

具体函数有 set(),pop(),update(),items(),keys(),values(),get(),setdefault()
python 字典操作
二是使用dict本身提供的一个 get 方法,在Key不存在的时候,返回None:
print dics.get('a')
print dics.get('Paul')

None
dict.get(key,default=None) 两个选项 一个 key 一个 default= None ----default可以是任何strings(字符)
[方法]? dics.pop('key')
[方法] dic.setdefault(key, value)
a
dict的作用是建立一组 key 和一组 value 的映射关系,dict的key是不能重复的.
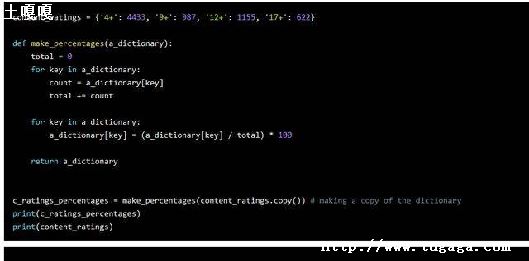
有的时候,我们只想要 dict 的 key,不关心 key 对应的 value,目的就是保证这个集合的元素不会重复,这时,set就派上用场了.
①.、get() 返回指定键的值,如果值不在字典中返回default值.
语法:dict.get(key,default=None)
参数:
key 字典中要查找的键.
default 如果指定键的值不存在时,返回该默认值值.
例:
print("Name is:%s"% dict.get('Name')+"\n"+ "Age is:%d"% dict.get('Age'))
显示结果为:
Name is:alex
print("Value is %s" % dict)
后台回复"大礼包",送你特别福利
上一篇:
正文
大家好,我是Pythn人工智能技术.
内置函数就是Python给你提供的,拿来直接用的函数,比如print.,input等.
abs() dict() help() min() setattr()
all() dir() hex() next() slice()
ascii() enumerate() input() oct() staticmethod()
bin() eval() int() open() str()
bool() exec() isinstance() ord() sum()
bytearray() ?lter() issubclass() pow() super()
bytes() ?oat() iter() print() tuple()
callable() format() len() property() type()
chr() frozenset() list() range() vars()
classmethod() getattr() locals() repr() zip()
compile() globals() map() reversed() __import__()
complex() hasattr() max() round()
delattr() hash() memoryview() set()
和数字相关 1. 数据类型
bool : 布尔型(True,False)
int : 整型(整数)
float : 浮点型(小数)
complex : 复数
bin() 将给的参数转换成二进制
otc() 将给的参数转换成八进制
hex() 将给的参数转换成十六进制
print(bin(10)) # 二进制:0b1010
print(hex(10)) # 十六进制:0xa
abs() 返回绝对值
round() 四舍五入
pow(a, b) 求a的b次幂, 如果有三个参数. 则求完次幂后对第三个数取余
sum() 求和
min() 求最小值
max() 求最大值
和数据结构相关 1. 序列
(1)列表和元组
list() 将一个可迭代对象转换成列表
tuple() 将一个可迭代对象转换成元组
reversed() 将一个序列翻转, 返回翻转序列的迭代器
slice() 列表的切片
lst = "土嘎嘎的粉丝们大家好啊"
it = reversed(lst) # 不会改变原列表. 返回一个迭代器, 设计上的一个规则
print(list(it)) #['啊', '好', '你']
str() 将数据转化成字符串
format() 与具体数据相关, 用于计算各种小数, 精算等.
s = "hello world!"
# hello world!
print(format(11, 'd' )) # ?进制:11
print(format(11, 'x' )) # 十六进制(?写字母):b
print(format(11, 'X' )) # 十六进制(大写字母):B
print(format(11, 'n' )) # 和d?样:11
print(format(11)) # 和d?样:11
bytes() 把字符串转化成bytes类型
print(ret) #bytearray(b'alex')
print(str(ret)) #bytearray(b'Alex')
ord() 输入字符找带字符编码的位置
chr() 输入位置数字找出对应的字符
ascii() 是ascii码中的返回该值 不是就返回u
print(chr(i), end=" ")
print(ascii("@")) #'@'
repr() 返回一个对象的string形式
print(repr(s)) # 原样输出,过滤掉转义字符 \n \t \r 不管百分号%
字典:dict 创建一个字典
集合:set 创建一个集合
frozenset() 创建一个冻结的集合,冻结的集合不能进行添加和删除操作.
