

由于传统的 mysql 数据库并不擅长海量数据的检索,当数据量到达一定规模时(估算单表两千万左右),查询和插入的耗时会明显增加.同样,当需要对这些数据进行模糊查询或是数据分析时,MySQL作为事务型关系数据库很难提供良好的性能支持.使用适合的数据库来实现模糊查询是解决这个问题的关键.
但是,切换数据库会迎来两个问题,一是已有的服务对现在的 MySQL 重度依赖,二是 MySQL 的事务能力和软件生态仍然不可替代,直接迁移数据库的成本过大.我们综合考虑了下,决定同时使用多个数据库的方案,不同的数据库应用于不同的使用场景.而在支持模糊查询功能的数据库中,elasticsearch 自然是首选的查询数据库.这样后续对业务需求的切换也会非常灵活.
那具体该如何实现呢?在又拍云以往的项目中,也有遇到相似的问题.之前采用的方法是在业务中编写代码,然后同步到 elasticsearch 中.具体是这样实施的:每个系统编写特定的代码,修改 MySQL 数据库后,再将更新的数据直接推送到需要同步的数据库中,或推送到队列由消费程序来写入到数据库中.
但这个方案有一些明显的缺点:
系统高耦合,侵入式代码,使得业务逻辑复杂度增加
方案不通用,每一套同步都需要额外定制,不仅增加业务处理时间,还会提升软件复复杂度
工作量和复杂度增加
在业务中编写同步方案,虽然在项目早期比较方便,但随着数据量和系统的发展壮大,往往最后会成为业务的大痛点.
既然以往的方案有明显的缺点,那我们如何来解决它呢?优秀的解决方案往往是 "通过架构来解决问题",那么能不能通过架构的思想来解决问题呢?
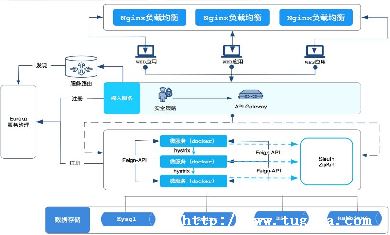
答案是可以的.我们可以将程序伪装成 "从数据库",主库的增量变化会传递到从库,那这个伪装成 "从数据库" 的程序就能实时获取到数据变化,然后将增量的变化推送到消息队列 MQ,后续消费者消耗 MQ 的数据,然后经过处理之后再推送到各自需要的数据库.
这个架构的核心是通过监听 MySQL 的 binlog 来同步增量数据,通过基于 query 的查询旧表来同步旧数据,这就是本文要讲的一种异构数据库同步的实践.
经过深度的调研,成功得到了一套异构数据库同步方案,并且成功将公司生产环境下的 robin/logs 的表同步到了 elasticsearch 上.
首先对 MySQL 开启 binlog,但是由于 maxwell 需要的 binlog_format=row 原本的生产环境的数据库不宜修改.这里请教了海杨前辈,他提供了"从库联级"的思路,在从库中监听 binlog 绕过了操作生产环境重启主库的操作,大大降低了系统风险.
后续操作比较顺利,启动 maxwell 监听从库变化,然后将增量变化推送到 kafka ,最后配置 logstash 消费 kafka中的数据变化事件信息,将结果推送到 elasticsearch.配置 logstash需要结合表结构,这是整套方案实施的重点.
这套方案使用到了kafka、maxwell、logstash、elasticsearch.其中 elasticsearch 与 kafka已经在生产环境中有部署,所以无需单独部署维护.而 logstash 与 maxwell 只需要修改配置文件和启动命令即可快速上线.整套方案的意义不仅在于成本低,而且可以大规模使用,公司内有 MySQL 同步到其它数据库的需求时,都可以上任.
使用该方案同步和业务实现同步的对比

此时此刻呢,我们来看看具体是如何实现的.
本方案无需编写额外代码,非侵入式的,实现 MySQL 数据与 elasticsearch 数据库的同步.

