

因为HashMap一次次添加在对象内部并不是按照先后顺序添加的,我给你说说结果:
当只加第一个映射时,HashMap的打印结果是:
关键代码:
aa.put("1","java");
System.out.println(aa) ;
结果:
{1=java}
第二次:
第三次:
第四次:
第五次:
第六次:
第七次:
由以上结果我们可以看出来,在HashMap里,添加顺序并不是按从前向后的顺序添加的,也不是按从后向前添加的,在HashMap的文挡帮助里有这么一句话:"此类不保证映射的顺序,特别是它不保证该顺序恒久不变.",如果你又想用Map又想保持顺序,可以使用LinkedHashMap,它和HashMap一样,但是可以保证插入顺序,但是这样也增加了一点点开销.
根据你上面的提示和程序里的要求,修改了Database,新增了衣服的方法.每次计算的价格可以写成共通方法.希望其他人有好的建议也发上来.
import java.util.HashMap;
import java.util.Map;
public class Database {
private MapInteger, McBean data = new HashMapInteger, McBean();
public Database(){
McBean bean = new McBean();
bean.setNid(1);
bean.setSname("地瓜");
bean.setSdescription("新鲜的地瓜");
data.put(1, bean);
bean = new McBean();
bean.setSname("土豆");
bean.setSdescription("又好又大的土豆");
bean.setSname("丝瓜");
bean.setSdescription("本地丝瓜");
bean.setSname("衣服");
bean.setSdescription("衣服");
}
public McBean getMcBean(int nid){
return data.get(nid);
public class McBean {
private Integer nid; //商品编号
private String sname; //名称
private double nprice; //价格
private String sdescription; //描述
public Integer getNid() {
return nid;
public void setNid(Integer nid) {
this.nid = nid;
public String getSname() {
return sname;
public void setSname(String sname) {
this.sname = sname;
public double getNprice() {
return nprice;
public void setNprice(double nprice) {
this.nprice = nprice;
public String getSdescription() {
return sdescription;
public void setSdescription(String sdescription) {
this.sdescription = sdescription;
public class OrderItemBean {
private McBean mcbean; //商品
private int count; //商品数量
public McBean getMcbean() {
return mcbean;
public void setMcbean(McBean mcbean) {
this.mcbean = mcbean;
public int getCount() {
return count;
public void setCount(int count) {
this.count = count;
import java.util.Iterator;
import java.util.Set;
public class ShoppingCar {
private double totalPrice; //购物车所有商品总价格
private int totalCount; //购物车所有商品数量
private MapInteger,OrderItemBean itemMap; //商品编号与订单项的键值对
public ShoppingCar(){
//初始化购物车
itemMap = new HashMapInteger, OrderItemBean();
Database db = new Database();
OrderItemBean orderItem1 = new OrderItemBean();
bean = db.getMcBean(1);
orderItem1.setMcbean(bean);
itemMap.put(1, orderItem1);
totalCount = itemMap.size();
totalPrice = 0;
Set set = itemMap.entrySet();
Iterator i = set.iterator();
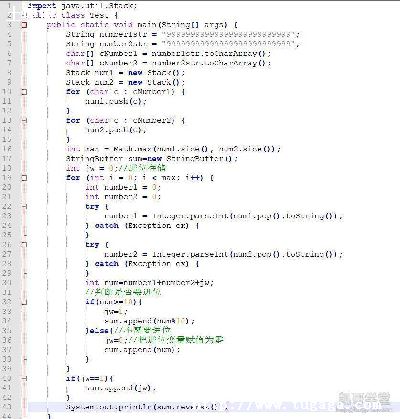
while(i.hasNext()){
Map.EntryInteger, OrderItemBean entry1=(Map.EntryInteger, OrderItemBean)i.next();
totalPrice += entry1.getValue().getCount() * entry1.getValue().getMcbean().getNprice();
public void buy(int nid){
//如果该商品是第一次购买,商品的信息从数据库获取,数据库的模拟代
//码见附录.itemMap增加一对键值对.
//如果不是第一次购买,则通过商品编号找到对应的定单项,然后更新定
//单项的商品数量.
//不管是否第一次购买,都得更新购物车的总价格和总数量.
