

我尝试来回答你几个问题:
①.、Go有什么优势
可直接编译成机器码,不依赖其他库,glibc的版本有一定要求,部署就是扔一个文件上去就完成了.
静态类型语言,但是有动态语言的感觉,静态类型的语言就是可以在编译的时候检查出来隐藏的大多数问题,动态语言的感觉就是有很多的包可以使用,写起来的效率很高.
语言层面支持并发,这个就是Go最大的特色,天生的支持并发,我曾经说过一句话,天生的基因和整容是有区别的,大家一样美丽,但是你喜欢整容的还是天生基因的美丽呢?Go就是基因里面支持的并发,可以充分的利用多核,很容易的使用并发.
内置runtime,支持垃圾回收,这属于动态语言的特性之一吧,虽然目前来说GC不算完美,但是足以应付我们所能遇到的大多数情况,特别是Go1.1之后的GC.
丰富的标准库,Go目前已经内置了大量的库,特别是网络库非常强大,我最爱的也是这部分.
内置强大的工具,Go语言里面内置了很多工具链,最好的应该是gofmt工具,自动化格式化代码,能够让团队review变得如此的简单,代码格式一模一样,想不一样都很困难.
服务器编程,以前你如果使用C或者C++做的那些事情,用Go来做很合适,例如处理日志、数据打包、虚拟机处理、文件系统等.
分布式系统,数据库代理器等
内存数据库,前一段时间google开发的groupcache,couchbase的部分组建
云平台,目前国外很多云平台在采用Go开发,CloudFoundy的部分组建,前VMare的技术总监自己出来搞的apcera云平台.
nsq:bitly开源的消息队列系统,性能非常高,目前他们每天处理数十亿条的消息
docker:基于lxc的一个虚拟打包工具,能够实现PAAS平台的组建.
skynet:分布式调度框架
Doozer:分布式同步工具,类似ZooKeeper
Heka:mazila开源的日志处理系统
cbfs:couchbase开源的分布式文件系统
tsuru:开源的PAAS平台,和SAE实现的功能一模一样
god:类似redis的缓存系统,但是支持分布式和扩展性
gor:网络流量抓包和重放工具
很多朋友可能知道Go语言的优势在哪,却不知道Go语言适合用于哪些地方.
①.0、 Tsuru:开源的PAAS平台,和SAE实现的功能一模一样.
以上的就是关于go语言能做什么的内容介绍了.
docker:基于lxc的一个虚拟打包工具,能够实现PAAS平台的组建.这就是已经有记录的,go语言能够做什么的统计,希望能帮到你
重点提示:
这样我们就启动了一个 nsqd 的实例
编写一个消息生产者
nsq_single_product.go
编写一个消息消费者
nsq_single_consumer.go
添加第一个实例
添加第二个实例
消息生产者
nsq_cluster_product.go
消息消费者
nsq_cluster_consumer.go
① 介绍
最近在研究一些消息中间件,常用的MQ如RabbitMQ,ActiveMQ,Kafka等.NSQ是一个基于Go语言的分布式实时消息平台,它基于MIT开源协议发布,由bitly公司开源出来的一款简单易用的消息中间件.
①1 Features
①.). Distributed
NSQ提供了分布式的,去中心化,且没有单点故障的拓扑结构,稳定的消息传输发布保障,能够具有高容错和HA(高可用)特性.
NSQ支持水平扩展,没有中心化的brokers.内置的发现服务简化了在集群中增加节点.同时支持pub-sub和load-balanced 的消息分发.
NSQ非常容易配置和部署,生来就绑定了一个管理界面.二进制包没有运行时依赖.官方有Docker image.
官方的 Go 和 Python库都有提供.而且为大多数语言提供了库.
NSQ推荐通过他们相应的nsqd实例使用协同定位发布者,这意味着即使面对网络分区,消息也会被保存在本地,直到它们被一个消费者读取.更重要的是,发布者不必去发现其他的nsqd节点,他们总是可以向本地实例发布消息.
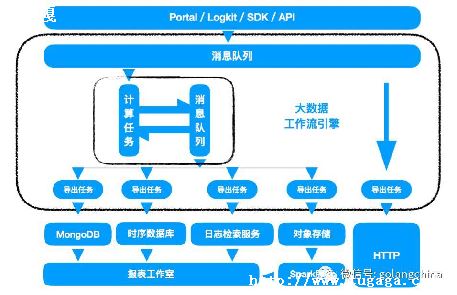
NSQ
首先,一个发布者向它的本地nsqd发送消息,要做到这点,首先要先打开一个连接,然后发送一个包含topic和消息主体的发布命令,在这种情况下,我们将消息发布到事件topic上以分散到我们不同的worker中.
nsqd
每个channel的消息都会进行排队,直到一个worker把他们消费,如果此队列超出了内存限制,消息将会被写入到磁盘中.Nsqd节点首先会向nsqlookup广播他们的位置信息,一旦它们注册成功,worker将会从nsqlookup服务器节点上发现所有包含事件topic的nsqd节点.
nsqlookupd
①.)客户表示已经准备好接收消息
这确保了消息丢失唯一可能的情况是不正常结束 nsqd 进程.在这种情况下,这是在内存中的任何信息(或任何缓冲未刷新到磁盘)都将丢失.
