

函数的递归调用
递归问题是一个说简单也简单,说难也有点难理解的问题.我想非常有必要对其做一个总结.
首先理解一下递归的定义,递归就是直接或间接的调用自身.而至于什么时候要用到递归,递归和非递归又有那些区别?又是一个不太容易掌握的问题,更难的是对于递归调用的理解.下面我们就从程序+图形的角度对递归做一个全面的阐述.
我们从常见到的递归问题开始:
①. 阶层函数
#include iostream
using namespace std;
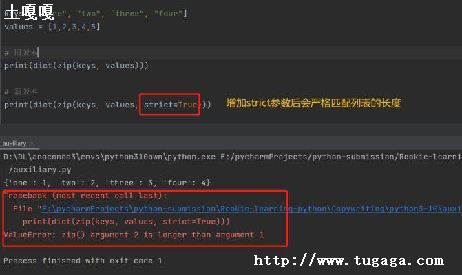
int factorial(int n)
{
if (n == 0)
return 1;
}
else
int result = factorial(n-1);
return n * result;
int main()
cout x endl;
return 0;
这是一个递归求阶层函数的实现.很多朋友只是知道该这么实现的,也清楚它是通过不断的递归调用求出的结果.但他们有些不清楚中间发生了些什么.下面我们用图对此做一个清楚的流程:
int Fib(int n)
if (n = 1)
return n;
这个函数递归与上面的那个有些不同.每次调用函数都会引起另外两次的调用.最后将结果逐级返回.
我们可以看出这个递归函数同样在调用后买的函数时,前面的不退出而是在等待后面的结果,最后求出总结果.这就是递归.
void recursiveFunction1(int num)
cout num endl;
recursiveFunction1(num+1);
recursiveFunction1(0);
运行结果:
该程序中有两个递归函数.传递同样的参数,但他们的输出结果刚好相反.理解这两个函数的调用过程可以很好的帮助我们理解递归:
我想能够把上面三个函数的递归调用过程理解了,你已经把递归调用理解的差不多了.并且从上面的递归调用中我们可以总结出递归的一个规律:他是逐级的调用,而在函数结束的时候是从最后面往前反序的结束.这种方式是很占用资源,也很费时的.但是有的时候使用递归写出来的程序很容易理解,很易读.
为什么使用递归:
①. 有时候使用递归写出来的程序很容易理解,很易读.
递归的条件:
并不是说所有的问题都可以使用递归解决,他必须的满足一定的条件.即有一个出口点.也就是说当满足一定条件时,程序可以结束,从而完成递归调用,否则就陷入了无限的递归调用之中了.并且这个条件还要是可达到的.
递归有哪些优点:
易读,容易理解,代码一般比较短.
递归有哪些缺点:
占用内存资源多,费时,效率低下.
所以呢在我们写程序的时候不要轻易的使用递归,虽然他有他的优点,但是我们要在易读性和空间,效率上多做权衡.一般情况下我们还是使用非递归的方法解决问题.若一个算法非递归解法非常难于理解.我们使用递归也未尝不可.如:二叉树的遍历算法.非递归的算法很难与理解.而相比递归算法就容易理解很多.
对于递归调用的问题,我们在前一段时间写图形学程序时,其中有一个四连同填充算法就是使用递归的方法.结果当要填充的图形稍微大一些时,程序就自动关闭了.这不是一个人的问题,所有人写出来的都是这个问题.当时我们给与的解释就是堆栈溢出.就多次递归调用占用太多的内存资源致使堆栈溢出,程序没有内存资源执行下去,从而被操作系统强制关闭了.这是一个真真切切的例子.所以我们在使用递归的时候需要权衡再三.
python的常用内置函数
①abs() 函数返回数字的绝对值
dict()
{} ? ? ?#创建一个空字典类似于u={},字典的存取方式一般为key-value
help('math')查看math模块的用处
help(a)查看列表list帮助信息
dir(help)
['__call__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
a
①.0
next(it)
id(a)
a=["tom","marry","leblan"]
list(enumerate(a))
oct(10)
①.0. bin() 返回一个整数 int 或者长整数 long int 的二进制表示
bin(10)
'0b1010'
'0b1111'
①.1.eval() 函数用来执行一个字符串表达式,并返回表达式的值
f=open('test.txt')
bool()
False
bool(1)
True
bool(10)
bool(10.0)
isinstance(a,int)
isinstance(a,str)
class ? User(object):
? ? def__init__(self):
class Persons(User):
? ? ? ? ? super(Persons,self).__init__()
float(1)
①0
float(10)
①.0.0
iter(a)
for i in iter(a):
... ? ? ? ? print(i)
...
