

���д�˸�kafka�Ľ�����Ϣ�Ĺ���,��Ҫʹ�ûص������յ�����Ϣ.
һ���ǻ����Ļص�,һ����ʹ�ýӿڹ���ʵ�ֻص�,�Խӿ��Ǹ��ܺõ�ѧϰ.
�������ص�
kafka�Ľ�����Ϣ��.�յ���Ϣ��,ʹ�ô����Onmessage���д���.
����kafka������Ϣ�ĵ�Ԫ,���ڵ��÷�д�ûص�
�ڵ��÷�ʵ�ֻص���Ҫִ�еķ���
�о�����ʹ�û����ص���Լ�,�ӿھ͵�ѧϰ��.
�������Ľӿڵķ���Ҫ��д����λ�˺þ÷��ָ����ŵ�����.
��10������£�
AKHQ
Kowl
Kafdrop
UI for Apache Kafka
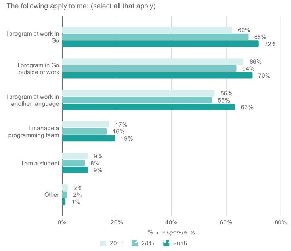
Lenses
CMAK
Confluent CC
Conduktor
LogiKM
kafka-console-ui
������������ַ���Դ�,����ֱ��ȥ������,����Ҳ�����ظ�˵��.
���ǵ��ܶ�ͬѧ���ܴ�github̫��,����������ػ�����Ϣ����һ��,����ҿ����˽�,����ѡ��.
����
AKHQ (previously known as KafkaHQ)
�������ԣ������javaΪ��
Kowl - A Web UI for Apache Kafka
p.s. github�������Ķ�ͼ�����ϴ�ʧ��,��ֻ��һ����̬�Ľ�ͼ��,������Դ�github,���������ĵ�ֱַ�ӿ���.
����������������й��ܶ������,�в��ֹ�������ҵ����У�
�������ԣ������goΪ��
Kafdrop �C Kafka Web UI
�������ԣ������javaΪ��
Ҫ��jdk11����߰汾
UI for Apache Kafka �C Free Web UI for Apache Kafka
Lenses.io
Apache Kafka �� Kubernetes ��ʵʱӦ�ó�������ݲ��� #DataOps �Ż�.
CMAK (Cluster Manager for Apache Kafka, previously known as Kafka Manager)
�����غܶ�ͬѧ��֪��,ԭ�������־���kafka manager.
�������ԣ������scalaΪ��
Confluent Inc.
Apache
�����ҵ�һ��������ͼƬ,�պϿ��ɣ�
�εο�Դ��һվʽApache Kafka��Ⱥָ��������ά�ܿ�ƽ̨.
Ҳ�Ƿ����������ҵ���.
�������ֱ�ӿ�github˵����,��������,��������,��ص�����Ҳ����.
��Ҳ���˽�����,�и�����Ⱥ�ĸ���,���ڹ�ģ�Ƚϴ��kafka��Ⱥ��������ͦ�õ�,����,����Ƚϸ߶˵����Զ��Dz���Դ��,������ҵ�������.
kafka-console-ui(kafka���ӻ�����ƽ̨)
һ����������kafka���ӻ�����ƽ̨,��װ���ÿ�ݡ�������.�������е�����rocketmq-console.
���Ȩ����"��������,�����Կ�"��,һ��С����,����սӴ�kafka��ͬѧ��������С�ͼ�Ⱥ,���Ҹ������õ�,���Կ���һ��.
�������ԣ������java��scalaΪ��
�ο����ӣ�
��һ�Σ�Kafka����
�� Ϊʲô��Ҫ�õ���Ϣ����
�첽���Ա���ǰ�Ĵ���ͬ����ʽ��˵,������ͬһʱ�������������,���Ч�ʣ�
��������̫�ߵij���,�������Ҫ��ͬһ�����ݽ��в������ѵ�ʱ��,�ᵼ��һ������Ĵ�����Ϊ��һ����������ݵIJ�����ü��临��.
���壺������ͻ����������ʱ��,��Ϣ���п����Ȱ�������Ϣ��������,����ֱ��������ϵͳ����,ϵͳ����ʼ����һ��ƽ�ȵ�����ȥ������Щ��Ϣ.
��û�о��Եĺû�,������������ѡ��,������ͳ���һ�������ܽ�ĵ���ȱ��,�ɼ�ԭ��
kafka���ŵ㣺
kafka��ȱ�㣺
�����кܶ�kafka�����̳�,����Ͳ��ٴ,��չʾһ��kafka�Ļ���,��kubernetes�Ͻ��еĴ,����Ҫ��˽��,���Է�yaml�ļ�
github.com/Shopify/sarama // kafka��Ҫ�Ŀ�*github.com/bsm/sarama-cluster // kafka������
����������
������
ͬ��������
�첽������
ͬ��������ӡ��
���Ѵ�ӡ��
�첽������ӡ��
����Ŀ�����ƶ��˵�����ͳ��,��Ŀ��ַ�� .��Դ������ͳ��countly���ĺܺ�,���ǻ�����Ѱ�Ĺ���ʵ�ڲ�����,�������Ҿ;�����go������д�������Ŀ,һ��������ʵ����ѧϰgo����,����Ҳ���Կ������������Ŀ�Դƽ̨.����Ŀ���ڿ�����,��ӭ����Ȥ��gopherһ�����.