len() 返回一个对象中的元素的个数
sorted() 对可迭代对象进行排序操作 (lamda)
语法:sorted(Iterable, key=函数(排序规则), reverse=False)
Iterable: 可迭代对象
key: 排序规则(排序函数), 在sorted内部会将可迭代对象中的每一个元素传递给这个函数的参数. 根据函数运算的结果进行排序
reverse: 是否是倒叙. True: 倒叙, False: 正序
lst.sort() # sort是list里面的一个方法
ll = sorted(lst) # 内置函数. 返回给你一个新列表 新列表是被排序的
#根据字符串长度给列表排序
lst = ['one', 'two', 'three', 'four', 'five', 'six']
def f(s):
return len(s)
l1 = sorted(lst, key=f, )
print(l1) #['one', 'two', 'six', 'four', 'five', 'three']
enumerate() 获取集合的枚举对象
lst = ['one','two','three','four','five']
for index, el in enumerate(lst,1): # 把索引和元素一起获取,索引默认从0开始. 可以更改
print(index)
print(el)
# 1
# one
# two
# three
# four
# five
all() 可迭代对象中全部是True, 结果才是True
any() 可迭代对象中有一个是True, 结果就是True
print(any([0,0,0,False,1,'good'])) #True
zip() 函数用于将可迭代的对象作为参数, 将对象中对应的元素打包成一个元组, 然后返回由这些元组组成的列表. 如果各个迭代器的元素个数不一致, 则返回列表长度与最短的对象相同
# (1, '醉乡民谣', '美国')
fiter() 过滤 (lamda)
语法:fiter(function. Iterable)
function: 用来筛选的函数. 在?lter中会自动的把iterable中的元素传递给function. 然后根据function返回的True或者False来判断是否保留留此项数据 , Iterable: 可迭代对象
搜索公众号顶级架构师后台回复"面试",送你一份惊喜礼包.
def func(i): # 判断奇数
l1 = filter(func, lst) #l1是迭代器
print(l1) #
map() 会根据提供的函数对指定序列列做映射(lamda)
语法 : map(function, iterable)
可以对可迭代对象中的每一个元素进行映射. 分别去执行 function
def f(i): return i
和作用域相关
locals() 返回当前作用域中的名字
globals() 返回全局作用域中的名字
def func():
a = 10
print(locals()) # 当前作用域中的内容
print(globals()) # 全局作用域中的内容
print("今天内容很多")
func()
# {'a': 10}
# {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__':
# '__spec__': None, '__annotations__': {}, '__builtins__':
# 'func': }
# 今天内容很多
和迭代器生成器相关
range() 生成数据
next() 迭代器向下执行一次, 内部实际使?用了__ next__()?方法返回迭代器的下一个项目
iter() 获取迭代器, 内部实际使用的是__ iter__()?方法来获取迭代器
print(i)
# 10
# 0
it = iter(lst) # __iter__()获得迭代器
print(it.__next__()) #1
字符串类型代码的执行
eval() 执行字符串类型的代码. 并返回最终结果
exec() 执行字符串类型的代码
compile() 将字符串类型的代码编码. 代码对象能够通过exec语句来执行或者eval()进行求值
print(a) #None
# 动态执行代码
exec("""
print(" 我是周杰伦")
""" )
func() #我是周杰伦
com = compile(code1, "", mode="exec") # compile并不会执行你的代码.只是编译
exec(com) # 执行编译的结果
print(name) #hello
输入输出
print() : 打印输出
input() : 获取用户输出的内容
print("hello", "world", sep="*", end="@") # sep:打印出的内容用什么连接,end:以什么为结尾
#hello*world@
内存相关
文件操作相关
open() : 用于打开一个文件, 创建一个文件句柄
f.read()
f.close()
模块相关
__ import__() : 用于动态加载类和函数
# 让用户输入一个要导入的模块
import os
name = input("请输入你要导入的模块:")
__import__(name) # 可以动态导入模块
帮 助
help() : 函数用于查看函数或模块用途的详细说明
print(help(str)) #查看字符串的用途
调用相关
callable() : 用于检查一个对象是否是可调用的. 如果返回True, object有可能调用失败, 但如果返回False. 那调用绝对不会成功
print(callable(a)) #False 变量a不能被调用
def f():
print("hello")
print(callable(f)) # True 函数是可以被调用的
查看内置属性
dir() : 查看对象的内置属性, 访问的是对象中的__dir__()方法
print(dir(tuple)) #查看元组的方法
你还有什么想要补充的吗?