tuple(a)
s = "playbasketball"
len(s)
len(a)
class User(object):
? ?def __init__(self,name):
? ? ? ? ? ? self.name = name
? def get_name(self):
? ? ? ? ? ? return self.get_name
? @property
? ?def name(self):
? ? ? ? ? ?return self_name
list(b)
range(10)
range(0, 10)
class w(object):
a = w()
getattr(a,'s')
complex(1)
(1+0j)
complex("1")
max(b)
class Num(object):
...? ? a=1
.. print1 = Num()
print('a=',print1.a)
a= 1
print('b=',print1.b)
print('c=',print1.c)
delattr(Num,'b')
Traceback (most recent call last):? File "", line 1, inAttributeError: 'Num' object has no attribute 'b'
hash("tom")
a= set("tom")
b = set("marrt")
a,b
({'t', 'm', 'o'}, {'m', 't', 'a', 'r'})
ab#交集
{'t', 'm'}
a|b#并集
{'t', 'm', 'r', 'o', 'a'}
a-b#差集
{'o'}
数学相关
abs(a) : 求取绝对值.abs(-1)
sorted(list) : 排序,返回排序后的list.
类型转换
int(str) : 转换为int型.int('1') 1
float(int/str) : 将int型或字符型转换为浮点型.float('1') 1.0
str(int) : 转换为字符型.str(1) '1'
bool(int) : 转换为布尔类型. str(0) False str(None) False
enumerate(iterable) : 返回一个枚举对象.
相关操作
exec() : 执行python语句. exec('print("Python")') Python
type():返回一个对象的类型.
id(): 返回一个对象的唯一标识值.
help():调用系统内置的帮助系统.
isinstance():判断一个对象是否为该类的一个实例.
issubclass():判断一个类是否为另一个类的子类.
globals() : 返回当前全局变量的字典.
next(iterator[, default]) : 接收一个迭代器,返回迭代器中的数值,如果设置了default,则当迭代器中的元素遍历后,输出default内容.
reversed(sequence) : 生成一个反转序列的迭代器. reversed('abc') ['c','b','a']
不了方便记忆,没有其它特别的含义. 还有众多的库名也是以PY开头.也是区别于其它语言的标志.
保留字即关键字,我们不能把它们用作任何标识符名称.Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
Python中单行注释以 # 开头,实例如下:
执行以上代码,输出结果为:
多行注释可以用多个 # 号,还有 ''' 和 """:
python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} .
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数.实例如下:
以下代码最后一行语句缩进数的空格数不一致,会导致运行错误:
以上程序由于缩进不一致,执行后会出现类似以下错误:
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠()来实现多行语句,例如:
在 [], {}, 或 () 中的多行语句,不需要使用反斜杠(),例如:
python中数字有四种类型:整数、布尔型、浮点数和复数.
实例
输出结果为:
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始.类和函数入口之间也用一行空行分隔,以突出函数入口的开始.
空行与代码缩进不同,空行并不是Python语法的一部分.书写时不插入空行,Python解释器运行也不会出错.但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构.
记住: 空行也是程序代码的一部分.
执行下面的程序在按回车键后就会等待用户输入:
以上代码中 ," "在结果输出前会输出两个新的空行.一旦用户按下 enter 键时,程序将退出.
Python可以在同一行中使用多条语句,语句之间使用分号(;)分割,以下是一个简单的实例:
缩进相同的一组语句构成一个代码块,我们称之代码组.
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组.
我们将首行及后面的代码组称为一个子句(clause).
如下实例:
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end="" :
以上实例执行结果为:
在 python 用 import 或者 from...import 来导入相应的模块.
将整个模块(somemodule)导入,格式为: import somemodule
从某个模块中导入某个函数,格式为: from somemodule import somefunction
从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
将某个模块中的全部函数导入,格式为: from somemodule import *
import sys print ( ' ================Python import mode========================== ' ) ; print ( ' 命令行参数为: ' ) for i in sys . argv : print ( i ) print ( ' python 路径为 ' , sys . path )
from sys import argv , path # 导入特定的成员 print ( ' ================python from import=================================== ' ) print ( ' path: ' , path ) # 因为已经导入path成员,所以此处引用时不需要加sys.path
很多程序可以执行一些操作来查看一些基本信息,Python可以使用-h参数查看各参数帮助信息:
目录
许多编程语言都有一个特殊的函数,当操作系统开始运行程序时会自动执行该函数.这个函数通常被命名为main(),并且依据语言标准具有特定的返回类型和参数.另一方面,Python解释器从文件顶部开始执行脚本,并且没有自动执行的特殊函数.
尽管如此,为程序的执行定义一个起始点有助于理解程序是如何运行的.Python程序员提出了几种方式对此进行实现.