���ݴ洢����ʹ�õ���mongodb.��������ͳ��ҵ�����漰�������Լ��ϸ��һ���Գ���,����mongodb���Զ���Ƭ���ܿ���֧�Žϴ��������.ʹ�ô����ݵĴ洢����Ļ���̫��������.������ѡ��mongodb.
��̨չʾ����Vue-Admin-Template����,����ǰ������������������«��ư,ϣ����ǰ�˴�����������̨ҳ��,��Ŀ��ַ:
�����һ���̨ҳ���Ч��ͼ��
GoAnalytics�ǻ���goʵ�ֵ�һ������ͳ��ƽ̨,����ͳ���ƶ��˵�����ָ��,���������������û���������Ծ�û��������ָ�����.ǰ������չʾ��Ŀ�� goanalytics-web .Ŀǰ���ڻ���������,��ӭ�ύ�µ������pull request.
Go�汾��Ҫ֧��module,���ؿ�������
cmd/goanalytics_kafka �� goanalytics_rmq �Ƿֱ���� kafka �� rocketmq �ķ������Ĺ����������ݷ���
��Ŀ�ṹ
������ README.md
������ api
�� ������ authentication �û���֤������API
�� ������ middlewares GIN ��
�� ������ router API route
������ cmd
�� ������ account ����admin�˺�����
�� ������ analytic_local ��������Ϣϵͳ��goanalytics
�� ������ goanalytics_kafka ����kafak��goanalytics
�� ������ goanalytics_rmq ����rocketmq��goanalytics
�� ������ test_data ���ɲ�����������
������ common
�� ������ data.go
������ conf ����
�� ������ conf.go
������ event
�� ������ codec ���ݱ����
�� ������ pubsub ��Ϣ��������
������ go.mod
������ go.sum
������ metric ���е�ͳ��ָ�������һ��ʵ��
�� ������ init.go
�� ������ user �û����ָ���ʵ��
������ schedule
�� ������ schedule.go ��ʱ�������
������ storage �洢ģ��
�� ������ counter.go �������ӿ�
�� ������ data.go
�� ������ mongodb ����mongodbʵ�ֵĴ洢��������
������ utils
������ date.go
������ date_test.go
������ errors.go
������ key.go
Filebeat��elastic��˾beatsϵ�й����е�һ��,��Ҫ�����ռ�������־.
�ڷ������ϰ�װ��,filebeat������־Ŀ¼����ָ������־�ļ�,�ٶ�ȡ��Щ�ļ������ļ��ı仯,��ͣ�Ķ���,����ת����Щ��Ϣ�������ļ���ָ��������ˣ����磺elasticsearch,logstarsh��kafka��.
Filebeatʹ��go���Կ���,ʹ��ʱû����������,��logstash-forworder����,����ռ�ò��������̫�����Դ.
filebeat�Ĺ������̣����㿪��filebeat�����ʱ��,��������һ������̽������prospectors��ȥ�����ָ������־Ŀ¼���ļ�,����̽�����ҳ���ÿһ����־�ļ�,filebeat�����ո���̣�harvester��,ÿһ���ո���̶�ȡһ����־�ļ���������,��������Щ�µ���־���ݵ���������spooler��,��������Ἧ����Щ�¼�,���filebeat�ᷢ�ͼ��ϵ����ݵ���ָ���ĵص�.
�����ҵ�Ԥ��Ŀ���ǽ�filebeat�ռ�����־���͵�kafka,��������output��ѡ����kafka.���߿ɸ����Լ���ʹ�ó���,����output.
�����е����ý���/var/logĿ¼��������.log��β���ļ����вɼ�.
������ֻ��Ϊ���������filebeat�����������������.filebeat�ĺܶ���Ҫ�����ú����Բ�û�����֣����磺ģ��,������Ϣ��,���������Ҫ��������˽���ο��� .
��ӭ���������������ʹ�ù��̵��ĵú��ɻ�.
������Ҫ�о�һ��golang��zap��ZapKafkaWriter
WriteSyncer��Ƕ��io.Writer�ӿ�,������Sync������Sink�ӿ���Ƕ��zapcore.WriteSyncer��io.Closer�ӿڣ�ZapKafkaWriterʵ��Sink�ӿڼ�zapcore.WriteSyncer�ӿ�,��Write����ֱ�ӽ�dataͨ��kafka���ͳ�ȥ.
���Ͼ������¸�С��Ϊ���������go����kafka����������,���������С����µ�����ֻҪ�ܶԷ�˿������,�����������Ĺ����Ͷ���,��Ҫ���ǽ���վ�����������ߵ�����Ŷ����