McBean mcBean = new McBean();
OrderItemBean orderItem = new OrderItemBean();
if(itemMap.get(nid) == null) {
mcBean = db.getMcBean(nid);
orderItem.setMcbean(mcBean);
orderItem.setCount(1);
itemMap.put(nid, orderItem);
} else {
orderItem = itemMap.get(nid);
orderItem.setCount(orderItem.getCount() + 1);
public void delete(int nid){
//通过商品编号删除的对应的定单项,然后从更新购物车的总价格和总数量.
itemMap.remove(nid);
public void update(int nid, int count){
///通过商品编号找到对应的对应的定单项,修改商品数量.然后从更新购物车的总价格和总数量.
orderItem.setCount(count);
public void clear(){
//清空定单项,购物车的总价格和总数量清零.
itemMap.clear();
totalCount = 0;
public void show(){
//显示购物车的商品,格式如下:
//商品编号 商品名称 单价 购买数量 总价
//...
System.out.println("商品编号" + " " + "商品名称" + " " + "单价" + " " + "购买数量" + " " + "总价" );
int nid = entry1.getKey();
String name = entry1.getValue().getMcbean().getSname();
double price = entry1.getValue().getMcbean().getNprice();
int count = entry1.getValue().getCount();
double totalprice = price * count;
System.out.println(nid + " "+ name + " " + price + " " + count + " " + totalprice);
System.out.println("合计:总数量:" + totalCount + " 总价格:" + totalPrice+ "元");
public static void main(String[] args) {
ShoppingCar shoppingCar = new ShoppingCar();
shoppingCar.show();
System.out.println("--------------------------------");
shoppingCar.clear();
运行结果:
商品编号 商品名称 单价 购买数量 总价
--------------------------------
合计:总数量:0 总价格:0.0元
Bazel:来自Google的构建工具,可以快速、可靠地构建代码.官网
Gradle:使用Groovy(非XML)进行增量构建,可以很好地与Maven依赖管理配合工作.官网
Buck:Facebook构建工具.官网
字节码操作
编程方式操作字节码的开发库.
ASM:通用底层字节码操作和分析开发库.官网
Byte Buddy:使用流式API进一步简化字节码生成.官网
Byteman:在运行时通过DSL(规则)操作字节码进行测试和故障排除.官网
集群管理
在集群内动态管理应用程序的框架.
Apache Aurora:Apache Aurora是一个Mesos框架,用于长时间运行服务和定时任务(cron job).官网
Singularity:Singularity是一个Mesos框架,方便部署和操作.它支持Web Service、后台运行、调度作业和一次性任务.官网
代码分析
测量代码指标和质量工具.
Checkstyle:代码编写规范和标准静态分析工具.官网
Error Prone:将常见编程错误作为运行时错误报告.官网
FindBugs:通过字节码静态分析查找隐藏bug.官网
PMD:对源代码分析查找不良的编程习惯.官网
SonarQube:通过插件集成其它分析组件,对过去一段时间内的数据进行统计.官网
编译器生成工具
用来创建解析器、解释器或编译器的框架.
ANTLR:复杂的全功能自顶向下解析框架.官网
JavaCC:JavaCC是更加专门的轻量级工具,易于上手且支持语法超前预测.官网
外部配置工具
支持外部配置的开发库.
config:针对JVM语言的配置库.官网
owner:减少冗余配置属性.官网
约束满足问题求解程序
帮助解决约束满足问题的开发库.
Choco:可直接使用的约束满足问题求解程序,使用了约束规划技术.官网
JaCoP:为FlatZinc语言提供了一个接口,可以执行MiniZinc模型.官网
OptaPlanner:企业规划与资源调度优化求解程序.官网
持续集成
Bamboo:Atlassian解决方案,可以很好地集成Atlassian的其他产品.可以选择开源许可,也可以购买商业版.官网
CircleCI:提供托管服务,可以免费试用.官网
Codeship:提供托管服务,提供有限的免费模式.官网
Go:ThoughtWork开源解决方案.官网
Jenkins:支持基于服务器的部署服务.官网
TeamCity:JetBrain的持续集成解决方案,有免费版.官网
Travis:通常用作开源项目的托管服务.官网
Buildkite: 持续集成工具,用简单的脚本就能设置pipeline,而且能快速构建,可以免费试用.官网
CSV解析
简化CSV数据读写的框架与开发库
uniVocity-parsers:速度最快功能最全的CSV开发库之一,同时支持TSV与固定宽度记录的读写.官网
数据库
简化数据库交互的相关工具.