本文结束时,您将了解以下内容:
Python中的基本main()函数
一些Python脚本中,包含一个函数定义和一个条件语句,如下所示:
此代码中,包含一个main()函数,在程序执行时打印Hello World!.此外,还包含一个条件(或if)语句,用于检查__name__的值并将其与字符串"__main__"进行比较.当if语句为True时,Python解释器将执行main()函数.更多关于Python条件语句的信息可以由此获得.
这种代码模式在Python文件中非常常见,它将作为脚本执行并导入另一个模块.为了帮助理解这段代码的执行方式,首先需要了解Python解释器如何根据代码的执行方式设置__name__.
Python中的执行模式
Python解释器执行代码有两种方式:
更多内容可参考如何运行Python脚本.无论采用哪种方式,Python都会定义一个名为__name__的特殊变量,该变量包含一个字符串,其值取决于代码的使用方式.
本文将如下示例文件保存为execution_methods.py,以 探索 代码如何根据上下文改变行为:
在此文件中,定义了三个对print()函数的调用.前两个打印一些介绍性短语.第三个print()会先打印短语The value __name__ is,之后将使用Python内置的repr()函数打印出__name__变量.
在Python中,repr()函数将对象转化为供解释器读取的形式.上述示例通过使用repr()函数来强调__name__的值为字符串.更多关于repr()的内容可参考Python文档.
在本文中,您将随处可见文件(file),模块(module)和脚本(script)这三个字眼.实际上,三者之间并无太大的差别.不过,在强调代码目的时,还是存在细微的差异:
"如何运行Python脚本"一文也讨论了三者的差别.
基于命令行执行
在这类方法中,Python脚本将通过命令行来执行.
命令行环境
不同的操作系统在使用命令行执行代码时存在细微的差异.
在Linux和macOS中,通常使用如下命令:
在Windows上,命令提示符通常如下所示:
无论哪种操作系统,本文的Python脚本的输出结果都是相同的.所以呢本文以Linux和macOS为例.
使用命令行执行execution_methods.py,如下所示:
在这个示例中,__name__具有值'__main__',其中引号(')表明该值为字符串类型.
请记住,在Python中,使用单引号(')和双引号(")定义的字符串没有区别.更多关于字符串的内容请参考Python的基本数据类型.
如果在脚本中包含"shebang行"并直接执行它(./execution_methods.py),或者使用IPython或Jupyter Notebook的%run,将会获取相同的结果.
添加-m参数将会运行包中__main__.py的代码.更多关于__main__.py文件的内容可参考如何将开源Python包发布到PyPI中.
在三种情况中,__name__都具有相同的值:字符串'__main__'.
技术细节:Python文档中具体定义了__name__何时取值为'__main__'.
__name__与__doc__,__package__和其他属性一起存储在模块的全局命名空间.更多关于属性的信息可参考Python数据模型文档,特别是关于模块和包的信息,请参阅Python Import文档.
导入模块或解释器
此时此刻呢是Python解释器执行代码的第二种方式:导入.在开发模块或脚本时,可以使用import关键字导入他人已经构建的模块.
在导入过程中,Python执行指定模块中定义的语句(但仅在第一次导入模块时).要演示导入execution_methods.py文件的结果,需要启动Python解释器,然后导入execution_methods.py文件:
在此代码输出中,Python解释器执行了三次print()函数调用.前两行由于没有变量,在输出方面与在命令行上作为脚本执行时完全相同.但是第三个输出存在差异.
当Python解释器导入代码时,__name__的值与要导入的模块的名称相同.您可以通过第三行的输出了解这一点.__name__的值为'execution_methods',是Python导入的.py文件.
注意如果您在没有退出Python时再次导入模块,将不会有输出.
注意:更多关于导入在Python中如何工作的内容请参考官方文档和Python中的绝对和相对导入.
Main函数的最佳实践
既然您已经了解两种执行方式上的差异,那么掌握一些最佳实践方案还是很有用的.它们将适用于编写作为脚本运行的代码或者在另一个模块导入的代码.
如下是四种实践方式:
将大部分代码放入函数或类中
请记住,Python解释器在导入模块时会执行模块中的所有代码.有时如果想要实现用户可控的代码,会导致一些副作用,例如:
在这种情况下,想要实现用户控制触发此代码的执行,而不是让Python解释器在导入模块时执行代码.
所以呢,最佳方法是将大部分代码包含在函数或类中.这是因为当Python解释器遇到def或class关键字时,它只存储这些定义供以后使用,并且在用户通知之前不会实际执行.
将如下代码保存在best_practices.py以证明这个想法:
在此代码中,首先从time模块中导入sleep().
在这个示例中,参数以秒的形式传入sleep()函数中,解释器将暂停一段时间再运行.随后,使用print()函数打印关于代码描述的语句.
之后,定义一个process_data()函数,执行如下五项操作:
在命令行中执行
当你将此文件作为脚本用命令行执行时会发生什么呢?
