

Go 由于不支持泛型而臭名昭著,但最近,泛型已接近成为现实.Go 团队实施了一个看起来比较稳定的设计草案,并且正以源到源翻译器原型的形式获得关注.本文讲述的是泛型的最新设计,以及如何自己尝试泛型.
例子

FIFO Stack
假设你要创建一个先进先出堆栈.没有泛型,你可能会这样实现:
type?Stack?[]interface{}func?(s?Stack)?Peek()?interface{}?{
return?s[len(s)-1]
}
func?(s?*Stack)?Pop()?{
*s?=?(*s)[:
len(*s)-1]
func?(s?*Stack)?Push(value?interface{})?{
*s?=?
append(*s,?value)
但是,这里存在一个问题:每当你 Peek 项时,都必须使用类型断言将其从 interface{} 转换为你需要的类型.如果你的堆栈是 *MyObject 的堆栈,则意味着很多 s.Peek().(*MyObject)这样的代码.这不仅让人眼花缭乱,而且还可能引发错误.比如忘记 * 怎么办?或者如果您输入错误的类型怎么办?s.Push(MyObject{})+ 可以顺利编译,而且你可能不会发现到自己的错误,直到它影响到你的整个服务为止.
通常,使用 interface{} 是相对危险的.使用更多受限制的类型总是更安全,因为可以在编译时而不是运行时发现问题.
泛型通过允许类型具有类型参数来解决此问题:
type?Stack(type?T)?[]Tfunc?(s?Stack(T))?Peek()?T?{
func?(s?*Stack(T))?Pop()?{
func?(s?*Stack(T))?Push(value?T)?{
这会向 Stack 添加一个类型参数,从而完全不需要 interface{}.现在,当你使用 Peek() 时,返回的值已经是原始类型,并且没有机会返回错误的值类型.这种方式更安全,更容易使用.(译注:就是看起来更丑陋,^-^)
此外,泛型代码通常更易于编译器优化,从而获得更好的性能(以二进制大小为代价).如果我们对上面的非泛型代码和泛型代码进行基准测试,我们可以看到区别:
type?MyObject?struct?{
X?
int
var?sink?MyObjectfunc?BenchmarkGo1(b?*testing.B)?{
for?i?:=?0;?i?b.N;?i++?{
var?s?Stack
s.Push(MyObject{})
s.Pop()
sink?=?s.Peek().(MyObject)
var?s?Stack(MyObject)
sink?=?s.Peek()
结果:
在这种情况下,我们分配更少的内存,同时泛型的速度是非泛型的两倍.
合约(Contracts)
上面的堆栈示例适用于任何类型.但是,在许多情况下,你需要编写仅适用于具有某些特征的类型的代码.例如,你可能希望堆栈要求类型实现 String() 函数
go1.10\src\sync\map.go
entry分为三种情况:
从read中读取key,如果key存在就tryStore.
注意这里开始需要加锁,因为需要操作dirty.
条目在read中,首先取消标记,然后将条目保存到dirty里.(因为标记的数据不在dirty里)
最后原子保存value到条目里面,这里注意read和dirty都有条目.
最后提醒一下大家Store:
这里可以看到dirty保存了数据的修改,除非可以直接原子更新read,继续保持read clean.
有了之前的经验,可以猜测下load流程:
与猜测的 区别 :
由于数据保存两份,所以删除考虑:
先看第二种情况.加锁直接删除dirty数据.思考下貌似没什么问题,本身就是脏数据.
第一种和第三种情况唯一的区别就是条目是否被标记.标记代表删除,所以直接返回.否则CAS操作置为nil.这里总感觉少点什么,因为条目其实还是存在的,虽然指针nil.
看了一圈貌似没找到标记的逻辑,因为删除只是将他变成nil.
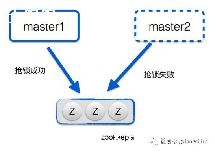
之前以为这个逻辑就是简单的将为标记的条目拷贝给dirty,现在看来大有文章.
p == nil,说明条目已经被delete了,CAS将他置为标记删除.然后这个条目就不会保存在dirty里面.