Apache Phoenix:HBase针对低延时应用程序的高性能关系数据库层.官网
Crate:实现了数据同步、分片、缩放、复制的分布式数据存储.除此之外还可以使用基于SQL的语法跨集群查询.官网
Flyway:简单的数据库迁移工具.官网
HikariCP:高性能JDBC连接工具.官网
JDBI:便捷的JDBC抽象.官网
Protobuf:Google数据交换格式.官网
SBE:简单二进制编码,是最快速的消息格式之一.官网
Wire:整洁轻量级协议缓存.官网
帮实现依赖翻转范式的开发库.?官网
Apache DeltaSpike:CDI扩展框架.官网
Guice:可以匹敌Dagger的轻量级注入框架.官网
开发流程增强工具
从最基本的层面增强开发流程.
AspectJ:面向切面编程(AOP)的无缝扩展.官网
Auto:源代码生成器集合.官网
DCEVM:通过修改JVM在运行时支持对已加载的类进行无限次重定义.官网
HotswapAgent:支持无限次重定义运行时类与资源.官网
Immutables:类似Scala的条件类.官网
JHipster:基于Spring Boot与AngularJS应用程序的Yeoman源代码生成器.官网
JRebel:无需重新部署,可以即时重新加载代码与配置的商业软件.官网
Lombok:减少冗余的代码生成器.官网
Spring Loaded:类重载代理.官网
vert.x:多语言事件驱动应用框架.官网
分布式应用
用来编写分布式容错应用的开发库和框架.
Akka:用来编写分布式容错并发事件驱动应用程序的工具和运行时.官网
Apache Storm:实时计算系统.官网
Apache ZooKeeper:针对大型分布式系统的协调服务,支持分布式配置、同步和名称注册.官网
Hazelcast:高可扩展内存数据网格.官网
Hystrix:提供延迟和容错.官网
JGroups:提供可靠的消息传递和集群创建的工具.官网
Orbit:支持虚拟角色(Actor),在传统角色的基础上增加了另外一层抽象.官网
Quasar:为JVM提供轻量级线程和角色.官网
分布式数据库
对应用程序而言,在分布式系统中的数据库看起来就像是只有一个数据源.
Apache Cassandra:列式数据库,可用性高且没有单点故障.官网
Apache HBase:针对大数据的Hadoop数据库.官网
Druid:实时和历史OLAP数据存储,在聚集查询和近似查询方面表现不俗.官网
Infinispan:针对缓存的高并发键值对数据存储.官网
发布
以本机格式发布应用程序的工具.
Bintray:发布二进制文件版本控制工具.可以于Maven或Gradle一起配合使用.提供开源免费版本和几种商业收费版本.官网
Central Repository:最大的二进制组件仓库,面向开源社区提供免费服务.Apache Maven默认使用Central?官网Repository,也可以在所有其他构建工具中使用.
IzPack:为跨平台部署建立创作工具(Authoring Tool).官网
JitPack:打包GitHub仓库的便捷工具.可根据需要构建Maven、Gradle项目,发布可立即使用的组件.官网
Nexus:支持代理和缓存功能的二进制管理工具.官网
packr:将JAR、资源和JVM打包成Windows、Linux和Mac OS X本地发布文件.官网
文档处理工具
处理Office文档的开发库.
jOpenDocument:处理OpenDocument格式(由Sun公司提出基于XML的文档格式).官网
函数式编程
函数式编程支持库.
Cyclops:支持一元(Monad)操作和流操作工具类、comprehension(List语法)、模式匹配、trampoline等特性.官网
Fugue:Guava的函数式编程扩展.官网
Functional Java:实现了多种基础和高级编程抽象,用来辅助面向组合开发(composition-oriented development).官网
Javaslang:一个函数式组件库,提供持久化数据类型和函数式控制结构.官网
游戏开发
游戏开发框架.
libGDX:全面的跨平台高级框架.官网
LWJGL:对OpenGL/CL/AL等技术进行抽象的健壮框架.官网
GUI
现代图形化用户界面开发库.
JavaFX:Swing的后继者.官网
Scene Builder:开发JavaFX应用的可视化布局工具.官网
高性能计算
涵盖了从集合到特定开发库的高性能计算相关工具.
