

利用集合的不重复属性,可以先转换至集合,再用list()函数转换回来即可.
比如,a是一个列表,a=list(set(a)),即可完成列表去重.
df.drop_duplicates('item_name')

方法一:
df.drop_duplicates('item_name').count()
方法二:
df['item_name'].nunique()
附:nunique()和unique()的区别:
unique()是以 数组形式(numpy.ndarray)返回列的所有唯一值(特征的所有唯一值)
nunique()即返回的是唯一值的个数
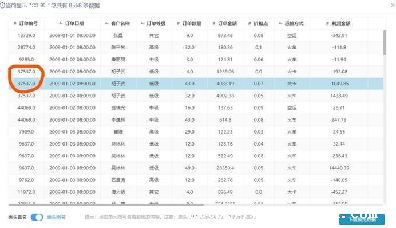
比如:df['item_name'].unique()
要求:将下表中经验列将按周统计的转换为经验不限,保留学历
方法二:定义函数
def dataInterval(ss):
? if '周' in ss:
? return ss
df1['经验'] = df1['经验'].apply(dataInterval)
利用set()函数,可以将列表去重,如:
case1:用集合的特性set(),去重后顺序会改变
case1.1:可以通过列表中索引(index)的方法保证去重后的顺序不变
第一种:用sum函数.
sum(lst)
第二种:循环方式.
def customer_sum(lst):
result = 0
for x in lst:
result+=x
return result
while lst:
temp = lst.pop(0)
result+=temp
if name ==" main ":
print customer_sum(lst)
第三种:递推求和
def add(lst,result):
if lst:
temp+=result
return add(lst,temp)
else:
print add(lst,0)
第四种:reduce方式
print reduce(lambda x,y:x+y,lst)
print reduce(lambda x,y:x+y,lst,0)
def add(x,y):
return x+y
print reduce(add, lst)
print reduce(add, lst,0)
第一种:for循环判断
def statistics(lst):
dic = {}
for k in lst:
if not k in dic:

dic[k] = 1
dic[k] +=1
return dic
print(statistics(lst))
第二种:比较取巧的,先把列表用set方式去重,然后用列表的count方法
m = set(lst)
for x in m:
dic[x] = lst.count(x)
第三种:用reduce方式
def statistics(dic,k):
print reduce(statistics,lst,{})
或者
d = {}
d.extend(lst)
print reduce(statistics,d)
通过上面的例子发现,凡是要对一个集合进行操作的,并且要有一个统计结果的,能够用循环或者递归方式解决的问题,一般情况下都可以用reduce方式实现.
以上就是土嘎嘎小编为大家整理的python去重的函数相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!