技术君个人微信
添加技术君个人微信即送一份惊喜大礼包
→ 技术资料共享
→ 技术交流社群
--END--
往日热文:
Python程序员深度学习的"四大名著":
这四本书着实很不错!我们都知道现在机器学习、深度学习的资料太多了,面对海量资源,往往陷入到"无从下手"的困惑出境.而且并非所有的书籍都是优质资源,浪费大量的时间是得不偿失的.给大家推荐这几本好书并做简单介绍.
获得方式:
如下图所示,顺便说一下可能的报错问题:
dict()是python的一个内建函数,如果将dict自定义为一个python字典,在之后想调用dict()函数是会报出"TypeError: 'dict' object is not callable"的错误,只需将之前自定义的变量delete掉即可.
python字典的构成形式为:字典是Python语言中唯一的映射类型.
映射类型对象里哈希值(键,key)和悔樱闷指向的对象(值,value)是一对多的关系,通常被认为是可变的哈希表.
字典对象是可变的,它是一个容器类型,能存储任意个数的Python对象,其中也可包括其他容器类型.
字典类型与序列类型的区别:
①.、存取和访问数据的方式不同.
字典是Python中最强大的数据类型之一
使用字典的注意不能允许一键对应多个值;键必须是可哈希的.
len()返回字典的长度.
hash()返回对象的哈希值,可以用来判断一个对象能否用来作为字典的键.
dict()工厂函数,用来创建字典颂迹.
创建一个空字典自需要一对大括号即可,从已有的键-值对映射或关键字参数创建字典需要使用 dict 函数(类)
还可使用 关键字实参 (**kwargs)来调用这个函数,如下所示:
字典的基本操作与序列十分相似:
字典与序列的不同:
方法 clear 删除所有的字典项(key-value).
复制,得到原字典的一个新副本.
效果等同于调用 dict(d) 创建新字典.
copy() 执行的是 浅复制 ,若字典的值是一个可变对象,那么复制以后,相同一个键将关联到同一个对象,修改该对象,将同时修改两个字典.
模块copy中的函数deepcopy 可执行深复制.
方法fromkeys 创建一个新字典,其中包含指定的键,且每个键对应的值都是None,或者可以提供一个i额默认值.
方法get 为访问字典项提供了宽松的环境.通常,如果你试图访问字典中没有的项,将引发错误,而get直接返回None,或者可设置默认返回值.
当字典中不存在指定键时, setdefault(k,v) 添加一个指定键-值对;且返回指定键所关联的值.
这三个方法返回值属于一种名为 字典视图 的特殊类型.字典视图可用于迭代.另外,还可确定其长度以及对其执行成员资格检查.
这三个方法自大的特点是不可变,当你的接口试图对其他用户提供一个只读字典,而不希望他们修改的时候,这三个方法是很有用的;而且当原字典发生改变时,这些方法返回的对象也会跟着改变.
方法 pop 可用于获取与指定键相关联的值,并将该键-值对从字典中删除.
popitem随机删除一个键-值对,并返回一个二维的元组 (key, value) ,因为字典是无序的,所以其弹出的顺序也是不确定的.
书上说,这个方法在大数据量时执行效率很高,但没有亲测.
方法update 使用一个字典中的项来更新另一个字典.
以上就是土嘎嘎小编为大家整理的python词典函数相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!