Agrona:高性能应用中常见的数据结构和工具方法.官网
Disruptor:线程间消息传递开发库.官网
fastutil:快速紧凑的特定类型集合(Collection).官网
GS Collections:受Smalltalk启发的集合框架.官网
HPPC:基础类型集合.官网
Javolution:实时和嵌入式系统的开发库.官网
JCTools:JDK中缺失的并发工具.官网
Koloboke:Hash set和hash map.官网
Trove:基础类型集合.官网
High-scale-bli:Cliff Click 个人开发的高性能并发库官网
IDE
简化开发的集成开发环境.
Eclipse:老牌开源项目,支持多种插件和编程语言.官网
IntelliJ IDEA:支持众多JVM语言,是安卓开发者好的选择.商业版主要针对企业客户.官网
Thumbnailator:Thumbnailator是一个高质量Java缩略图开发库.官网
ZXing:支持多种格式的一维、二维条形码图片处理开发库.官网
Apache Batik:在Java应用中程序以SVG格式显示、生成及处理图像的工具集,包括SVG解析器、SVG生成器、SVG DOM等模块,可以集成使用也可以单独使用,还可以扩展自定义的SVG标签.官网
JSON
简化JSON处理的开发库.
Genson:强大且易于使用的Java到JSON转换开发库.官网
Gson:谷歌官方推出的JSON处理库,支持在对象与JSON之间双向序列化,性能良好且可以实时调用.官网
Jackson:与GSON类似,在频繁使用时性能更佳.官网
LoganSquare:基于Jackson流式API,提供对JSON解析和序列化.比GSON与Jackson组合方式效果更好.官网
Fastjson:一个Java语言编写的高性能功能完善的JSON库.官网
Kyro:快速、高效、自动化的Java对象序列化和克隆库.官网
JVM与JDK
目前的JVM和JDK实现.
OpenJDK:JDK开源实现.官网
基于JVM的语言
除Java外,可以用来编写JVM应用程序的编程语言.
Scala:融合了面向对象和函数式编程思想的静态类型编程语言.官网
Groovy:类型可选(Optionally typed)的动态语言,支持静态类型和静态编译.目前是一个Apache孵化器项目.官网
Clojure:可看做现代版Lisp的动态类型语言.官网
Ceylon:RedHat开发的面向对象静态类型编程语言.官网
Kotlin:JetBrain针对JVM、安卓和浏览器提供的静态类型编程语言.官网
Xtend:一种静态编程语言,能够将其代码转换为简洁高效的Java代码,并基于JVM运行.官网
日志
记录应用程序行为日志的开发库.
kibana:分析及可视化日志文件.官网
Logback:强健的日期开发库,通过Groovy提供很多有趣的选项.官网
logstash:日志文件管理工具.官网
Metrics:通过JMX或HTTP发布参数,并且支持存储到数据库.官网
机器学习
提供具体统计算法的工具.其算法可从数据中学习.
Apache Flink:快速、可靠的大规模数据处理引擎.官网
Apache Hadoop:在商用硬件集群上用来进行大规模数据存储的开源软件框架.官网
Apache Mahout:专注协同过滤、聚类和分类的可扩展算法.官网
Apache Spark:开源数据分析集群计算框架.官网
DeepDive:从非结构化数据建立结构化信息并集成到已有数据库的工具.官网
Weka:用作数据挖掘的算法集合,包括从预处理到可视化的各个层次.官网
QuickML:高效机器学习库.官网、GitHub
消息传递
Aeron:高效可扩展的单播、多播消息传递工具.官网
Apache ActiveMQ:实现JMS的开源消息代理(broker),可将同步通讯转为异步通讯.官网
Apache Camel:通过企业级整合模式(Enterprise Integration Pattern EIP)将不同的消息传输API整合在一起.官网
Apache Kafka:高吞吐量分布式消息系统.官网
Hermes:快速、可靠的消息代理(Broker),基于Kafka构建.官网
JBoss HornetQ:清晰、准确、模块化,可以方便嵌入的消息工具.官网
JeroMQ:ZeroMQ的纯Java实现.官网
Openfire:是开源的、基于XMPP、采用Java编程语言开发的实时协作服务器. Openfire安装和使用都非常简单,并可利用Web界面进行管理.?官网GitHub
Tigase: 是一个轻量级的可伸缩的 Jabber/XMPP 服务器.无需其他第三方库支持,可以处理非常高的复杂和大量的用户数,可以根据需要进行水平扩展.?官网
杂项
未分类其它资源.