Python解释器将执行函数定义之外的from time import sleep和print(),之后将创建函数process_data().然后,脚本将退出而不做任何进一步的操作,因为脚本没有任何执行process_data()的代码.
如下是这段脚本的执行结果:
我们今天这一节看到的输出是第一个print()的结果.注意,从time导入和定义process_data()函数不产生结果.具体来说,调用定义在process_data()内部的print()不会打印结果.
导入模块或解释器执行
在会话(或其他模块)中导入此文件时,Python解释器将执行相同的步骤.
Python解释器导入文件后,您可以使用已导入模块中定义的任何变量,类或函数.为了证明这一点,我们将使用可交互的Python解释器.启动解释器,然后键入import best_practices:
导入best_practices.py后唯一的输出来自process_data()函数外定义的print().导入模块或解释器执行与基于命令行执行类似.
使用__name__控制代码的执行
如何实现基于命令行而不使用Python解释器导入文件来执行呢?
您可以使用__name__来决定执行上下文,并且当__name__等于"__main__"时才执行process_data().在best_practices.py文件中添加如下代码:
这段代码添加了一个条件语句来检验__name__的值.当值为"__main__"时,条件为True.记住当__name__变量的特殊值为"__main__"时意味着Python解释器会执行脚本而不是将其导入.
现在,在命令行中运行best_practices.py,并观察输出的变化:
首先,输出显示了process_data()函数外的print()的调用结果.
之后,data的值被打印.因为当Python解释器将文件作为脚本执行时,变量__name__具有值"__main__",所以呢条件语句被计算为True.
此时此刻呢,脚本将调用process_data()并传入data进行修改.当process_data执行时,将输出一些状态信息.最终,将输出modified_data的值.
现在您可以验证从解释器(或其他模块)导入best_practices.py后发生的事情了.如下示例演示了这种情况:
注意,当前结果与将条件语句添加到文件末尾之前相同.因为此时__name__变量的值为"best_practices",所以呢条件语句结果为False,Python将不执行process_data().
创建名为main()的函数来包含要运行的代码
现在,您可以编写作为脚本由从命令行执行并导入且没有副作用的Python代码.此时此刻呢,您将学习如何编写代码并使其他程序员能轻松地理解其含义.
许多语言,如C,C++,Java以及其他的一些语言,都会定义一个叫做main()的函数,当编译程序时,操作系统会自动调用该函数.此函数通常被称为入口点(entry point),因为它是程序进入执行的起始位置.
相比之下,Python没有一个特殊的函数作为脚本的入口点.实际上在Python中可以将入口点定义成任何名称.
尽管Python不要求将函数命名为main(),但是最佳的做法是将入口点函数命名为main().这样方便其他程序员定位程序的起点.
此外,main()函数应该包含Python解释器执行文件时要运行的任何代码.这比将代码放入条件语块中更好,因为用户可以在导入模块时重复使用main()函数.
修改best_practices.py文件如下所示:
在这个示例中,定义了一个main()函数,它包含了上面的条件语句块.之后修改条件语块执行main().如果您将此代码作为脚本运行或导入,将获得与上一节相同的输出.
在main()中调用其他函数
另一种常见的实现方式是在main()中调用其他函数,而不是直接将代码写入main().这样做的好处在于可以实现将几个独立运行的子任务整合.
例如,某个脚本有如下功能:
如果在单独的函数中各自实现这些子任务,您(或其他用户)可以很容易地实现代码重用.之后您可以在main()函数中创建默认的工作流.
您可以根据自己的情况选择是否使用此方案.将任务拆分为多个函数会使重用更容易,但会增加他人理解代码的难度.
首先,从read_data_from_web()中创建data.将data作为参数传入process_data(),之后将返回modified_data.最后,将modified_data传入write_data_to_database().
脚本的最后两行是条件语块用于验证__name__,并且如果if语句为True,则执行main().
在命令行中运行如下所示:
根据执行结果,Python解释器在执行main()函数时,将依次执行read_data_from_web(),process_data()以及write_data_to_database().当然,您也可以导入best_practices.py文件并重用process_data()作为不同的数据输入源,如下所示:
在此示例中,导入了best_practices并且将其简写为bp.
导入过程会导致Python解释器执行best_practices.py的全部代码,所以呢输出显示解释文件用途的信息.
然后,从文件中存储数据而不是从Web中读取数据.之后,可以重用best_practices.py文件中的process_data()和write_data_to_database()函数.在此情况下,可以利用代码重写来取代在main()函数中实现全部的代码逻辑.
实践总结
以下是Python中main()函数的四个关键最佳实践:
结论
恭喜!您现在已经了解如何创建Python main()函数了.
今天小编给大家带来得是如下内容:
现在,您可以开始编写一些非常棒的关于Python main()函数代码啦!