这里其实就跟miss逻辑串起来了,因为miss达到阈值之后,dirty会全量变成read,也就是说标记删除在这一步最终删除.这个还是很巧妙的.
真正的删除逻辑:
很绕....
go语言适用的领域有:
Go语言主要用作服务器端开发,其定位是用来开发"大型软件"的,适合于很多程序员一起开发大型软件,并且开发周期长,支持云计算的网络服务.
Go语言能够让程序员快速开发,并且在软件不断的增长过程中,它能让程序员更容易地进行维护和修改.它融合了传统编译型语言的高效性和脚本语言的易用性和富于表达性.
PostgreSQL和MySQL比较,它更加庞大一点,因为它是用来替代Oracle而设计的.所以在企业应用中采用PostgreSQL是一个明智的选择.
现在MySQL被Oracle收购之后,有传闻Oracle正在逐步的封闭MySQL,,鉴于此,将来我们也许会选择PostgreSQL而不是MySQL作为项目的后端数据库.
①.、驱动
Go实现的支持PostgreSQL的驱动也很多,因为国外很多人在开发中使用了这个数据库.
支持database/sql驱动,纯Go写的
在下面的示例中我采用了第一个驱动,因为它目前使用的人最多,在github上也比较活跃.
数据库建表语句:
复制代码
CREATE TABLE userinfo
(
uid serial NOT NULL,
username character varying(100) NOT NULL,
Created date,
CONSTRAINT userinfo_pkey PRIMARY KEY (uid)
)
WITH (OIDS=FALSE);
CREATE TABLE userdeatail
uid integer,
intro character varying(100),
profile character varying(100)
WITH(OIDS=FALSE);
看下面这个Go如何操作数据库表数据:增删改查
package main
import (
"database/sql"
"fmt"
_ "github.com/bmizerany/pq"
func main() {
db, err := sql.Open("postgres", "user=astaxie password=astaxie dbname=test sslmode=disable")
checkErr(err)
//插入数据
//pg不支持这个函数,因为他没有类似MySQL的自增ID
id, err := res.LastInsertId()
fmt.Println(id)
//更新数据
res, err = stmt.Exec("astaxieupdate", 1)
affect, err := res.RowsAffected()
fmt.Println(affect)
//查询数据
rows, err := db.Query("SELECT * FROM userinfo")
for rows.Next() {
var uid int
var username string
var department string
var created string
err = rows.Scan(uid, username, department, created)
fmt.Println(uid)
fmt.Println(username)
fmt.Println(department)
fmt.Println(created)
//删除数据
stmt, err = db.Prepare("delete from userinfo where uid=$1")
res, err = stmt.Exec(1)
affect, err = res.RowsAffected()
db.Close()
func checkErr(err error) {
if err != nil {
panic(err)
还有pg不支持LastInsertId函数,因为PostgreSQL内部没有实现类似MySQL的自增ID返回,其他的代码几乎是一模一样
①.、服务器编程:以前你如果使用C或者C++做的那些事情,用Go来做很合适,例如处理日志、数据打包、虚拟机处理、文件系统等.
自1.0版发布以来,go语言引起了众多开发者的关注,并得到了广泛的应用.go语言简单、高效、并发的特点吸引了许多传统的语言开发人员,其数量也在不断增加.
使用 Go 语言开发的开源项目非常多.早期的 Go 语言开源项目只是通过 Go 语言与传统项目进行C语言库绑定实现,例如 Qt、Sqlite 等.
后期的很多项目都使用 Go 语言进行重新原生实现,这个过程相对于其他语言要简单一些,这也促成了大量使用 Go 语言原生开发项目的出现.
以上就是土嘎嘎小编为大家整理的go语言项目数据更新相关主题介绍,如果您觉得小编更新的文章只要能对粉丝们有用,就是我们最大的鼓励和动力,不要忘记讲本站分享给您身边的朋友哦!!