Design Patterns:实现并解释了最常见的设计模式.官网
Jimfs:内存文件系统.官网
Lanterna:类似curses的简单console文本GUI函数库.官网
LightAdmin:可插入式CRUD UI函数库,可用来快速应用开发.官网
OpenRefine:用来处理混乱数据的工具,包括清理、转换、使用Web Service进行扩展并将其关联到数据库.官网
RoboVM:Java编写原生iOS应用.官网
Quartz:强大的任务调度库.官网
应用监控工具
监控生产环境中应用程序的工具.
AppDynamics:性能监测商业工具.官网
JavaMelody:性能监测和分析工具.官网
Kamon:Kamon用来监测在JVM上运行的应用程序.官网
New Relic:性能监测商业工具.官网
SPM:支持对JVM应用程序进行分布式事务追踪的性能监测商业工具.官网
Takipi:产品运行时错误监测及调试商业工具.官网
原生开发库
用来进行特定平台开发的原生开发库.
JNA:不使用JNI就可以使用原生开发库.此外,还为常见系统函数提供了接口.官网
自然语言处理
用来专门处理文本的函数库.
Apache OpenNLP:处理类似分词等常见任务的工具.官网
CoreNLP:斯坦佛CoreNLP提供了一组基础工具,可以处理类似标签、实体名识别和情感分析这样的任务.官网
LingPipe:一组可以处理各种任务的工具集,支持POS标签、情感分析等.官网
Mallet:统计学自然语言处理、文档分类、聚类、主题建模等.官网
网络
网络编程函数库.
Grizzly:NIO框架,在Glassfish中作为网络层使用.官网
Netty:构建高性能网络应用程序开发框架.官网
Undertow:基于NIO实现了阻塞和非阻塞API的Web服务器,在WildFly中作为网络层使用.官网
ORM
处理对象持久化的API.
Ebean:支持快速数据访问和编码的ORM框架.官网
EclipseLink:支持许多持久化标准,JPA、JAXB、JCA和SDO.官网
Hibernate:广泛使用、强健的持久化框架.Hibernate的技术社区非常活跃.官网
MyBatis:带有存储过程或者SQL语句的耦合对象(Couples object).官网
OrmLite:轻量级开发包,免除了其它ORM产品中的复杂性和开销.官网
Nutz:另一个SSH.官网,Github
JFinal:JAVA WEB + ORM框架.官网,Github
用来帮助创建PDF文件的资源.
Apache FOP:从XSL-FO创建PDF.官网
Apache PDFBox:用来创建和操作PDF的工具集.官网
DynamicReports:JasperReports的精简版.官网
iText:一个易于使用的PDF函数库,用来编程创建PDF文件.注意,用于商业用途时需要许可证.官网
JasperReports:一个复杂的报表引擎.官网
性能分析
性能分析、性能剖析及基准测试工具.
jHiccup:提供平台中JVM暂停的日志和记录.官网
JMH:JVM基准测试工具.官网
JProfiler:商业分析器.官网
LatencyUtils:测量和报告延迟的工具.官网
VisualVM:对运行中的应用程序信息提供了可视化界面.官网
YourKit Java Profiler:商业分析器.官网
响应式开发库
用来开发响应式应用程序的开发库.
Reactive Streams:异步流处理标准,支持非阻塞式反向压力(backpressure).官网
Reactor:构建响应式快速数据(fast-data)应用程序的开发库.官网
RxJava:通过JVM可观察序列(observable sequence)构建异步和基于事件的程序.官网
REST框架
用来创建RESTful 服务的框架.
Dropwizard:偏向于自己使用的Web框架.用来构建Web应用程序,使用了Jetty、Jackson、Jersey和Metrics.官网
Jersey:JAX-RS参考实现.官网
RESTEasy:经过JAX-RS规范完全认证的可移植实现.官网
RestX:基于注解处理和编译时源码生成的框架.官网
Spark:受到Sinatra启发的Java REST框架.官网
Swagger:Swagger是一个规范且完整的框架,提供描述、生产、消费和可视化RESTful Web Service.官网
Blade:国人开发的一个轻量级的MVC框架. 它拥有简洁的代码,优雅的设计.官网
科学计算与分析
用于科学计算和分析的函数库.
