产生与前一条语句相同的结果.
您现在可以看到此模型的完整定义:
模型的字符串表示包含所有相关数据:变量、约束、目标及其名称.
注意:字符串表示是通过定义特殊方法构建的.__repr__().有关 的更多详细信息.__repr__(),请查看Pythonic OOP 字符串转换:__repr__vs__str__ .
最后,您已准备好解决问题.你可以通过调用.solve()你的模型对象来做到这一点.如果要使用默认求解器 (CBC),则不需要传递任何参数:
.solve()调用底层求解器,修改model对象,并返回解决方案的整数状态,1如果找到了最优解.有关其余状态代码,请参阅LpStatus[].
你可以得到优化结果作为 的属性model.该函数value()和相应的方法.value()返回属性的实际值:
model.objective持有目标函数model.constraints的值,包含松弛变量的值,以及对象x和y具有决策变量的最优值.model.variables()返回一个包含决策变量的列表:
如您所见,此列表包含使用 的构造函数创建的确切对象LpVariable.
结果与您使用 SciPy 获得的结果大致相同.
注意:注意这个方法.solve()――它会改变对象的状态,x并且y!
您可以通过调用查看使用了哪个求解器.solver:
输出通知您求解器是 CBC.您没有指定求解器,所以呢 PuLP 调用了默认求解器.
如果要运行不同的求解器,则可以将其指定为 的参数.solve().例如,如果您想使用 GLPK 并且已经安装了它,那么您可以solver=GLPK(msg=False)在最后一行使用.请记住,您还需要导入它:
现在你已经导入了 GLPK,你可以在里面使用它.solve():
该msg参数用于显示来自求解器的信息.msg=False禁用显示此信息.如果要包含信息,则只需省略msg或设置msg=True.
您的模型已定义并求解,所以呢您可以按照与前一种情况相同的方式检查结果:
使用 GLPK 得到的结果与使用 SciPy 和 CBC 得到的结果几乎相同.
一起来看看这次用的是哪个求解器:
正如您在上面用突出显示的语句定义的那样model.solve(solver=GLPK(msg=False)),求解器是 GLPK.
您还可以使用 PuLP 来解决混合整数线性规划问题.要定义整数或二进制变量,只需传递cat="Integer"或cat="Binary"到LpVariable.其他一切都保持不变:
在本例中,您有一个整数变量并获得与之前不同的结果:
Nowx是一个整数,如模型中所指定.(从技术上讲,它保存一个小数点后为零的浮点值.)这一事实改变了整个解决方案.让我们在图表上展示这一点:
如您所见,最佳解决方案是灰色背景上最右边的绿点.这是两者的最大价值的可行的解决方案x和y,给它的最大目标函数值.
GLPK 也能够解决此类问题.
现在你可以使用 PuLP 来解决上面的资源分配问题:
定义和解决问题的方法与前面的示例相同:
在这种情况下,您使用字典 x来存储所有决策变量.这种方法很方便,因为字典可以将决策变量的名称或索引存储为键,将相应的LpVariable对象存储为值.列表或元组的LpVariable实例可以是有用的.
上面的代码产生以下结果:
让我们把这个问题变得更复杂和有趣.假设由于机器问题,工厂无法同时生产第一种和第三种产品.在这种情况下,最有利可图的解决方案是什么?
现在您有另一个逻辑约束:如果x ? 为正数,则x ? 必须为零,反之亦然.这是二元决策变量非常有用的地方.您将使用两个二元决策变量y ? 和y ?,它们将表示是否生成了第一个或第三个产品:
除了突出显示的行之外,代码与前面的示例非常相似.以下是差异:
这是解决方案:
事实证明,最佳方法是排除第一种产品而只生产第三种产品.
就像有许多资源可以帮助您学习线性规划和混合整数线性规划一样,还有许多具有 Python 包装器的求解器可用.这是部分列表:
其中一些库,如 Gurobi,包括他们自己的 Python 包装器.其他人使用外部包装器.例如,您看到可以使用 PuLP 访问 CBC 和 GLPK.
您现在知道什么是线性规划以及如何使用 Python 解决线性规划问题.您还了解到 Python 线性编程库只是本机求解器的包装器.当求解器完成其工作时,包装器返回解决方案状态、决策变量值、松弛变量、目标函数等.
方法在Python中是如何工作的
方法就是一个函数,它作为一个类属性而存在,你可以用如下方式来声明、访问一个函数:
Python
class Pizza(object):
...? def __init__(self, size):
...?? self.size = size
...? def get_size(self):
...?? return self.size
...
Pizza.get_size
unbound method Pizza.get_size
Python在告诉你,属性_get_size是类Pizza的一个未绑定方法.这是什么意思呢?很快我们就会知道答案:
Pizza.get_size()
Traceback (most recent call last):
File "stdin", line 1, in module
TypeError: unbound method get_size() must be called with Pizza instance as first argument (got nothing instead)
太棒了,现在用一个实例作为它的的第一个参数来调用,整个世界都清静了,如果我说这种调用方式还不是最方便的,你也会这么认为的;没错,现在每次调用这个方法的时候我们都不得不引用这个类,如果不知道哪个类是我们的对象,长期看来这种方式是行不通的.
那么Python为我们做了什么呢,它绑定了所有来自类_Pizza的方法以及该类的任何一个实例的方法.也就意味着现在属性get_size是Pizza的一个实例对象的绑定方法,这个方法的第一个参数就是该实例本身.