下列是本次方案需要使用所有的组件:
MySQL
Kafka
Maxwell(监听 binlog)
Logstash(将数据同步给 elasticsearch)
Elasticsearch
首先我们需要增加一个数据库只读的用户,如果已有的可以跳过.
-- 创建一个 用户名为 maxwell 密码为 xxxxxx 的用户
CREATE USER 'maxwell'@'%' IDENTIFIED BY 'XXXXXX';
GRANT ALL ON maxwell.* TO 'maxwell'@'localhost';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
开启数据库的 binlog,修改 mysql 配置文件,注意 maxwell 需要的 binlog 格式必须是row.
# /etc/mysql/my.cnf
[mysqld]
# maxwell 需要的 binlog 格式必须是 row
binlog_format=row
# 指定 server_id 此配置关系到主从同步需要按情况设置,
# 由于此mysql没有开启主从同步,这边默认设置为 1
server_id=1
# logbin 输出的文件名, 按需配置
log-bin=master
重启 MySQL 并查看配置是否生效:
sudo systemctl restart mysqld
select @@log_bin;
-- 正确结果是 1
select @@binlog_format;
-- 正确结果是 ROW
如果要监听的数据库开启了主从同步,并且不是主数据库,需要再从数据库开启 binlog 联级同步.
# /etc/my.cnf
log_slave_updates = 1
需要被同步到 elasticsearch 的表结构.
-- robin.logs
show create table robin.logs;
-- 表结构
CREATE TABLE +logs+ (
+id+ int(11) unsigned NOT NULL AUTO_INCREMENT,
+content+ text NOT NULL,
+user_id+ int(11) NOT NULL,
+status+ enum('SUCCESS','FAILED','PROCESSING') NOT NULL,
+type+ varchar(20) DEFAULT '',
+meta+ text,
+created_at+ bigint(15) NOT NULL,
+idx_host+ varchar(255) DEFAULT '',
+idx_domain_id+ int(11) unsigned DEFAULT NULL,
+idx_record_value+ varchar(255) DEFAULT '',
+idx_record_opt+ enum('DELETE','ENABLED','DISABLED') DEFAULT NULL,
+idx_orig_record_value+ varchar(255) DEFAULT '',
PRIMARY KEY (+id+),
KEY +created_at+ (+created_at+)
) ENGINE=InnoDB AUTO_INCREMENT=8170697 DEFAULT CHARSET=utf8
wget https://github.com/zendesk/maxwell/releases/download/v1.39.2/maxwell-1.39.2.tar.gz
tar zxvf maxwell-1.39.2.tar.gz **** cd maxwell-1.39.2
maxwell 使用了两个数据库:
一个是需要被监听binlog的数据库(只需要读权限)
另一个是记录maxwell服务状态的数据库,当前这两个数据库可以是同一个
重要参数说明:
host 需要监听binlog的数据库地址
port 需要监听binlog的数据库端口
user 需要监听binlog的数据库用户名
password 需要监听binlog的密码
replication_host 记录maxwell服务的数据库地址
replication_port 记录maxwell服务的数据库端口
replication_user 记录maxwell服务的数据库用户名
filter 用于监听binlog数据时过滤不需要的数据库数据或指定需要的数据库
producer 将监听到的增量变化数据提交给的消费者 (如 stdout、kafka)
kafka.bootstrap.servers kafka 服务地址
kafka_version kafka 版本
kafka_topic 推送到kafka的主题
启动 maxwell
注意,如果 kafka 配置了禁止自动创建主题,需要先自行在 kafka 上创建主题,kafka_version 需要根据情况指定, 此次使用了两张不同的库
./bin/maxwell
--kafka_topic=maxwell-robinlogs --kafka_version=0.9.0.1
Logstash 包中已经包含了 openjdk,无需额外安装.
wget https://artifacts.elastic.co/downloads/logstash/logstash-⑧⑤0-linux-x86_6④tar.gz
tar zxvf logstash-⑧⑤0-linux-x86_6④tar.gz
删除不需要的配置文件.
rm config/logstash.yml
修改 logstash 配置文件,此处语法参考官方文档(https://www.elastic.co/guide/en/logstash/current/input-plugins.html) .
# config/logstash-sample.conf
input {
kafka {
codec => rubydebug
}
}
执行程序:
# 测试配置文件*
bin/logstash -f config/logstash-sample.conf --config.test_and_exit
# 启动*
bin/logstash -f config/logstash-sample.conf --config.reload.automatic
完成启动后,后续的增量数据 maxwell 会自动推送给 logstash 最终推送到 elasticsearch ,而之前的旧数据可以通过 maxwell 的 bootstrap 来同步,往下面表中插入一条任务,那么 maxwell 会自动将所有符合条件的 where_clause 的数据推送更新.
INSERT INTO maxwell.bootstrap
( 'robin', 'logs', 'id > 1', 'maxwell' );
后续可以在 elasticsearch 检测数据是否同步完成,可以先查看数量是否一致,然后抽样对比详细数据.
# 检测 elasticsearch 中的数据量
GET robin_logs/robin_logs/_count