DataMelt:用于科学计算、数据分析及数据可视化的开发环境.官网
JGraphT:支持数学图论对象和算法的图形库.官网
JScience:用来进行科学测量和单位的一组类.官网
搜索引擎
文档索引引擎,用于搜索和分析.
Apache Solr:一个完全的企业搜索引擎.为高吞吐量通信进行了优化.官网
Elasticsearch:一个分布式、支持多租户(multitenant)全文本搜索引擎.提供了RESTful Web接口和无schema的JSON文档.官网
Apache Lucene:是一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎.官网
安全
用于处理安全、认证、授权或会话管理的函数库.
Apache Shiro:执行认证、授权、加密和会话管理.官网
Bouncy Castle,涵盖了从基础的帮助函数到PGP/SMIME操作.官网:多途加密开发库.支持JCA提供者(JCA provider)
Keycloak:为浏览器应用和RESTful Web Service集成SSO和IDM.目前还处于beta版本,但是看起来非常有前途.官网
PicketLink:PicketLink是一个针对Java应用进行安全和身份认证管理的大型项目(Umbrella Project).官网
序列化
用来高效处理序列化的函数库.
FlatBuffers:高效利用内存的序列化函数库,无需解包和解析即可高效访问序列化数据.官网
Kryo:快速、高效的对象图形序列化框架.官网
FST:提供兼容JDK的高性能对象图形序列化.官网
MessagePack:一种高效的二进制序列化格式.官网
应用服务器
用来部署应用程序的服务器.
Apache Tomcat:针对Servlet和JSP的应用服务器,健壮性好且适用性强.官网
Apache TomEE:Tomcat加Java EE.官网
Jetty:轻量级、小巧的应用服务器,通常会嵌入到项目中.官网
WebSphere Liberty:轻量级、模块化应用服务器,由IBM开发.官网
WildFly:之前被称作JBoss,由Red Hat开发.支持很多Java EE功能.官网
模板引擎
在模板中替换表达式的工具.
Apache Velocity:提供HTML页面模板、email模板和通用开源代码生成器模板.官网
FreeMarker:通用模板引擎,不需要任何重量级或自己使用的依赖关系.官网
Handlebars.java:使用Java编写的模板引擎,逻辑简单,支持语义扩展(semantic Mustache).官网
Thymeleaf:旨在替换JSP,支持XML文件的工具.官网
测试
测试内容从对象到接口,涵盖性能测试和基准测试工具.
Apache JMeter:功能性测试和性能评测.官网
Arquillian:集成测试和功能行测试平台,集成Java EE容器.官网
AssertJ:支持流式断言提高测试的可读性.官网
Awaitility:用来同步异步操作的DSL.官网
Cucumber:BDD测试框架.官网
Gatling:设计为易于使用、可维护的和高性能负载测试工具.官网
Hamcrest:可用来灵活创建意图(intent)表达式的匹配器.官网
JMockit:用来模拟静态、final方法等.官网
JUnit:通用测试框架.官网
Mockito:在自动化单元测试中创建测试对象,为TDD或BDD提供支持.官网
PowerMock: 支持模拟静态方法、构造函数、final类和方法、私有方法以及移除静态初始化器的模拟工具.官网
REST Assured:为REST/HTTP服务提供方便测试的Java DSL.官网
Selenide:为Selenium提供精准的周边API,用来编写稳定且可读的UI测试.官网
Selenium:为Web应用程序提供可移植软件测试框架.官网
Spock:JUnit-compatible framework featuring an expressive Groovy-derived specification language.官网兼容JUnit框架,支持衍生的Groovy范的语言.
TestNG:测试框架.官网
Truth:Google的断言和命题(proposition)框架.官网
Unitils:模块化测试函数库,支持单元测试和集成测试.官网
WireMock:Web Service测试桩(Stub)和模拟函数.官网
通用工具库
通用工具类函数库.