和我们预期的一样,现在不再需要提供任何参数给_get_size,因为它已经是绑定的,它的self参数会自动地设置给Pizza实例,下面代码是最好的证明:
m()
更有甚者,你都没必要使用持有Pizza对象的引用了,因为该方法已经绑定到了这个对象,所以这个方法对它自己来说是已经足够了.
也许,如果你想知道这个绑定的方法是绑定在哪个对象上,下面这种手段就能得知:
m.__self__
# You could guess, look at this:
m == m.__self__.get_size
True
显然,该对象仍然有一个引用存在,只要你愿意你还是可以把它找回来.
静态方法
静态方法是一类特殊的方法,有时你可能需要写一个属于这个类的方法,但是这些代码完全不会使用到实例对象本身,例如:
@staticmethod
def mix_ingredients(x, y):
return x + y
def cook(self):
return self.mix_ingredients(self.cheese, self.vegetables)
Python不再需要为Pizza对象实例初始化一个绑定方法,绑定方法同样是对象,但是创建他们需要成本,而静态方法就可以避免这些.
Pizza().cook is Pizza().cook
False
Pizza().mix_ingredients is Pizza.mix_ingredients
Pizza().mix_ingredients is Pizza().mix_ingredients
可以在子类中被覆盖,如果是把mix_ingredients作为模块的顶层函数,那么继承自Pizza的子类就没法改变pizza的mix_ingredients了如果不覆盖cook的话.
类方法
话虽如此,什么是类方法呢?类方法不是绑定到对象上,而是绑定在类上的方法.
...? @classmethod
...? def get_radius(cls):
...?? return cls.radius
Pizza.get_radius
bound method type.get_radius of class '__main__.Pizza'
Pizza().get_radius
Pizza.get_radius is Pizza().get_radius
Pizza.get_radius()
无论你用哪种方式访问这个方法,它总是绑定到了这个类身上,它的第一个参数是这个类本身(记住:类也是对象).
什么时候使用这种方法呢?类方法通常在以下两种场景是非常有用的:
def __init__(self, ingredients):
self.ingredients = ingredients
@classmethod
def from_fridge(cls, fridge):
return cls(fridge.get_cheese() + fridge.get_vegetables())
调用静态类:如果你把一个静态方法拆分成多个静态方法,除非你使用类方法,否则你还是得硬编码类名.使用这种方式声明方法,Pizza类名明永远都不会在被直接引用,继承和方法覆盖都可以完美的工作.
def __init__(self, radius, height):
self.radius = radius
self.height = height
def compute_area(radius):
def compute_volume(cls, height, radius):
return height * cls.compute_area(radius)
def get_volume(self):
return self.compute_volume(self.height, self.radius)
抽象方法
抽象方法是定义在基类中的一种方法,它没有提供任何实现,类似于Java中接口(Interface)里面的方法.
在Python中实现抽象方法最简单地方式是:
def get_radius(self):
raise NotImplementedError
任何继承自_Pizza的类必须覆盖实现方法get_radius,否则会抛出异常.
这种抽象方法的实现有它的弊端,如果你写一个类继承Pizza,但是忘记实现get_radius,异常只有在你真正使用的时候才会抛出来.
Pizza()
Pizza().get_radius()
NotImplementedError
还有一种方式可以让错误更早的触发,使用Python提供的abc模块,对象被初始化之后就可以抛出异常:
import abc
class BasePizza(object):
__metaclass__?= abc.ABCMeta
@abc.abstractmethod
"""Method that should do something."""
使用abc后,当你尝试初始化BasePizza或者任何子类的时候立马就会得到一个TypeError,而无需等到真正调用get_radius的时候才发现异常.
BasePizza()
TypeError: Can't instantiate abstract class BasePizza with abstract methods get_radius
混合静态方法、类方法、抽象方法
当你开始构建类和继承结构时,混合使用这些装饰器的时候到了,所以这里列出了一些技巧.
记住,声明一个抽象的方法,不会固定方法的原型,这就意味着虽然你必须实现它,但是我可以用任何参数列表来实现:
def get_ingredients(self):
"""Returns the ingredient list."""
class Calzone(BasePizza):
def get_ingredients(self, with_egg=False):
egg = Egg() if with_egg else None
return self.ingredients + egg
这样是允许的,因为Calzone满足BasePizza对象所定义的接口需求.同样我们也可以用一个类方法或静态方法来实现:
class DietPizza(BasePizza):
def get_ingredients():
return None
这同样是正确的,因为它遵循抽象类BasePizza设定的契约.事实上get_ingredients方法并不需要知道返回结果是什么,结果是实现细节,不是契约条件.
ingredient = ['cheese']
def get_ingredients(cls):
return cls.ingredients
别误会了,如果你认为它会强制子类作为一个类方法来实现get_ingredients那你就错了,它仅仅表示你实现的get_ingredients在BasePizza中是一个类方法.
default_ingredients = ['cheese']
return cls.default_ingredients
return ['egg'] + super(DietPizza, self).get_ingredients()
这个例子中,你构建的每个pizza都通过继承BasePizza的方式,你不得不覆盖get_ingredients方法,但是能够使用默认机制通过super()来获取ingredient列表.
打赏支持我翻译更多好文章,谢谢!