如何防止消息丢失是最重要的,即使是这个意外情况可以得到缓解.一种解决方案是构成冗余 nsqd对(在不同的主机上)接收消息的相同部分的副本.因为你实现的消费者是幂等的,以两倍时间处理这些消息不会对下游造成影响,并使得系统能够承受任何单一节点故障而不会丢失信息.
单个 nsqd 实例被设计成可以同时处理多个数据流.流被称为"话题"和话题有 1 个或多个"通道".每个通道都接收到一个话题中所有消息的拷贝.在实践中,一个通道映射到下行服务消费一个话题.
efficiency
因为NSQ没有在守护程序之间共享信息,所以它从一开始就是为了分布式操作而生.个别的机器可以随便宕机随便启动而不会影响到系统的其余部分,消息发布者可以在本地发布,即使面对网络分区.
这种"分布式优先"的设计理念意味着NSQ基本上可以永远不断地扩展,需要更高的吞吐量?那就添加更多的nsqd吧.唯一的共享状态就是保存在lookup节点上,甚至它们不需要全局视图,配置某些nsqd注册到某些lookup节点上这是很简单的配置,唯一关键的地方就是消费者可以通过lookup节点获取所有完整的节点集.清晰的故障事件――NSQ在组件内建立了一套明确关于可能导致故障的的故障权衡机制,这对消息传递和恢复都有意义.虽然它们可能不像Kafka系统那样提供严格的保证级别,但NSQ简单的操作使故障情况非常明显.
不像其他的队列组件,NSQ并没有提供任何形式的复制和集群,也正是这点让它能够如此简单地运行,但它确实对于一些高保证性高可靠性的消息发布没有足够的保证.我们可以通过降低文件同步的时间来部分避免,只需通过一个标志配置,通过EBS支持我们的队列.但是这样仍然存在一个消息被发布后马上死亡,丢失了有效的写入的情况.
虽然Kafka由一个有序的日志构成,但NSQ不是.消息可以在任何时间以任何顺序进入队列.在我们使用的案例中,这通常没有关系,因为所有的数据都被加上了时间戳,但它并不适合需要严格顺序的情况.
NSQ对于超时系统,它使用了心跳检测机制去测试消费者是否存活还是死亡.很多原因会导致我们的consumer无法完成心跳检测,所以在consumer中必须有一个单独的步骤确保幂等性.
本文将nsq集群具体的安装过程略去,大家可以自行参考官网,比较简单.这部分介绍下笔者实验的拓扑,以及nsqadmin的go语言使用什么消息队列相关咨询.
topology
NSQ基本没有配置文件,配置通过命令行指定参数.
主要命令如下:
LOOKUPD命令
NSQD命令
工具类,消费后存储到本地文件.
发布一条消息
对Streams的详细信息进行查看,包括NSQD节点,具体的channel,队列中的消息数,连接数等信息.
nsqadmin
channel
列出所有的NSQD节点:
nodes
消息的统计:
msgs
lookup主机的列表:
hosts
NSQ基本核心就是简单性,是一个简单的队列,这意味着它很容易进行故障推理和很容易发现bug.消费者可以自行处理故障事件而不会影响系统剩下的其余部分.
事实上,简单性是我们决定使用NSQ的首要因素,这方便与我们的许多其他软件一起维护,通过引入队列使我们得到了堪称完美的表现,通过队列甚至让我们增加了几个数量级的吞吐量.越来越多的consumer需要一套严格可靠性和顺序性保障,这已经超过了NSQ提供的简单功能.
结合我们的业务系统来看,对于我们所需要传输的发票消息,相对比较敏感,无法容忍某个nsqd宕机,或者磁盘无法使用的情况,该节点堆积的消息无法找回.这是我们没有选择该消息中间件的主要原因.简单性和可靠性似乎并不能完全满足.相比Kafka,ops肩负起更多负责的运营.另一方面,它拥有一个可复制的、有序的日志可以提供给我们更好的服务.但对于其他适合NSQ的consumer,它为我们服务的相当好,我们期待着继续巩固它的坚实的基础.