Apache Commons:提供各种用途的函数,比如配置、验证、集合、文件上传或XML处理等.官网
CRaSH:为运行进行提供CLI.官网
Gephi:可视化跨平台网络图形化操作程序.官网
Guava:集合、缓存、支持基本类型、并发函数库、通用注解、字符串处理、I/O等.官网
JADE:构建、调试多租户系统的框架和环境.官网
javatuples:正如名字表示的那样,提供tuple支持.尽管目前tuple的概念还有留有争议.官网
JCommander:命令行参数解析器.官网
网络爬虫
用于分析网站内容的函数库.
Apache Nutch:可用于生产环境的高度可扩展、可伸缩的网络爬虫.官网
JSoup:刮取、解析、操作和清理HTML.官网
Web框架
用于处理Web应用程序不同层次间通讯的框架.
Apache Tapestry:基于组件的框架,使用Java创建动态、强健的、高度可扩展的Web应用程序.官网
Apache Wicket:基于组件的Web应用框架,与Tapestry类似带有状态显示GUI.官网
Grails:Groovy框架,旨在提供一个高效开发环境,使用约定而非配置、没有XML并支持混入(mixin).官网
Ninja:Java全栈Web开发框架.非常稳固、快速和高效.官网
Pippo:小型、高度模块化的类Sinatra框架.官网
Play:使用约定而非配置,支持代码热加载并在浏览器中显示错误.官网
PrimeFaces:JSF框架,提供免费和带支持的商业版本.包括若干前端组件.官网
Ratpack:一组Java开发函数库,用于构建快速、高效、可扩展且测试完备的HTTP应用程序.官网
Spring Boot:微框架,简化了Spring新程序的开发过程.官网
Spring:旨在简化Java EE的开发过程,提供依赖注入相关组件并支持面向切面编程.官网
业务流程管理套件
流程驱动的软件系统构建.
jBPM:非常灵活的业务流程管理框架,致力于构建开发与业务分析人员之间的桥梁.官网
Activity:轻量级工作流和业务流程管理框架.官网?github
资源
社区
①数组把对象和数字形式的下标联系起来.它持有的是类型确定的对象,这样提取对象的时候就不用再作类型传递了.它可以是多维的,也可以持有primitive.但是创建之后它的容量不能改了.
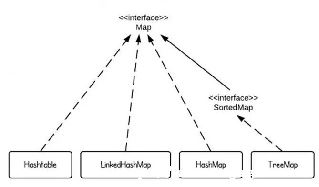
HashMap看重的是访问速度,而TreeMap看重键的顺序,因而它不如HashMap那么快.而LinkedHashMap则保持对象插入的顺序,但是也可以用LRU算法为它重新排序.
容器类库是你每天都会用到的工具,它能使程序更简洁,更强大并且更高效.
随着Java的进一步完善,它的功能和易用性也得到提高,我有理由相信Java在计算机语言中所占的位置也会更加牢固,让喜爱Java的人更加喜爱它.祝愿Java一路顺风!
说明:先从整体介绍了Java集合框架包含的接口和类,然后河北IT培训总结了集合框架中的一些基本知识和关键点,并结合实例进行简单分析.
①.、综述?所有集合类都位于java.util包下.
集合中只能保存对象(保存对象的引用变量).
(数组既可以保存基本类型的数据也可以保存对象).
当我们把一个对象放入集合中后,系统会把所有集合元素都当成Object类的实例进行处理.
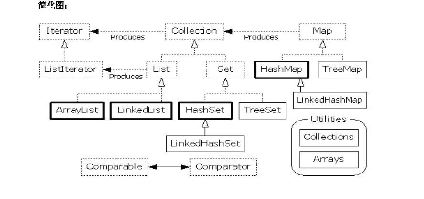
Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口,这两个接口又包含了一些接口或实现类.
Set、List和Map可以看做集合的三大类.
List集合是有序集合,集合中的元素可以重复,访问集合中的元素可以根据元素的索引来访问.
Set集合是无序集合,集合中的元素不可以重复,访问集合中的元素只能根据元素本身来访问(也是不能集合里元素不允许重复的原因).
Map集合中保存Key-value对形式的元素,访问时只能根据每项元素的key来访问其value.
对于Set、List和Map三种集合,最常用的实现类分别是HashSet、ArrayList和HashMap三个实现类.
(并发控制的集合类,以后有空研究下).
Collection接口定义操作集合元素的具体方法大家可以参考API文档,这里通过一个例子来说明Collection的添加元素、删除元素、返回集合中元素的个数以及清空集合元素的方法.